Search engine using BERT and Twitter API
This article is about creating a search engine based on the integrating one of the application of BERT ie. "Sentence Semantic Similarity" and tweets which is collected from tweepy(an twitter api to collect tweets or stream live tweets).As we already discussed about how Sentence Semantic Similarity works we are mainly going to focus on the portion of collecting tweets and integrating it with our Fine tuned BERT model , before moving forward let's see how we are going to use this parts step by step.
Getting Similarity between tweets using BERT:
We can Fine tune BERT model to get a similarity score between all possible number of pairs of search query and tweets.As BERT model gives us contextual similarity instead of just comparing the two tokens or words independently ,Before NLP approaches search engine have simple approach in which it simply tries to match the keywords with the rest of articles or tweets in this case but after Machine learning or Natural Language Processing methods introduced
search results shows a deep understanding of a of lot similar words and contextual similarity .
Using Tweepy api to collect the tweets:
Data has been collected with the help of Twitter api tweepy , Just like all api's you need to register for twitter developer account,After that you can use it with provided rate limits .There an interesting about tweepy i have discovered that using different methods to collect the data provide you with different rate limit.First Let's install it.
!pip install tweepy
Dataset :
You can first collect the tweets around a specific topic then later on use to query it or you can simply stream live tweets and apply you query there , I'm going with first one approach as it makes easier to compare your results and observe lit bit more efficiently .These are some of the important library you need to import .
import re
import tweepy
from tweepy import OAuthHandler
from tweepy import API
#Following tow are can be used to stream the live tweets.
from tweepy.streaming import StreamListener
from tweepy import Stream
For using API you need to get permission to collect the tweets and authenticate yourself , this is done by following two commands.You have been provided with API_KEY and API_SECRET.You need to set wait_on_rate_limit=True otherwise there is a chance of your api getting banned due to exploiting data limit.

API_KEY= #####
API_SECRET= #####
auth = tweepy.AppAuthHandler(API_KEY, API_SECRET)
api = tweepy.API(auth,wait_on_rate_limit=True,
wait_on_rate_limit_notify=True)
Following Function tweet_collect collect the tweets using specific query as well as parameters such as maximum number of tweets and the location of file which going to have all th tweets so we can later utilize it.you can Also add the parameters such as specific location co-ordinates( geo-code) from which you want to fetch the tweets , as i have set it to absolute value of geocode which is basically pointing to the center of New Delhi,India . Other parameter is "until" and "language" which is basically the date from which you want to extract and the language you want to extract respectively , there are a lot of parameters according to your need for more know about them please visit official documentation website . Final saving format is in json so we can use it later to create the pandas dataframe as it very easy to handle and work with it.
def tweet_collect(query=None,maxTweets=1000,fName='tweets.txt',until=None):
sinceId = None
tweets=[]
max_id =-1000000
tweetCount = 0
searchQuery = query
tweetsPerQry = 100
with open(fName, 'w') as f:
while tweetCount < maxTweets:
try:
if (max_id <= 0):
if (not sinceId):
new_tweets = api.search(q=searchQuery, count=tweetsPerQry,lang="en",wait_on_rate_limit=True,
geocode='28.644800,77.216721,20km',until=until)
else:
new_tweets = api.search(q=searchQuery, count=tweetsPerQry,
since_id=sinceId,lang="en",wait_on_rate_limit=True,
geocode='28.644800,77.216721,20km',until=until)
else:
if (not sinceId):
new_tweets = api.search(q=searchQuery, count=tweetsPerQry,lang="en",wait_on_rate_limit=True,
geocode='28.644800,77.216721,20km',until=until,
max_id=str(max_id - 1))
else:
new_tweets = api.search(q=searchQuery, count=tweetsPerQry,lang="en",wait_on_rate_limit=True,
geocode='28.644800,77.216721,20km',until=until,
max_id=str(max_id - 1),
since_id=sinceId)
if not new_tweets:
print("No more tweets found")
break
for tweet in new_tweets:
f.write(jsonpickle.encode(tweet._json, unpicklable=False) +
'\n')
tweets.append(tweet)
tweetCount += len(new_tweets)
print("Downloaded {0} tweets".format(tweetCount))
max_id = new_tweets[-1].id
except tweepy.TweepError as e:
# Just exit if any error
print("some error : " + str(e))
break
print ("Downloaded {0} tweets, Saved to {1}".format(tweetCount, fName))
return tweets
After collecting tweets , first we need to remove all the unnecessary symbols ,punctuations etc such as $ etc. because these types of characters in string only include noise to our dataset ,we generally do with help regular expression(re) module of python to manipulate the strings.After cleaning the dataset we have to select specific things from the tweets as a single tweets contains a lot of informations such as Status,followers_count, retweeted_status etc. which we do not need right now , a normal tweets looks like this.
