
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article, we will inspect a CodeForces profile’s site structure and scrape the required data. We will use this profile as an example. We will use the Beautiful Soup and Requests libraries of python for the purpose.
Scraping information is used to extract useful information from various websites. Sometimes, we need to use the content from websites but manually collecting the data can be both laborious and time-consuming.
Other uses of Web Scrapping are:
- Search engine bots crawling a site, analyzing its content, and then rank it.
- Price comparison sites deploying bots to auto-fetch prices and product descriptions for allied seller websites.
- Market research companies using scrapers to pull data from forums and social media (e.g., for sentiment analysis).
Note: While scraping data from a web site we need to care for a few points:
1.Web scraping from websites where the data is copyright protected cannot be used in our personal websites as it leads to copyright infringement.
2. Trespass to Chattel. A web scraper can violate trespass to chattel if we make the server slow or even stop because of frequent requests.
First, let us learn about Beautiful Soup
Beautiful Soup
Beautiful Soup is a Python library designed for quick turnaround projects like screen-scraping.
Features of Beautiful Soup
- It provides a few simple methods and Pythonic idioms for navigating, searching, and modifying a parse tree
- It automatically converts incoming documents to Unicode and outgoing documents to UTF-8.
- It sits on top of popular Python parsers like lxml and html5lib, allowing you to try out different parsing strategies or trade speed for flexibility.
Requests
The Requests library is the de facto standard for making HTTP requests in Python. It abstracts the complexities of making requests behind a simple API so that you can focus on interacting with services and consuming data in your application.
Features of Requests
- It can decode content automatically
- In case of a delayed response, we can decide the time after which the request timeouts.
- It supports streaming uploads, which allow you to send large streams or files without reading them into memory.
Getting Started
Inspecting Data Source:
Before extracting the required information, we will get familiar with the site structure. Browse through the tabs and get familiar with their content.
Analysing URL syntax:
If you look carefully at the URLs, you’ll see they follow a specific syntax. This syntax helps to retrieve the HTML of different profiles using the same code. For example, the contest tab follows the syntax: https://codeforces.com/contests/with/<username>. So, for extracting data from another username, you just have to edit the URL that replaces the username, and your code extracts data from that username.
Another example can be, the blog tab which follows the following syntax: https://codeforces.com/blog/<username>.
Inspect the site:
To scrape data, you should know how the data is structured for display on the website. You will need to understand the page structure to pick what you want from the HTML response that you will collect in one of the upcoming steps.
We will use Inspect Element to understand the site’s structure. Inspect an Element is a developer tool that lets you view and edit the HTML and CSS of web content. All modern browsers come with developer tools installed. You can Google about developer tools in your browser.
Extract HTML:
We will use Python’s requests library to get the site’s HTML code into our Python script so that we can interact with it. Refer the below code to retrieve the HTML:
import requests
URL = ‘https://codeforces.com/contests/with/smeke’
page = requests.get(URL)
This code retrieves the HTML data and stores it in a Python object.
After extracting HTML, the next step is to parse it and pick the required data.
Parse and extract the data
We will use Python's Beautiful Soup library to parse the data. The data we want to extract is nested in <\div> tags with class name "data table" as shown below:
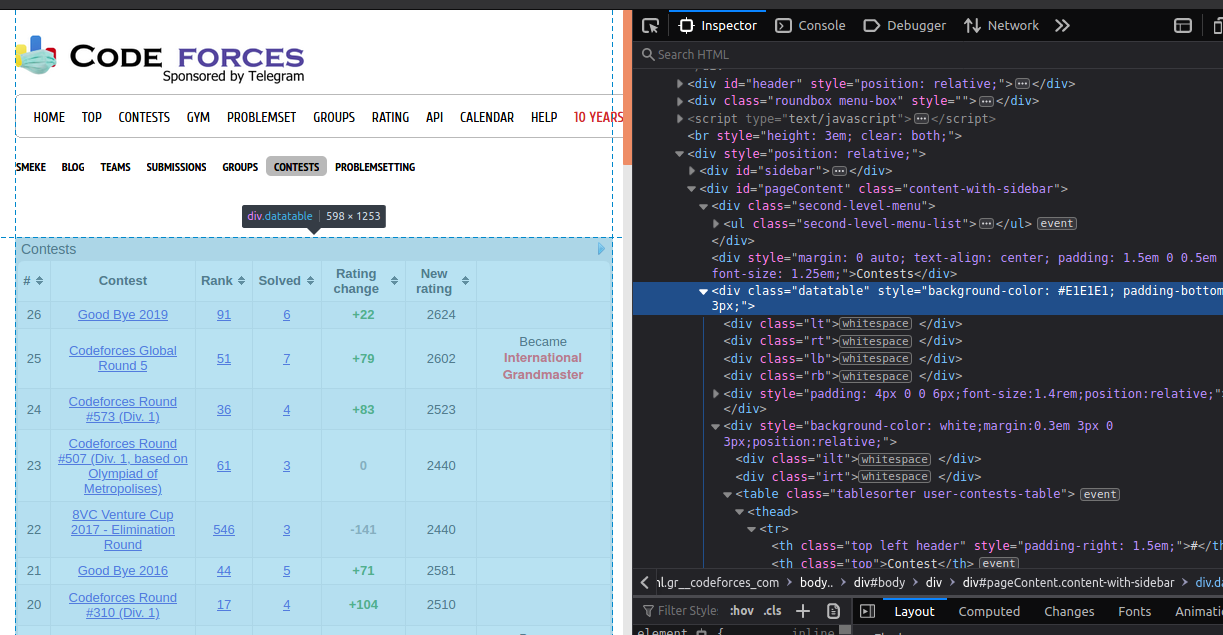
Now, we find the div tags with those respective class-names, extract the data, and store the data in a variable.
First, import the module:
from bs4 import BeautifulSoup
Next, create a Beautiful Soup object and find the data required:
soup = BeautifulSoup(contests_page.content, 'html.parser')
data = {}
table = contests_soup.find('div', 'datatable')
table_body = contests_table.find('tbody')
rows = contests_table_body.find_all('tr')
Lastly, extract the text and store it in a variable:
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
if cols:
data[int(cols[0])] = {
'Contest' : cols[1],
'Rank' : cols[2],
'Solved' : cols[3],
'Rating change' : cols[4],
'New rating' : cols[5]
}
Note: The tags are different for different data. To extract the data we need to identify the correct tag. This is also done using Inspect Element. Apart from it, some basic knowledge about tags from HTML is needed. For example, to get all the links from a web page we need to find the <a> tags. Sometimes other tags like <span>, <header> and <media> are also used.
Writing JSON to a file
Python's built-in JSON package transforms Python dict object into the serialized JSON string. We use with statement to open the file in which we want to store the data and then use json.dump to write the data object to the outfile file.
Refer to the following code:
import json
with open('contests_data.txt', 'w') as contests_outfile:
json.dump(contests_data, contests_outfile)
To get information about another user we need to change the username in the code file, in place of the given “smeke”.
In this way, with this article at OpenGenus, you have scraped user data from CodeForces website. We hope this article helped you understand how web scraping works.