Hashmap in Python using OOP Concepts
Table of Contents
- Understanding of Hashmap
- What is Hashmap?
- Hashmap and Dictionary in Python
- Implementing Hashmap Using OOP Concepts
- Hashmap's Parent Class
- Hashmap's Using List of Buckets
- Hashmap's Using Linked List with Chaining
- User Implementation
- Conclusion
Understanding of Hashmap
What is Hashmap?
A hashmap, sometimes known as a hash table, is a data structure that provides for efficient key-value pair storage, retrieval, and update. It gives you quick access to values depending on their keys.
Keys in a hashmap are unique identifiers that are used to obtain their related data. When a key-value pair is entered into a hashmap, the key is hashed to establish its storage position, which is commonly referred to as an index or a bucket. The hash function transforms the key into a numeric number that corresponds to the index in the underlying array or data structure.
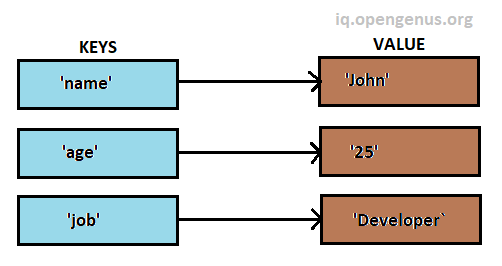
The fundamental benefit of employing a hashmap is that it may give constant-time average complexity for key-based operations like insertion, retrieval, and deletion, regardless of the quantity of the stored data. The hash function is used to compute the storage location of the key-value pairs, avoiding the need to search through the full collection.
Hashmap implementations employ collision resolution algorithms to handle and resolve issues when two keys yield the same hash value, which is known as a collision. Chaining, in which successive items with the same hash value are stored in linked lists inside the same bucket, and open addressing, in which alternate storage locations are found for future elements with clashing hash values, are two common collision resolution approaches.
Hashmap and Dictionary in Python
Because Python's built-in dictionary data structure is implemented as a hashmap, the words "hashmap" and "dictionary" are frequently used interchangeably. Both phrases relate to a collection of key-value pairs that allow for efficient element lookup, insertion, and deletion depending on their keys. However, it's worth mentioning that the term "dictionary" is more generally used in Python, whereas "hashmap" is a computer science term.
Example of dictionary in python is:
# Creating an empty dictionary
my_dict = {}
# Adding key-value pairs
my_dict["apple"] = 5
my_dict["banana"] = 2
my_dict["orange"] = 8
# Accessing values by key
print(my_dict["apple"]) # Output: 5
# Updating values
my_dict["banana"] = 3
In the above code we first create python dictionary by using {} curly bracket. Then we can add key and value as above code. We can also update and access the values by using key. Dictionary is the easiest and best way to implement hashmap in python.
Implementing Hashmap Using OOP Concepts
In Python, the most common way to implement a hashmap is to use the built-in dict class, which provides a highly optimized implementation of a hashmap. The dict class uses a hash table internally to store and retrieve key-value pairs efficiently.
However, if you want to explore alternative ways of implementing a hashmap from scratch without using the built-in dict class, therea are few methods. Some of them are:
- Using list of buckets
- Using linked list with chaining
We will use the concept of inheritance inorder to make out code clear and easy as we have parent class and two child classes to implement both methods.
Hashmap's Parent Class
The parent class consists of abstract methods of common operations on hashmap. The code is as follow.
from abc import ABC, abstractmethod
class HashMap(ABC):
@abstractmethod
def __init__(self):
pass
@abstractmethod
def insert(self, key, value):
pass
@abstractmethod
def get(self, key):
pass
@abstractmethod
def remove(self, key):
pass
@abstractmethod
def display(self):
pass
Every method in the above class operated as their name for example insert method insert new element into the hashmap. But it needs to be inherited by other classes to be implemented.
Hashmap's Using List of Buckets
The first thing to do is creating empty bucket list of given size. Then we can implement the operations by overriding the methods from parent class.
class ListofBuckets(HashMap):
def __init__(self, size):
self.size = size
self.buckets = [[] for _ in range(self.size)] # List of empty buckets
def _hash(self, key):
# Internal hash function to generate the index for a given key
return hash(key) % self.size
def insert(self, key, value):
index = self._hash(key)
bucket = self.buckets[index]
for i, (k, v) in enumerate(bucket):
if k == key:
# If the key already exists, update its value
bucket[i] = (key, value)
break
else:
# If the key doesn't exist, append a new key-value pair to the bucket
bucket.append((key, value))
def get(self, key):
index = self._hash(key)
bucket = self.buckets[index]
for k, v in bucket:
if k == key:
# Return the value if the key is found
return v
# If the key is not found, return None or raise an exception
return None
def remove(self, key):
index = self._hash(key)
bucket = self.buckets[index]
for i, (k, v) in enumerate(bucket):
if k == key:
# Remove the key-value pair from the bucket
del bucket[i]
break
def display(self):
# Display the contents of the hashmap
for i, bucket in enumerate(self.buckets):
if bucket:
print(f"Bucket {i}: {bucket}")
__init__: this function create new list of empty buckets based on a givern size from the user._hash: this method is uses build function of pythonhashto return index for a given key based on user input.insert: after getting both the key and value from the user it gets the index of the key by passing the key to_hashfunction then get the bucket corresponding to the index. After that it iterate through the backet usingenumerateuntil the particular key is found, if the key already exists update the bucket with new key and value else append the key and value into the bucket.get: first it get the index of the bucket based on the key. Then iterate through the bucket until the key found.remove: after getting the corresponding bucket based on the key, the method iterates through the bucket until it gets the key then it deletes it.display: it just iterates through the list of buckets and print the contents of each bucket.
