
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Reading time: 20 minutes
The winner of the ILSVRC 2014 competition was GoogleNet from Google. It achieved a top-5 error rate of 6.67%! This was very close to human level performance which the organisers of the challenge were now forced to evaluate. As it turns out, this was actually rather hard to do and required some human training in order to beat GoogLeNets accuracy.
GoogleNet has 22 layer, and almost 12x less parameters (So faster and less then Alexnet and much more accurate).
Their idea was to make a model that also could be used on a smart-phone (Keep calculation budget around 1.5 billion multiply-adds on prediction
Inception layer
The idea of the inception layer is to cover a bigger area, but also keep a fine resolution for small information on the images. So the idea is to convolve in parallel different sizes from the most accurate detailing (1x1) to a bigger one (5x5).
The idea is that a series of gabor filters with different sizes, will handle better multiple objects scales. With the advantage that all filters on the inception layer are learnable.
The most straightforward way to improve performance on deep learning is to use more layers and more data, googleNet use 9 inception modules. The problem is that more parameters also means that your model is more prone to overfit. So to avoid a parameter explosion on the inception layers, all bottleneck techniques are exploited.
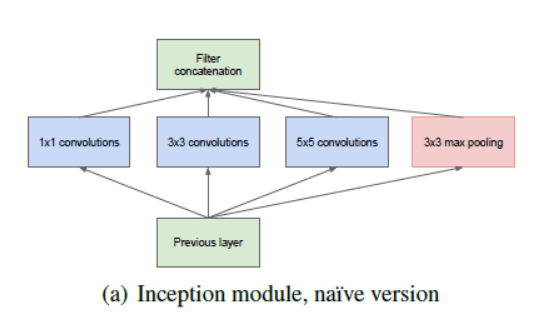
As seen above, it is a drastic change from the sequential architectures which we saw previously. In a single layer, multiple types of “feature extractors” are present. This indirectly helps the network perform better, as the network at training itself has many options to choose from when solving the task. It can either choose to convolve the input, or to pool it directly.
The final architecture contains multiple of these inception modules stacked one over the other. Even the training is slightly different in GoogleNet, as most of the topmost layers have their own output layer. This nuance helps the model converge faster, as there is a joint training as well as parallel training for the layers itself.
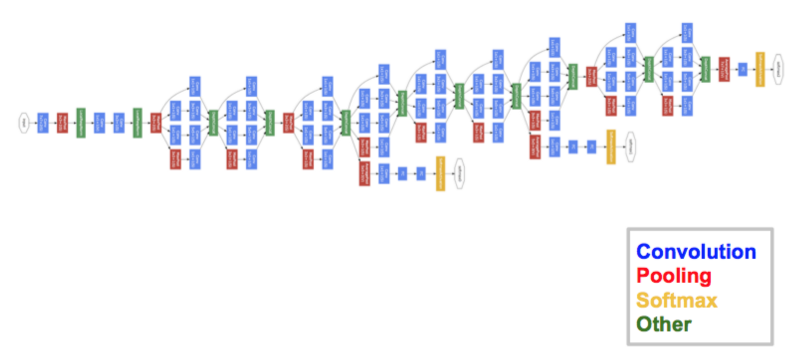
Advantages of GoogleNet
- GoogleNet trains faster than VGG.
- Size of a pre-trained GoogleNet is comparatively smaller than VGG. A VGG model can have > 500 MBs, whereas GoogleNet has a size of only 96 MB.
GoogleNet does not have an immediate disadvantage per se, but further changes in the architecture are proposed, which make the model perform better. One such change is termed as an Xception Network, in which the limit of divergence of inception module (4 in GoogleNet as we saw in the image above) are increased. It can now theoretically be infinite (hence called extreme inception!)