Memory Management in Java: Garbage Collection algorithms
Do not miss this exclusive book on Binary Tree Problems. Get it now for free.
There are several strategies of Garbage Collection each of which is suitable fora particular use case. This is article we have explored some of the best Garbage Collection algorithms.
The Garbage Collection algorithm combinations possible are as follows:
| # | Young Generation Memory | Old Generation Memory | JVM Option |
|---|---|---|---|
| 1 | Serial | Serial | -XX:+UseSerialGC |
| 2 | Parallel Scavenge | Parallel Old | -XX:+UseParallelGC -XX:+UseParallelOldGC |
| 3 | Parallel New | CMS | -XX:+UseParNewGC -XX:+UseConcMarkSweepGC |
| 4 | G1 | G1 | -XX:+UseG1GC |
| 5 | Incremental | Incremental | -Xincgc |
| 6 | Parallel Scavenge | Serial | -XX:+UseParallelGC -XX:-UseParallelOldGC |
| 7 | Serial | CMS | -XX:-UseParNewGC -XX:+UseConcMarkSweepGC |
We will focus on the working principles of the following Garbage Collection algorithm combinations:
- Serial Garbage Collection for both the Young and Old generation memory space
- Parallel Garbage Collection for both the Young and Old generation memory space
- Parallel New for Young generation memory space and Concurrent Mark and Sweep (CMS) for the Old Generation memory space
- G1 encompasses collection of both Young and Old generation memory space
Serial Garbage Collection
Serial Garbage Collection uses:
- Mark-Copy for the Young Generation Memory Space
- Mark-Sweep-Compact for the Old Generation Memory Space
This is a single-threaded collector incapable of parallelizing the task at hand. The collector trigger stop-the-world pauses that is stopping all application threads.
This garbage collection algorithm cannot thus take advantage of multiple CPU cores commonly found in all modern hardware. Independent of the number of cores available, only one is used by the Java Virtual Machine during garbage collection.
Enabling this collector for both the Young and Old Generation is done via specifying a single parameter in the JVM startup script:
java -XX:+UseSerialGC com.OpenGenus.myClass
This Garbage collection is recommended for:
-
The JVM with a couple of hundreds megabytes heap size running in an environment with a single CPU.
-
For the majority of server-side deployments this is a rare combination.
-
Most server-side deployments are done on platforms with multiple cores, essentially meaning that by choosing Serial GC you are setting artificial limits on the use of system resources which results in idle resources.
Minor Garbage Collection Phase of Serial Garbage Collection:
{kind=link}
Full Garbage Collection Phase of Serial Garbage Collection:
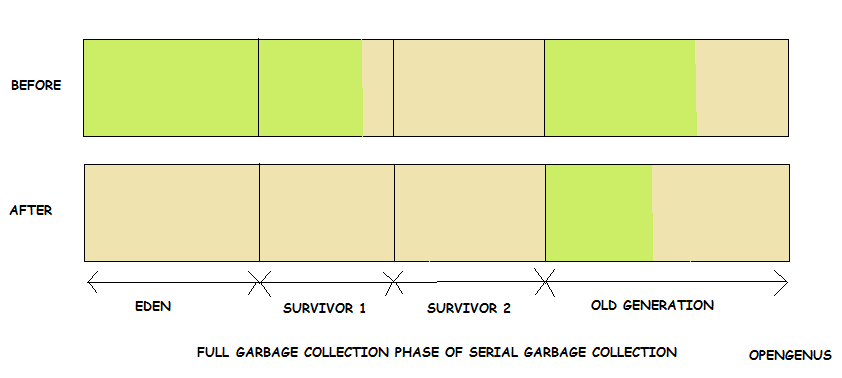{kind=link}
Parallel garbage collection
This Garbage Collectors uses:
-
Mark-copy in the Young Generation Memory space
-
Mark-sweep-compact in the Old Generation Memory space
Both Young and Old collections trigger stop-the-world events, stopping all application threads to perform garbage collection. Both collectors run marking and copying or compacting phases using multiple threads, hence the name ‘Parallel’.