Hashmap's Using Linked List with Chaining
A HashMap using a linked list with chaining is a common implementation of a HashMap data structure that resolves collisions by using linked lists. Here's a high-level overview of how it works:
- Define the LinkedList class: Create a class to represent the linked list. Each element in the linked list will store a key-value pair.
- Define the HashMap class: Create a class to represent the HashMap data structure, which will contain an array of linked lists and methods to interact with the HashMap.
- Choose the size of the array: Determine the size of the array based on the expected number of elements you anticipate storing in the HashMap. The size should be a prime number to reduce collisions.
- Initialize the array: Create an array of linked lists with the chosen size.
- Define the hash function: Create a hash function that takes a key and returns an index within the array. This function should distribute keys uniformly across the array.
- Insertion: When inserting a key-value pair into the HashMap, calculate the hash value of the key and find the corresponding index in the array. If the linked list at that index is empty, create a new node with the key-value pair and add it to the list. If the linked list is not empty, iterate through the list to find if the key already exists. If found, update the value; otherwise, add a new node at the end of the list.
- Retrieval: To retrieve a value associated with a given key, calculate the hash value of the key and find the corresponding index in the array. Then, iterate through the linked list at that index and return the value if the key is found. If the key is not found, return an appropriate value or indicate that the key does not exist.
- Removal: To remove a key-value pair, calculate the hash value of the key, find the corresponding index in the array, and iterate through the linked list at that index to find the key. If found, remove the corresponding node from the list.
By using a linked list for chaining, this implementation allows multiple key-value pairs with the same hash value to be stored in the same array index. Collisions are resolved by appending new nodes to the linked list, forming a chain of elements at each index.
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def insert(self, key, value):
new_node = Node(key, value)
if self.head is None:
self.head = new_node
else:
current = self.head
while current.next is not None:
current = current.next
current.next = new_node
def search(self, key):
current = self.head
while current is not None:
if current.key == key:
return current.value
current = current.next
return None
def remove(self, key):
if self.head is None:
return
if self.head.key == key:
self.head = self.head.next
return
current = self.head
prev = None
while current is not None:
if current.key == key:
prev.next = current.next
return
prev = current
current = current.next
def display(self):
current = self.head
while current is not None:
print(f"Key: {current.key}, Value: {current.value}")
current = current.next
class LinkeListHashmap(Hashmap):
def __init__(self, size):
self.size = size
self.buckets = [LinkedList() for _ in range(size)]
def _hash(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self._hash(key)
self.buckets[index].insert(key, value)
def get(self, key):
index = self._hash(key)
return self.buckets[index].search(key)
def remove(self, key):
index = self._hash(key)
self.buckets[index].remove(key)
def display(self):
for i, bucket in enumerate(self.buckets):
print(f"Bucket {i}:")
bucket.display()
print("------")
User Implementation
Here's an example of how you could use the ListofBuckets class, which inherits from the HashMap parent class, and implement your own code:
# Create an instance of the ListofBuckets class
hashmap = ListofBuckets(10)
# Insert key-value pairs
hashmap.insert("apple", 5)
hashmap.insert("banana", 2)
hashmap.insert("orange", 8)
# Get values by keys
print(hashmap.get("apple")) # Output: 5
print(hashmap.get("banana")) # Output: 2
print(hashmap.get("pear")) # Output: None
# Remove a key-value pair
hashmap.remove("banana")
# Display the hashmap
hashmap.display()
And here's an example of how you could use the LinkedListHashmap class, which inherits from the HashMap parent class, and implement your own code:
# Create an instance of the LinkedListHashMap class
hashmap = LinkedListHashMap(10)
# Insert key-value pairs
hashmap.insert("apple", 5)
hashmap.insert("banana", 2)
hashmap.insert("orange", 8)
# Get values by keys
print(hashmap.get("apple")) # Output: 5
print(hashmap.get("banana")) # Output: 2
print(hashmap.get("pear")) # Output: None
# Remove a key-value pair
hashmap.remove("banana")
# Display the hashmap
hashmap.display()
Conclusion
Using a list of buckets and linked lists is a common way to implement a HashMap, especially when dealing with collisions. This approach is known as separate chaining, where each bucket in the array contains a linked list of key-value pairs that hash to the same index.
Using a list of buckets provides a way to distribute the key-value pairs across different indices in the array, allowing for efficient retrieval and insertion. When a collision occurs (i.e., two different keys hash to the same index), separate chaining with linked lists allows multiple key-value pairs to be stored at the same index, maintaining a chain of elements.
The main advantage of this implementation is its simplicity and flexibility. It handles collisions well, ensuring that all key-value pairs are stored and retrievable. The linked list provides a dynamic structure for adding and removing elements within each bucket. Additionally, it can handle varying numbers of elements per bucket, making it suitable for a wide range of scenarios.
However, it's important to note that there are other collision resolution techniques, such as open addressing (e.g., linear probing, quadratic probing) or using balanced trees (e.g., AVL trees, red-black trees) for each bucket. The choice of implementation depends on factors such as the expected number of elements, the desired performance characteristics, and memory considerations.