
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Reading time: 40 minutes | Coding time: 15 minutes
In this article we will be working with Edmundson heuristic method for text summarization. Edmundson proposed the use of a subjectively weighted combination of features as opposed to traditionally used feature weights generated using a corpus. He considered the already known features (used in Luhns method) but added a few another features which we will be discussing further.
Introduction
H.P. Edmundson (1969) proposed another but simple system for text summarization which included the already known features such as:
- Position (P)
- Word frequency (F)
He considered few more features which according to him were significant in text summarization. These features were :
- Cue Words (C)
- Document structure (S)- A document structure consists of headlines , titles ,sub-titles etc.
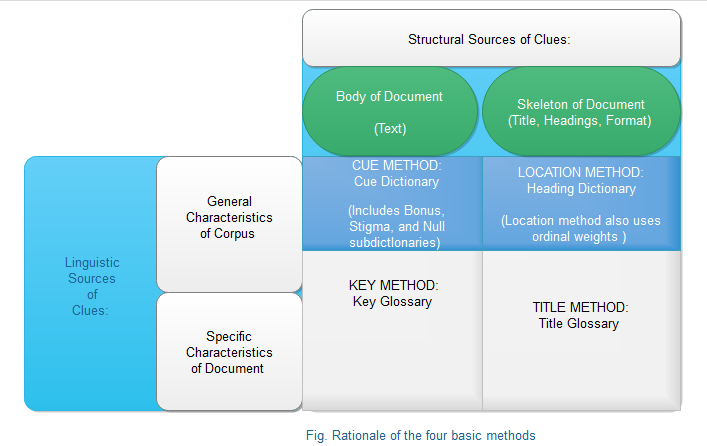
For scroing , we consider a linear combination of these 4 features:
The weight of a sentence is a linear combination of the weights obtained with the above four methods. The highest weighing sentence is included in the abstract.
Factors leading to high scoring:
- Cue words
- Title words
- Headings and sub-heading
- Less stopwords
On the basis of which there are four sub-methods for weighing the words and sentences . They are namely,
- Cue method
- Key method
- Title method
- Location method
we will be discussing each method in detail as we move forward.
The following table represents the weightage system for each sub-method for Edmundsons method:
| Cue method | Title method | Key method | Location method |
|---|---|---|---|
| Words | Titles,subtitles,headings | keyword filtering | Sentence position |
Target Documents : Technical literacture.
- Now lets discuss some methods to implement Edmundsons technique for text summarization
- These methods can be easily implemented using sumy library in python.
Naive implementation of Edmundsons method
Sumy in python offers all the implementations of Edmundson summarizer . However, it is necessary to understand the proper algorithic implementation.
#Importing required modules.
from __future__ import absolute_import
from __future__ import division, print_function, unicode_literals
from collections import defaultdict
from sumy.nlp.stemmers import null_stemmer
from sumy._summarizer import AbstractSummarizer
#The following class implements the working of Edmundons summarizer
class EdmundsonSummarizer(AbstractSummarizer):
_bonus_words = _EMPTY_SET
_stigma_words = _EMPTY_SET
_null_words = _EMPTY_SET
def __init__(self, stemmer=null_stemmer, cue_weight=1.0, key_weight=0.0,
title_weight=1.0, location_weight=1.0):
super(EdmundsonSummarizer, self).__init__(stemmer)
self._ensure_correct_weights(cue_weight, key_weight, title_weight,
location_weight)
self._cue_weight = float(cue_weight)
self._key_weight = float(key_weight)
self._title_weight = float(title_weight)
self._location_weight = float(location_weight)
We need to ensure that the weights entered must not be negative. This is done by following in-built function in Edmundson summarizer.
def _ensure_correct_weights(self, *weights):
for w in weights:
if w < 0.0:
raise ValueError("Negative wights are not allowed.")