The number of threads used during garbage collection is configurable via the command line parameter -XX:ParallelGCThreads=NNN .
The default value is equal to the number of cores in the host machine.
Selection of Parallel GC is done via the specification of any of the following combinations of parameters in the JVM startup script:
java -XX:+UseParallelGC com.OpenGenus.myClass
java -XX:+UseParallelOldGC com.OpenGenus.myClass
java -XX:+UseParallelGC -XX:+UseParallelOldGC com.OpenGenus.myClass
Parallel Garbage Collector is suitable on multi-core machines with the aim to increase throughput. Higher throughput is achieved due to more efficient usage of system resources.
On the other hand, as all phases of the collection have to happen without any interruptions, these collectors are still susceptible to long pauses during which your application threads are stopped. So if latency is your primary goal, you should check the next combinations of garbage collectors.
Concurrent Mark and Sweep Garbage Collection
This Garbage Collectors uses:
-
Parallel stop-the-world mark-copy algorithm in the Young Generation Memory space
-
Concurrent mark-sweep algorithm in the Old Generation Memory space
This collector was designed to avoid long pauses while collecting in the Old Generation. It achieves this by the following techniques:
- It does not compact the Old Generation but uses free-lists to manage reclaimed space.
- It does most of the job in the mark-and-sweep phases concurrently with the application.
This means that garbage collection is not explicitly stopping the application threads to perform these phases. It should be noted, however, that it still competes for CPU time with the application threads. By default, the number of threads used by this GC algorithm equals to ¼ of the number of physical cores of your machine.
This garbage collector can be chosen by specifying the following option on your command line:
java -XX:+UseConcMarkSweepGC com.OpenGenus.myClass
This combination is a good choice on multi-core machines if your primary target is latency. Decreasing the duration of an individual GC pause directly affects the way your application is perceived by end-users, giving them a feel of a more responsive application. As most of the time at least some CPU resources are consumed by the GC and not executing your application’s code, CMS generally often worse throughput than Parallel GC in CPU-bound applications.
Minor Garbage Collection Phase of Concurrent Mark and Sweep Garbage Collection:
Full Garbage Collection Phase of Concurrent Mark and Sweep Garbage Collection:
Phase 1: Initial Mark
This is one of the two stop-the-world events during CMS. The goal of this phase is to mark all the objects in the Old Generation that are either direct GC roots or are referenced from some live object in the Young Generation. The latter is important since the Old Generation is collected separately.
Phase 2: Concurrent Mark
During this phase the Garbage Collector traverses the Old Generation and marks all live objects, starting from the roots found in the previous phase of “Initial Mark”. The “Concurrent Mark” phase, as its name suggests, runs concurrently with your application and does not stop the application threads. Note that not all the live objects in the Old Generation may be marked, since the application is mutating references during the marking.
Phase 3: Concurrent Preclean
This is again a concurrent phase, running in parallel with the application threads, not stopping them. While the previous phase was running concurrently with the application, some references were changed. Whenever that happens, the JVM marks the area of the heap (called “Card”) that contains the mutated object as “dirty”
Phase 4: Concurrent Abortable Preclean
Again, a concurrent phase that is not stopping the application’s threads. This one attempts to take as much work off the shoulders of the stop-the-world Final Remark as possible. The exact duration of this phase depends on a number of factors, since it iterates doing the same thing until one of the abortion conditions (such as the number of iterations, amount of useful work done, elapsed wall clock time, etc) is met.
Phase 5: Final Remark
This is the second and last stop-the-world phase during the event. The goal of this stop-the-world phase is to finalize marking all live objects in the Old Generation. Since the previous preclean phases were concurrent, they may have been unable to keep up with the application’s mutating speeds. A stop-the-world pause is required to finish the ordeal.
