11 Different Computer Vision tasks

In this article at OpenGenus, we will be going over the basic ideas of some of the different areas of computer vision. We'll start by giving a brief description of the topic followed by some techniques used.
Table of Contents
- Image Denoising
- Spatial Domain Filtering Methods
- Transform Domain Methods
- Image Classification
- Supervised Learning
- Unsupervised Learning
- Object Localization
- Edge Detection
- Image Restoration
- Feature Detection and Matching
- Scene Reconstruction
- Pose Estimation and Tracking
- Semantic Segmentation
- Instance Segmentation
- Object Detection
- R-CNN
- YOLO
- Summary
Different Computer Vision tasks
The 11 Different Computer Vision tasks are:
- Image Denoising
- Spatial Domain Filtering Methods
- Transform Domain Methods
- Image Classification
- Supervised Learning
- Unsupervised Learning
- Object Localization
- Edge Detection
- Image Restoration
- Feature Detection and Matching
- Scene Reconstruction
- Pose Estimation and Tracking
- Semantic Segmentation
- Instance Segmentation
- Object Detection
Image Denoising
Like the name implies, image denoising is the process of removing the noise, random variations in color and brightness, from an image in an attempt to estimate the original image. In other words, it is the process of removing the granularity and other such defects to improve the quality/clarity of an image. Image noise usually arises from limitations in electronics like the quality of a camera sensor or as by products of image processing, and thus is almost unavoidable.

Mathematically, an image is simply a function, I(x, y) for instance, that maps an xy coordinate on the image to one or more color values depending on the image type (RGB, grayscale, etc). Noise, N(x, y), is either added or multiplied to the pixel to create the corrupted image function, C(x, y). Thus, mathematically, C(x, y) = I(x, y) + N(x, y) or C(x, y) = I(x, y) * N(x, y). Next we will discuss some common image denoising technique types and examples.
Spatial Domain Filtering Methods
Spatial domain methods are the traditional method used to denoise images. Typically they reduce noise to a respectable extent at the cost of image blurring, which may eliminate sharp edges. Techniques can further be divided between linear and non-linear filters. Examples of linear filtering methods include mean filtering and Wiener filtering. Examples of nonlinear filtering methods include median filtering, weighted median filtering, and bilateral filtering.
Transform Domain Methods
Transform domain methods involve the choice of one of many possible transform functions. Originally, these methods stemmed from the Fourier transform, but have since come to encompass many other variants. These methods can be further subdivided into adaptive and non-adaptive transform. Some methods include independent component analysis (ICA) and PCA (adaptive transforms), and wavelet methods (non-adaptive transform).
To read more on image denoising and its techniques in particular, you can refer to this article here: Image Denoising and various image processing techniques for it
Image Classification
Image classification is another area of computer vision that refers to assigning an image one or more labels from a fixed set of labels. These labels are usually descriptive of the content of the image, and each label may have varying levels of confidence (how statistically likely the image was labeled correctly).
Image classification can be further subdivided into several types: binary, multiclass, multilabel, and hierarchical. Binary classification assigns images one of two possible labels, multiclass categorizes objects into three or more classes, multilabel gives singular objects one or more different labels at once, and hierarchical assigns objects progressively more specific labels (E.g. Animal -> Mammal -> Primate -> Human).
Generally, when image classification models are trained, the images that they use go through pre-processing to improve computational quality for evaluation (this may include denoising) before using techniques such as edge detection and texture analysis to examine groups of pixels during the feature extraction stage to finally classify the object. Next, we'll go over two broad categories of image classification techniques used to train models, supervised and unsupervised learning.
Supervised Learning
Supervised learning, like how its name may allude to, is when the machine is trained on data that has been manually labeled by an actual human, or in other words, the model is trained under the "supervision" of the human researcher. All of the input images and their corresponding features have already been mapped to the corresponding class that the image belongs to. The model then uses its experience with the existing dataset tries to make connections between the training data and any new data that it encounters. Supervised learning methods can be single or multi-label. Some notable examples of supervised learning methods include linear/logistic regressions, K nearest neighbors, neural networks, decision trees, support vector machines, and random forests.
Unsupervised Learning
While supervised learning still involves some level of human input, unsupervised learning is where the machine draws its own conclusions about the data without any preexisting tags. The machine finds patterns in the image and groups these patterns together in a process known as clusterization. Note that the machine does not find the class of the object directly with this method: it only creates clusters, so it is up to the researcher to determine what class these clusters represent. Some notable clusterization algorithms include K-Means, Mean-Shift, DBSCAN, Expectation-Maximization, Gaussian mixture models, etc.
Object Localization
Object localization is a process that involves trying to draw boxes around an object, and the number of objects is not necessarily known beforehand, so a variety of algorithms are employed to narrow in on a number of potential object bounding regions. These include algorithms for edge/shape detection, image restoration, feature detection and matching, scene reconstruction, and pose estimation and tracking. The regions are then classified per the image classification method of choice. Object localization plays an important role as a subtask within object detection, which we will go over later. For now, we will go over the techniques listed above, which can apply not just to object localization but to pretty much any CV task in this article.
Edge Detection
Edge detection, like its name implies, is an attempt to mathematically determine where an edge or curve occurs in an image. More technically, edge detection aims to look for the sharp changes or discontinuities in brightness between pixels. This problem is more complicated than it seems due to blurring and other things that make the boundaries between edges more gradual. Some examples of edge detection algorithms include traditional filter based methods like Canny edge detection or deep learning methods like Holistically Nested Edge Detection (HED)
Image Restoration
Image restoration is when the machine tries to estimate the original, quality image from a corrupt input. Image denoising is one of the processes that image restoration employs and it uses all of the same techniques in that area. Other processes that may be conducted include super-resolution, which is creating a higher resolution image from a lower resolution image, and image-in painting, which is when missing regions of an image are filled in.