After the above processing, Edmundson method checks for bonus words,stigma words and null words and maps them to their functions. Following the above steps "call()" is present which creates the instances of all types of methods of Edmundon summarizer.
def __call__(self, document, sentences_count):
ratings = defaultdict(int)
if self._cue_weight > 0.0:
method = self._build_cue_method_instance()
ratings = self._update_ratings(ratings, method.rate_sentences(document))
if self._key_weight > 0.0:
method = self._build_key_method_instance()
ratings = self._update_ratings(ratings, method.rate_sentences(document))
if self._title_weight > 0.0:
method = self._build_title_method_instance()
ratings = self._update_ratings(ratings, method.rate_sentences(document))
if self._location_weight > 0.0:
method = self._build_location_method_instance()
ratings = self._update_ratings(ratings, method.rate_sentences(document))
return self._get_best_sentences(document.sentences, sentences_count, ratings)
It is important to update the ratings i.e. scores for each sentence in order to ensure that the same sentence is not repeated again.
def _update_ratings(self, ratings, new_ratings):
assert len(ratings) == 0 or len(ratings) == len(new_ratings)
for sentence, rating in new_ratings.items():
ratings[sentence] += rating
return ratings
After updating we define the method instances for each i.e. Cue method,Title method,Location method and Key method. Here we have defined a cue method instance.
# Defining a cue method
def cue_method(self, document, sentences_count, bunus_word_value=1, stigma_word_value=1):
summarization_method = self._build_cue_method_instance()
return summarization_method(document, sentences_count, bunus_word_value,
stigma_word_value)
#Building a cue method instance
def _build_cue_method_instance(self):
self.__check_bonus_words()
self.__check_stigma_words()
return EdmundsonCueMethod(self._stemmer, self._bonus_words, self._stigma_words)
#For key method
def key_method(self, document, sentences_count, weight=0.5):
summarization_method = self._build_key_method_instance()
return summarization_method(document, sentences_count, weight)
def _build_key_method_instance(self):
self.__check_bonus_words()
return EdmundsonKeyMethod(self._stemmer, self._bonus_words)
### And so on for title and location method.
In the end we ensure that proper values are passed to the stigma , null and bonus words. If not,a ValueError is raised.
def __check_bonus_words(self):
if not self._bonus_words:
raise ValueError("Set of bonus words is empty. Please set attribute 'bonus_words' with collection of words.")
def __check_stigma_words(self):
if not self._stigma_words:
raise ValueError("Set of stigma words is empty. Please set attribute 'stigma_words' with collection of words.")
def __check_null_words(self):
if not self._null_words:
raise ValueError("Set of null words is empty. Please set attribute 'null_words' with collection of words.")
Cue method
These are the key words that are manually selected and are highly correlated with the importance of sentences. This method considers that the relevance of sentences is majorly affected by the emphatic words e.g. “Significant”, “Greatest”, Impossible”, “Hardly” . Cue words are further divided into following three types:
- Bonus words
These are the words pointing towards the important sentences. These may include superlatives ,adverbs etc. - Stigma words
These are the words that have negative addect on the sentence importance. It includes anaphoric expressions, belittling expressions, etc.(We may expect the machine to treat them important but they are not really.) - Null words
These aare the neutral or irrelevant words to the importance of sentences. These words are much like stopwords.
Here the weight of bonus words , stigma words and null words would be considered each.
Naive implementation
#Creating a fucntion to implement cue method
def test_mixed_cue_key():
document = build_document_from_string("""
### Your document
""")
summarizer = EdmundsonSummarizer(cue_weight=1, key_weight=1, title_weight=0, location_weight=0)
summarizer.bonus_words = (" # Enter list of bonus words here")
summarizer.stigma_words = (" # Enter list of stigma words here ")
summarizer.null_words = (" # Enter list of null words here ")
sentences = summarizer(document, 2)
All the required packages are available in sumy library of python.
Key method
This method is basically based on Luhns method i.e. mostly on the frequency. It simply means that the high-frequency content words are more relevant to the document than the others. Although the algorithm differs from that of Luhns Method.
The Key method is different from Luhns method in following algorithmic manner:
- Create a key list of all key words in the document.
- Assign key weight to each key word in this list .
- If word not in key list, weight=0.
- Relative Positions are not used(Luhn).
Naive implementation
#Creating function to implement key method
def test_key():
document = build_document( #build a document or use a a document here
)
summarizer = EdmundsonSummarizer()
summarizer.bonus_words = (" # Enter list of bonus words here")
summarizer.stigma_words = (" # Enter list of stigma words here ")
summarizer.null_words = (" # Enter list of null words here ")
sentences = summarizer.key_method(document, 1)
Title method
Title is often used to emphasis the subject of our succeeding document , paragraph etc. When the author partitions the body of the document into major sections the document in summarized using various headings . Following steps implements the title method:
- Create a title list containing null-words,headings and sub-titles.