After the five marking phases, all live objects in the Old Generation are marked and now garbage collector is going to reclaim all unused objects by sweeping the Old Generation:
Phase 6: Concurrent Sweep
Performed concurrently with the application, without the need for the stop-the-world pauses. The purpose of the phase is to remove unused objects and to reclaim the space occupied by them for future use.
Phase 7: Concurrent Reset
Concurrently executed phase, resetting inner data structures of the CMS algorithm and preparing them for the next cycle.
CMS garbage collector does a great job at reducing the pause durations by offloading a great deal of the work to concurrent threads that do not require the application to stop. However, it, too, has some drawbacks, the most notable of them being the Old Generation fragmentation and the lack of predictability in pause durations in some cases, especially on large heaps.
G1 Garbage Collection
One of the key design goals of G1 was to make the duration and distribution of stop-the-world pauses due to garbage collection predictable and configurable.
To run the JVM with the G1 collector enabled, run your application as
java -XX:+UseG1GC com.OpenGenus.MyClass
In fact, Garbage-First is a soft real-time garbage collector, meaning that you can set specific performance goals to it. You can request the stop-the-world pauses to be no longer than x milliseconds within any given y-millisecond long time range, e.g. no more than 5 milliseconds in any given second. Garbage-First GC will do its best to meet this goal with high probability (but not with certainty, that would be hard real-time).
To achieve this, G1 builds upon a number of insights.
First, the heap does not have to be split into contiguous Young and Old generation. Instead, the heap is split into a number smaller heap regions that can house objects. Each region may be an Eden region, a Survivor region or an Old region. The logical union of all Eden and Survivor regions is the Young Generation, and all the Old regions put together is the Old Generation.
This allows the GC to avoid collecting the entire heap at once, and instead approach the problem incrementally: only a subset of the regions, called the collection set will be considered at a time. All the Young regions are collected during each pause, but some Old regions may be included as well:
Second optimization is that during the concurrent phase it estimates the amount of live data that each region contains. This is used in building the collection set: the regions that contain the most garbage are collected first. Hence the name: garbage-first collection.
Evacuation Pause: Fully Young
In the beginning of the application’s lifecycle, G1 does not have any additional information from the not-yet-executed concurrent phases, so it initially functions in the fully-young mode. When the Young Generation fills up, the application threads are stopped, and the live data inside the Young regions is copied to Survivor regions, or any free regions that thereby become Survivor.
The process of copying these is called Evacuation, and it works in pretty much the same way as the other Young collectors we have seen before. The full logs of evacuation pauses are rather large, so, for simplicity’s sake we will leave out a couple of small bits that are irrelevant in the first fully-young evacuation pause. We will get back to them after the concurrent phases are explained in greater detail. In addition, due to the sheer size of the log record, the parallel phase details and “Other” phase details are extracted to separate sections.
Concurrent Marking
The G1 collector builds up on many concepts of CMS from the previous section, so it is a good idea to make sure that you have a sufficient understanding of it before proceeding. Even though it differs in a number of ways, the goals of the Concurrent Marking are very similar. G1 Concurrent Marking uses the Snapshot-At-The-Beginning approach that marks all the objects that were live at the beginning of the marking cycle, even if they have turned into garbage meanwhile. The information on which objects are live allows to build up the liveness stats for each region so that the collection set could be efficiently chosen afterwards.
This information is then used to perform garbage collection in the Old regions. It can happen fully concurrently, if the marking determines that a region contains only garbage, or during a stop-the-world evacuation pause for Old regions that contain both garbage and live objects.
Concurrent Marking starts when the overall occupancy of the heap is large enough. By default, it is 45%, but this can be changed by the InitiatingHeapOccupancyPercent JVM option. Like in CMS, Concurrent Marking in G1 consists of a number of phases, some of them fully concurrent, and some of them requiring the application threads to be stopped.
