Saving Accepted Code Submissions in CodeForces

In this article, we will save all the accepted submissions from a user in Codeforces in a text file. We will use smeke's profile as an example. We will use the Requests and lxml libraries of python for the purpose.
Getting Started
Inspecting Data Source
Before extracting the required information, we will get familiar with the site structure.
Analysing the URL
If you look carefully at the URLs, you will see they follow a specific syntax. This syntax helps to retrieve the HTML of different profiles using the same code.
In this case, submissions follow the syntax:
https://codeforces.com/submissions/\<username>
So, for extracting data from another username, you just have to edit the URL that replaces the username, and your code extracts data from that username.
To extract submissions from multiple pages, we need to follow the syntax:
https://codeforces.com/submissions/<username>/page/<page number>
The URL of a submission follows the syntax:
https://codeforces.com/contest/<Contest Id>/submission/<Submission Id>
Inspecting the site
To scrape data, you should know how the data is structured for display on the website. You will need to understand the page structure to pick what you want from the HTML response that you will collect in one of the upcoming steps.
We will use Inspect Element to understand the site’s structure. Inspect an Element is a developer tool that lets you view and edit the HTML and CSS of web content.
In this case, we need to extract data from two pages. Firstly, the user's submissions page that contains the submission ID, and second, the web page with submission code. We need to understand the page structure of both.
Extract HTML
We will use Python’s requests library to get the website's HTML code into our Python script so that we can interact with it.
Let us extract data from the first two pages. We need to run a for loop to access multiple pages.
Refer the below code to retrieve the HTML:
import requests
from time import sleep
Username = "smeke"
# To extract from two pages, loop should run two times
for page_number in range(1, 3):
sleep(5)
# change address below accordingly
page = requests.get('https://codeforces.com/submissions/' + Username + '/page/'+ str(page_number))
This code retrieves the HTML data and stores it in a Python object.
After extracting HTML, the next step is to parse it and pick the required data.
Note
- Ensure the pages being accessed are available in the Users submissions, else the scraped data can be incorrect.
- To reduce the number of requests per second, I have added the sleep method in the loop. The number of seconds can be changed according to your convenience, but ensure the total number of requests is under the number specified by the website being scraped.
Parse and extract the data
We will use Python's lxml library to parse the data. The data we want to extract is nested in <\div> tags with class name data table as shown below:
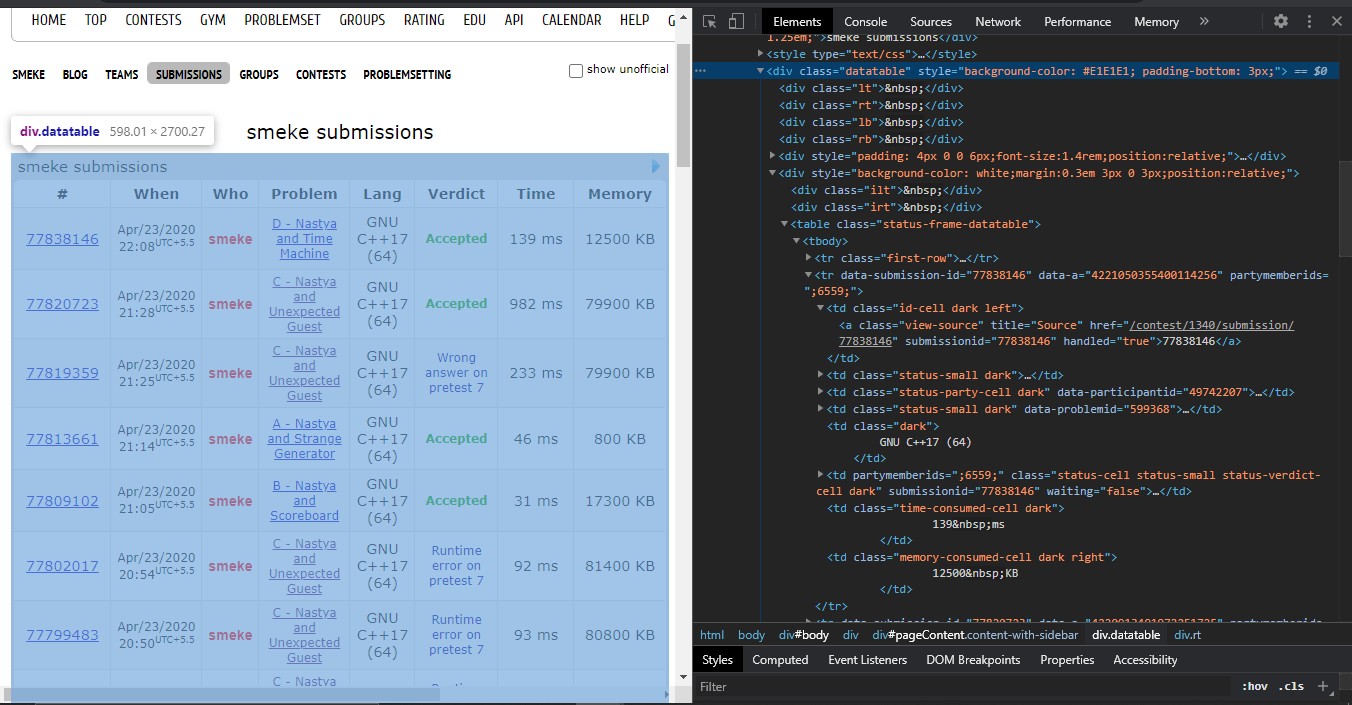
We find the div tags with those respective class-names, extract the data, and store the data in a variable.
