SPVs and Bloom Filters in the Bitcoin Protocol

In this article, we learn about simple payment verification and bloom filters in the Bitcoin protocol.
Table of contents.
- Introduction.
- SPV Nodes.
- Bloom Filters.
- SPV Nodes and Bloom filters.
- Summary.
Introduction
We learned about blockchain nodes and the different types of blockchain nodes including their roles. We said that a full blockchain node stores a copy of the whole blockchain-200GB. These nodes require a lot of computing resources however, they offer benefits such as quicker transaction processing, no transaction fee for hosts, etc.
Unlike full nodes, most bitcoin clients run on devices with less computing power such as tablets, smartphones, embedded systems, etc. These devices use a simplified payment verification(SPV) that allows them to operate without the need to store the full Bitcoin blockchain database.
Such devices are referred to as SPV clients or lightweight clients.
A bloom filter is a probabilistic search filter that is used to describe a pattern without actually specifying it. These were introduced shortly after SPVs were introduced to solve privacy issues. SPVs could now use search patterns while protecting their privacy at the same time.
SPV Nodes.
SPV nodes are nodes that only store block headers. This results in a much smaller chain compared to the full blockchain since no transactions are stored. This also means that SPV nodes can't process transactions because of the limited information they have. Therefore they use a different verification method that relies on blockchain peers to provide partial views of the relevant part of the blockchain needed at a specific time.
An SPV node can be compared to a tourist in a new city with only a single reference point on how to get around. He/she does not know the directions so will ask around until the destination is reached. On the other hand, a full node is compared to a tourist with the whole map and does not need to ask for any directions.
For an SPV to verify a transaction, it uses the transaction depth in the main blockchain instead of the height, unlike a full node that can go back even to the genesis block created in 2009. An SPV node verifies the chain of all blocks and links the chain to the transaction of interest.
The process of verifying a transaction is as follows; Given a transaction that is in block 100,000, A full node examines a transaction by linking all blocks down to the genesis block and constructs a full database of UTXOs. This makes sure the transaction is valid by making sure the UTXO remains unspent.
On the other hand, an SPV node established a link between the transaction and the block that it is contained in by using a Merkle path. The SPV node then waits until it sees 6 blocks 100001 - 100006 piled above the block storing the transaction. It verifies the transaction by establishing its depth under 100006 - 100001.
Since other network nodes accepted block 1000000 and produced 6 more blocks on top of the block is proof by proxy that the transaction was not double spent, therefore it is considered valid.
The following is an image demonstrating how SPV nodes synchronize block headers
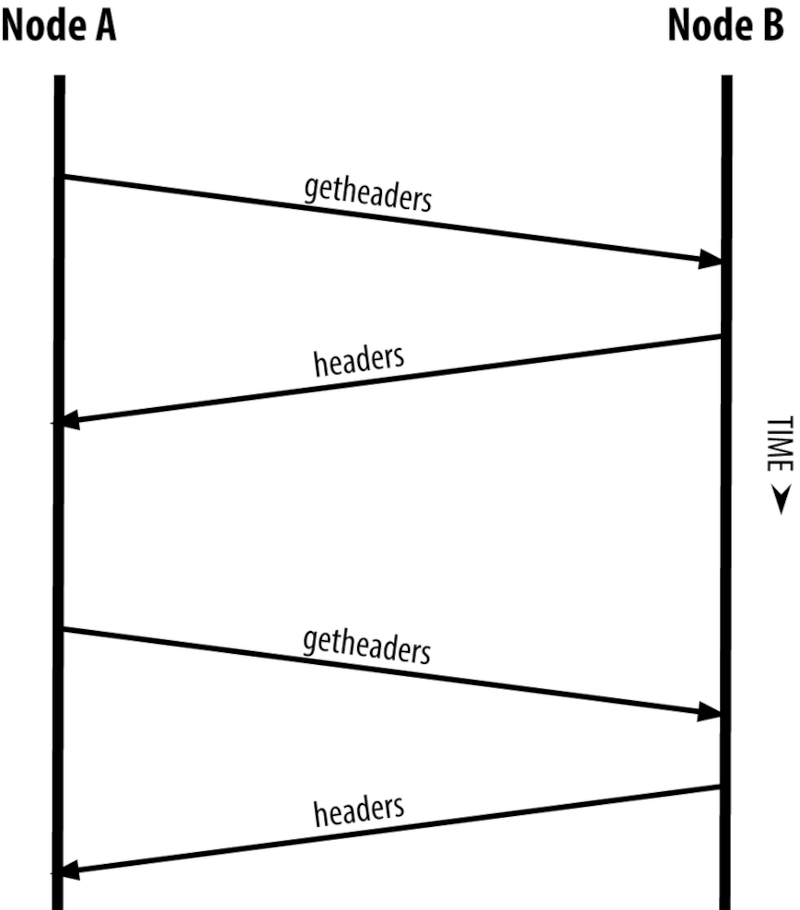
Above, getheaders gets the block headers. The response is n block headers. This process is similar to a full node retrieving full blocks.