Phase 1: Initial Mark
This phase marks all the objects directly reachable from the GC roots. In CMS, it required a separate stop-the world pause, but in G1 it is typically piggy-backed on an Evacuation Pause, so its overhead is minimal. You can notice this pause in GC logs by the “(initial-mark)” addition in the first line of an Evacuation Pause:
Phase 2: Root Region Scan
This phase marks all the live objects reachable from the so-called root regions, i.e. the ones that are not empty and that we might end up having to collect in the middle of the marking cycle. Since moving stuff around in the middle of concurrent marking will cause trouble, this phase has to complete before the next evacuation pause starts. If it has to start earlier, it will request an early abort of root region scan, and then wait for it to finish. In the current implementation, the root regions are the survivor regions: they are the bits of Young Generation that will definitely be collected in the next Evacuation Pause.
Phase 3. Concurrent Mark
This phase is very much similar to that of CMS: it simply walks the object graph and marks the visited objects in a special bitmap. To ensure that the semantics of snapshot-at-the beginning are met, G1 GC requires that all the concurrent updates to the object graph made by the application threads leave the previous reference known for marking purposes.
This is achieved by the use of the Pre-Write barriers (not to be confused with Post-Write barriers discussed later and memory barriers that relate to multithreaded programming). Their function is to, whenever you write to a field while G1 Concurrent Marking is active, store the previous referee in the so-called log buffers, to be processed by the concurrent marking threads.
Phase 4. Remark
This is a stop-the-world pause that, like previously seen in CMS, completes the marking process. For G1, it briefly stops the application threads to stop the inflow of the concurrent update logs and processes the little amount of them that is left over, and marks whatever still-unmarked objects that were live when the concurrent marking cycle was initiated. This phase also performs some additional cleaning, e.g. reference processing (see the Evacuation Pause log) or class unloading.
Phase 5. Cleanup
This final phase prepares the ground for the upcoming evacuation phase, counting all the live objects in the heap regions, and sorting these regions by expected GC efficiency. It also performs all the house-keeping activities required to maintain the internal state for the next iteration of concurrent marking.
Last but not least, the regions that contain no live objects at all are reclaimed in this phase. Some parts of this phase are concurrent, such as the empty region reclamation and most of the liveness calculation, but it also requires a short stop-the-world pause to finalize the picture while the application threads are not interfering.
Evacuation Pause: Mixed
It’s a pleasant case when concurrent cleanup can free up entire regions in Old Generation, but it may not always be the case. After Concurrent Marking has successfully completed, G1 will schedule a mixed collection that will not only get the garbage away from the young regions, but also throw in a bunch of Old regions to the collection set.
A mixed Evacuation pause does not always immediately follow the end of the concurrent marking phase. There is a number of rules and heuristics that affect this. For instance, if it was possible to free up a large portion of the Old regions concurrently, then there is no need to do it.
There may, therefore, easily be a number of fully-young evacuation pauses between the end of concurrent marking and a mixed evacuation pause.
The exact number of Old regions to be added to the collection set, and the order in which they are added, is also selected based on a number of rules. These include the soft real-time performance goals specified for the application, the liveness and gc efficiency data collected during concurrent marking, and a number of configurable JVM options. The process of a mixed collection is largely the same as we have already reviewed earlier for fully-young gc, but this time we will also cover the subject of remembered sets.
Remembered sets are what allows the independent collection of different heap regions. For instance, when collecting region A,B and C, we have to know whether or not there are references to them from regions D and E to determine their liveness. But traversing the whole heap graph would take quite a while and ruin the whole point of incremental collection, therefore an optimization is employed. Much like we have the Card Table for independently collecting Young regions in other GC algorithms, we have Remembered Sets in G1.
Each region has a remembered set that lists the references pointing to this region from the outside. These references will then be regarded as additional GC roots. Note that objects in Old regions that were determined to be garbage during concurrent marking will be ignored even if there are outside references to them: the referents are also garbage in that case.
Sign up for FREE 3 months of Amazon Music. YOU MUST NOT MISS.