First, import the module:
import lxml
Next, create a object and find the data required:
tree = html.fromstring(page.text)
#The data to obtain the URL of submissions
checkStatus = tree.xpath('//*[@id="pageContent"]/div[4]/div[6]/table/tr[position() > 1]/td[1]/*/@class')
verdict = tree.xpath('//*[@id="pageContent"]/div[4]/div[6]/table/tr[position() > 1]/td[6]/span/@submissionverdict')
contestID = tree.xpath('//*[@id="pageContent"]/div[4]/div[6]/table/tr[position() > 1]/td[4]/a/@href')
problemID = tree.xpath('//*[@id="pageContent"]/div[4]/div[6]/table/tr[position() > 1]/td[1]/*/text()')
This way, we have the status of the solution, that is, whether or not we can see the submission, the verdict to check whether it is accepted or not. We also have the submission Id.
In place of the Contest ID, we have a string that includes the contest ID.
The contest ID string is of the form:
" /contest/1340/problem/C "
where "1340" is the Contest ID.
To extract the Contest ID from the string we need to do the following:
for i in range(len(contestID)):
extract_contestID = list(map(str,contestID[i].split("/")))
contestID[i] = extract_contestID[2]
I added the required components in a list to make parsing elements simpler.
result = []
for i in range(len(problemID)):
result.append([contestID[i],verdict[i], problemID[i], checkStatus[i]])
Lastly, for all the entries in the result list, save the submission if they are accepted.
for i in range(len(res)):
# change verdict or don't specify at all
# "view-source" necessary as few submissions are not available(hidden-source)
if res[i][1] == "OK" and res[i][3] == "view-source":
solutionPage = requests.get('https://codeforces.com/contest/'+ res[i][0]+'/submission/'+ res[i][2])
tree2 = html.fromstring(solutionPage.text)
# path to the actual submission
address = './/div[@id="pageContent"]/div[@class="roundbox SubmissionDetailsFrameRoundBox-'+res[i][2]+'"]/pre[@id="program-source-text"]//text()'
code = tree2.xpath(address)
lines = code[0].split("\r\n")
If you want to save all the submissions in a text file or multiple text files
Then, use json library of python to save them in the specified file.
with open('AcceptedSubmissions.txt', 'a') as sub_outfile:
json.dump(lines, sub_outfile)
The output of the following program will be a text file that looks like this.
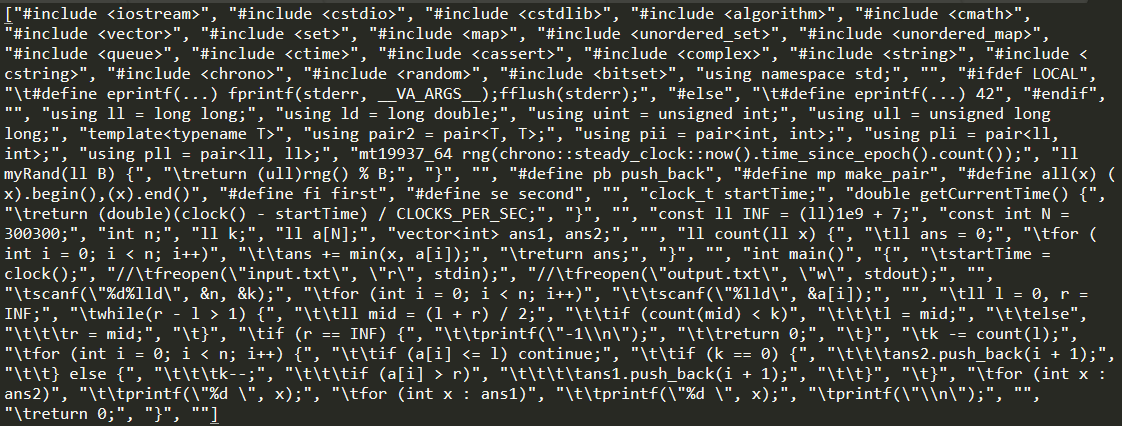
To save the code in a compilable manner, you can use print instead of saving the list as it is.
req_file = open(file_name, 'w')
for line in sub_data:
print(line, file = req_file)
req_file.close()
Note Ensure that the encoding is correct.
The output of the following program will be text file that looks like.
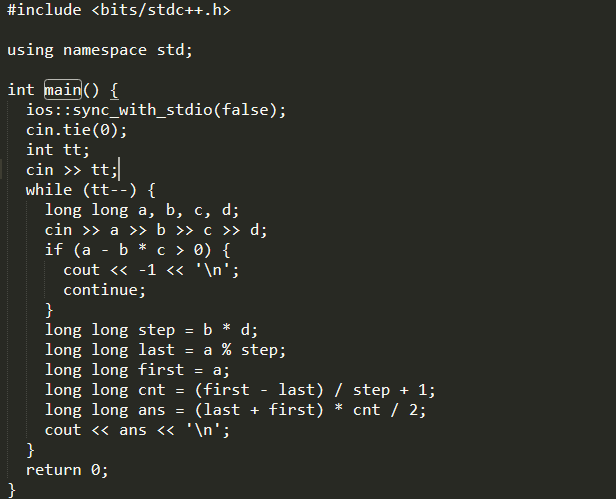
which can be readily compiled.
To get information about another user, we need to change the username in the code file, in place of the given “smeke”.
In this way, with this article at OpenGenus, you have saved accepted submissions of a specific user from the CodeForces website. We hope this article helped you understand how the same works.