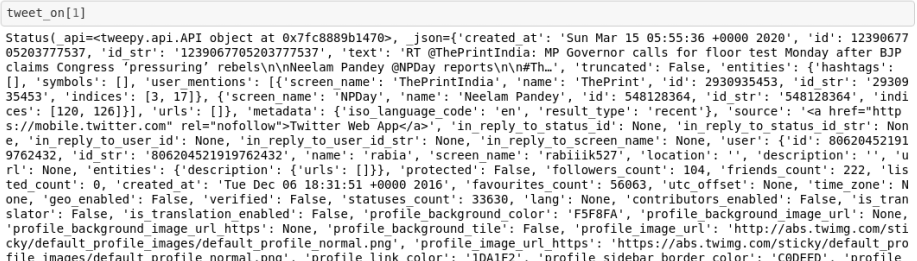
We only need date of tweet ,tweet for doing analysis on it and tweet id for tracking a particular tweet.After getting this we need to save it in a pandas dataframe as i described earlier pandas dataframe is the most suitable form to apply operation on dataset with python.I have also trim all the tweets to certain length as we need to have specific length of tweets to input into the BERT.
def clean_tweet(self, tweet):
return ' '.join(re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)", " ", tweet).split())
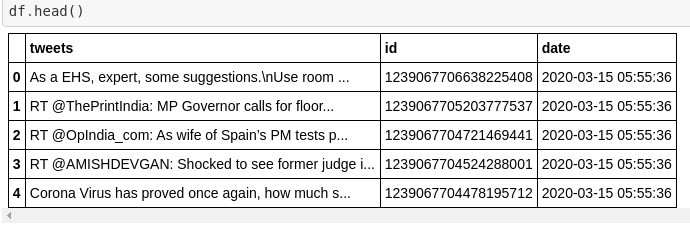
def tweets_to_data_frame(self, tweets):
df = pd.DataFrame(data=[tweet.text[:150] for tweet in tweets], columns=['tweets'])
df['id'] = np.array([tweet.id for tweet in tweets])
df['date'] = np.array([tweet.created_at for tweet in tweets])
return df

After that all you need to compute similarity between query and tweets , then get the top most result with highest score , for the model you can simply use a module for BERT sentence similarity or try to train a custom as we already covered it. I'm using "semantic-text-similarity 1.0.3" for get the similarity score.I simple use case of this as follows.
!pip install semantic-text-similarity
from semantic_text_similarity.models import WebBertSimilarity
web_model = WebBertSimilarity(device='cpu', batch_size=10) #defaults to GPU prediction
web_model.predict([("She won an olympic gold medal","The women is an olympic champion")])
Endnote:
The same can achieved with a number of language models if you interested in seeing the with infersent model you can go to this repository for seeing the implementation. These types model gives a boost to the search engine algorithms a lot right now you are getting more and more accurate results due the high efficiency of these algorithm.As start seeing auto completion becoming more accurate because no longer it depends on simply keywords matching as it used to be previously.