After SPVs were introduced bloom filters were also introduced to solve privacy risks that cane with SPV nodes. These allowed SPV nodes to receive a subset of transactions without having to reveal addresses they are interested in. This filtering mechanism uses probabilities rather than fixed patterns.
Bloom Filters.
We define a bloom filter as a probabilistic search filter. Here we can specify a search pattern using probabilities instead of fixed patterns. This was introduced to solve privacy issues with SPV nodes, these nodes could now ask peers for matching transactions using a pattern without revealing addresses, keys, or the transactions they are looking for.
Using our previous analogy of the tourist who asks for directions in a new city. In this case, by using bloom filters the tourist will ask for vague directions, for example, if the tourist intended to reach 'Gameday Catering' - a catering company in city X, the tourist can ask for a place starting with 'G' and ending with 'y' and contains the letter 'm' in between. This ask is pretty vague, even if the person asked wanted to figure out where the tourist was going he/she couldn't. In this case, the tourist reveals less information hence protecting the privacy at the expense of getting both relevant and irrelevant results. In general, if the tourist asks for a specific pattern, he/she sacrifices privacy for relevant results on the other hand if the tourist asks using a vague pattern, he/she gets a lot of directions, most of which are irrelevant.
Bloom filters allow SPV nodes to specify a search pattern that is both precise and upholds privacy, in that a specific bloom filter produces accurate results at the expense of revealing patterns an SPV node is interested in, on the other hand, a vague bloom filter produces more data about more transactions, most of which is irrelevant although privacy is kept.
SPV Nodes and Bloom filters.
As mentioned, SPV nodes use bloom filters to filter transactions and block an SPV node receives from peers by selecting only transactions of interest to an SPV node without revealing addresses or keys the SPV is interested in.
An SPV node initializes a bloom filter as 'empty' meaning the filter won't match any patterns. The SPV node makes a list of keys, addresses, and hashes it is interested in by extracting the public key hash, script hash, and transaction IDs from UTXOs controlled by a wallet.
Each of these pieces of data is added to a bloom filter which matches the patterns present in a transaction without revealing the patterns themselves.
The SPV node sends the bloom filter to a full node with the search parameters that checks several parts of a transaction against the loom filter looking for matches. After a filter is established, the peer tests each transaction output against the bloom filter, and only matching transactions are sent back to the SPV node. The SPV node discards false positives and uses the correct transaction to update its UTXO set. Additionally, it modifies the bloom filter to match future transactions that reference the found UTXO. A full node uses the new bloom filter to match new transaction references in the search parameters and the process repeats itself.
SPVs use Merkle trees extensively because they cannot store the full copy of the blockchain. For an SPV to verify a transaction, it uses an authentication path or Merkle path from the Merkle tree.
For example, an SPV node that is receiving incoming funds establishes a bloom filter on all its connections to limit the number of transactions received to only those that have the set filter. When a peer fids the transaction matching the filter, it sends the block which has the merkle block message containing the block header and the Merkle path that links the transaction the SPV is interested in the root of the merkle tree inside the block.
The SPV node uses the merkle tree to connect the transaction to the block and verify that it is included in the block. This SPV node also uses the block header to link the block to the blockchain. These two links(transaction-block, block-blockchain) when combined prove that the transaction exists in the blockchain. In conclusion, the SPV node will receive less than a kilobyte of data for the block header and merkle path compared to the full copy of the blockchain.
The steps can be summarized algorithmically as follows;
- The SPV client request Merkle Branch from the full node for transactions.
- SPV client checks the Merkle Root against the block header.
- SPV client checks that the block is at the correct depth.
- When wallets only request transactions to the addresses it owns, full nodes will become aware of the owner, we mitigate this by using bloom filters
- We start with an empty array of m bits.
- Hash the data to filter on(public key) using k hash functions to a value greater than 0 but less than m.
- Set the bits in the array.
- We repeat for any other filter criteria.
- For a full node to relay a block, it uses k hash functions and checks for an intersection on the filter.
- If there are no hits, the transaction is removed from the Merkle tree and is not forwarded to an SPV client, otherwise, if there is a hit, the pruned Merkle tree is forwarded to the client.
Note that there may be false positives meaning the SPV need to do some work to remove them. This also serves to hide the request from full nodes.
Summary
An SPV node can verify transactions without the need for the entire blockchain. It is commonly used in bitcoin wallets acting as intermediaries between the app and the mining node.
A full node checks an entire chain of blocks below it to guarantee that a UTXO is not spent. SPV checks how deep the block is buried by a handful of blocks above it.
A Merkle tree is a data structure storing all transactions in a block.
Light clients(wallets) don't store the whole blockchain instead query other nodes for transactions and blocks. These consume less computing resources but lack privacy.