- Assign weight>0, if the words appear in this list.
- Assign Weighttitle words>Weightheading words.
Again the weight of bonus words , stigma words and null words would be considered each.
Naive implementation
#Creating a function to implement title method
def test_title_method():
document = build_document_from_string("""
### Your document
""")
summarizer = EdmundsonSummarizer()
summarizer.bonus_words = (" # Enter list of bonus words here")
summarizer.stigma_words = (" # Enter list of stigma words here ")
summarizer.null_words = (" # Enter list of null words here ")
sentences = summarizer.title_method(document, 1)
Location Method
Location method is also based on skeletons of documents, i.e. headings and format. The Location method is based on:
(1) sentences occurring under certain headings are positively relevant
(2) topic sentences tend to occur very early or very late in a document and its paragraphs.
For these sentences , location characteristics for each is tested against the selection ratio and the calculated weights are assigned according to their occurrence and position in document. Heading dictionary of selected words is used to store the specific parts e.g. "Introduction," "Purpose,"Conclusions". The final Location weight for each sentence is given by the sum of its heading and its Ordinal weights respectively.
Where O1 and O2 are the weights of sentences of first para and last para respectively and O3 and O4 are the weights of first and last para respectively.
Naive Implementation
#Creating a function to implement location method
def test_location_method():
document = build_document_from_string("""
# Your document
""")
summarizer = EdmundsonSummarizer()
summarizer.null_words = (" #list your null words here. ")
sentences = summarizer.location_method(document, 4, w_p1=0, w_p2=0)
Unlike the other methods in Location method we consider a complete sentence as a feature but not indivisual words.
Quick implementation of Edmundsons method
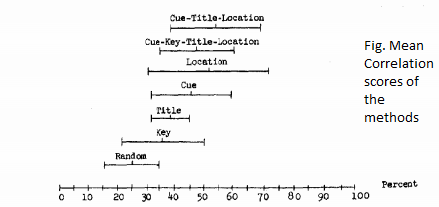
Edmundson used the linear combination of all these methods.
Other than the naive implementation of each method, we can also directly and easily generate a summary using Edmundsons method.
- Importing the required packages from sumy.
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.edmundson import EdmundsonSummarizer
- Creating our test document
doc="""OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.
OpenGenus is all about positivity and innovation.
Over 1000 people have contributed to our missions and joined our family. We have been sponsored by three great companies namely Discourse, GitHub and DigitalOcean. We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life.
"""
print(doc)
Output-
OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.
OpenGenus is all about positivity and innovation.
Over 1000 people have contributed to our missions and joined our family. We have been sponsored by three great companies namely Discourse, GitHub and DigitalOcean. We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life.
- Parsing and calling the required functions.
# For String type documents
parser=PlaintextParser.from_string(doc,Tokenizer("english"))
summarizer1 = EdmundsonSummarizer(cue_weight=1, key_weight=1, title_weight=0, location_weight=0)
summarizer1.bonus_words = ( "Discourse", "GitHub","internship")
summarizer1.stigma_words = ("positivity", "innovation","organisation","generation")
summary = summarizer1(parser.document,2)
- Printing the generated summary.
for sentence in summary:
print(sentence)
print("\n")
Output-
We have been sponsored by three great companies namely Discourse, GitHub and DigitalOcean.
We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life.
Thus we have generated the required summary using direct implementation of Edmundsons method.
Conclusion
From the above article we learned about the Luhns Heuristic method for text summarization. In the end , following conclusions can be drawn :
- Criteria for sentence selection:
- Word frequency
- Cue phrases,
- Title and heading words
- Sentence location
- Type of document: single
- Corpus suited: Technical articles (like OpenGenus IQ articles) and documents
- Advantages : Foundation for many existing extractive summarization methods.
- Disadvantages : Redundancy in the summary and computationally complex.
Further Reading
- New Methods in Automatic Extracting (PDF/Paper) by H.P. Edmundson