Feature Detection and Matching
The name feature detection in the context of computer vision is the detection of corners, edges, blobs, "regions of interest" (unique texture, pattern, etc), and other geometrically distinct pixel constructs that may represent identifying information of something in an image. Algorithms like Harris Corner, SIFT, and SURF are first used to identify these "interest points" throughout an image. These points are then given identifying information through descriptor algorithms (again SIFT, SURF for example). Finally, in the matching process, these interest points and their descriptors are compared across different images of the same objects either through a brute force approach or the FLANN Matcher for example.
Scene Reconstruction
Scene reconstruction is basically recreating a 3D object by examining the object from an image and represents a particularly complicated problem in the field of computer vision. Methods involve either using a depth map or having an algorithm estimate the depth based on light levels and other such information. Some of these algorithms include Delaunay method, VR technique, and Voxel Grid.
Pose Estimation and Tracking
Pose estimation is a technique that predicts and tracks the position of an object, which is done by looking at the orientation of the given object (its "pose"). The machine identifies major points on the object (not necessarily the object in its entirety, so like the joints on a human) to track in the given image or video. The most common architectures for this process typically utilize CNNs in some manner (Convolutional Neural Networks), which include Mask-RCNN, OpenPose, and PersonLab.
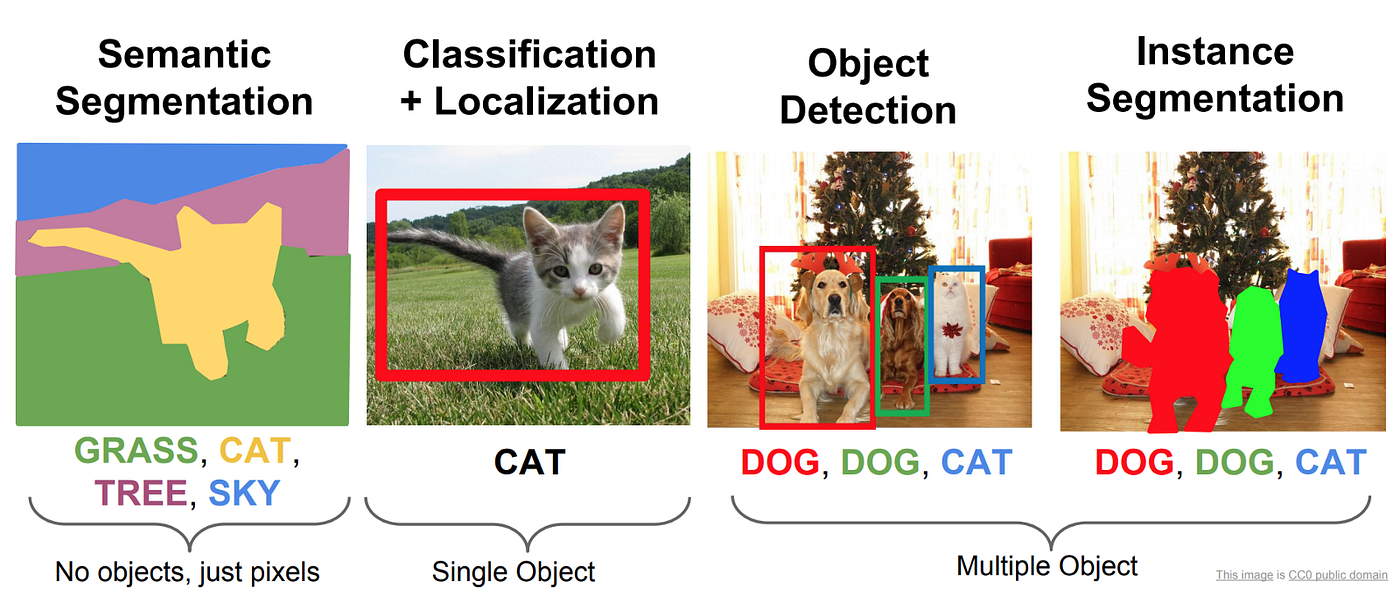
Semantic Segmentation
Semantic segmentation is a form of object segmentation, and it refers to marking the pixels of each object based on their class label. For example, an image with three different types of objects will have colored pixels for each of those three types, so objects of the same type will have the same color. Fundamentally, this makes semantic segmentation an image classification problem for each pixel in the image. Thus, the machine must use some of the techniques mentioned earlier to extract features and categorize regions of pixels for this to work.
Instance Segmentation
Instance segmentation, another form of object segmentation, is more specific than semantic segmentation in that it will not only distinguish between objects in different categories, but it will also highlight individual instances of the same class label, treating them as separate objects. Therefore, instance segmentation is said to be a combination of object detection and semantic segmentation.
Object Detection
Object detection is simply the process of identifying an object within an image and actually involves the combination of several related computer vision tasks, which include image classification, object localization, and semantic/instance segmentation. We have already gone over object image classification, so we don't need to define that. While object detection and object localization are often confused, they are not the same process, with object detection being the process with the broader scope. Next we will go over two popular families of object detection models.
R-CNN
R-CNN, which stands for Region-Based Convolutional Neural Network, uses deep learning models to conduct the object detection. It uses an algorithm to create candidate regions for potential objects, and then the CNN makes a pass over each region to extract features. Finally, the obtained information is passed to an image classification model. Due to the necessity to make a pass over every candidate region, R-CNN's speed posed a significant detriment to its use, which spawned the creation of Fast R-CNN and Faster R-CNN, R-CNN's more optimized successors.
YOLO
YOLO ("You Only Look Once") Models utilizes a single neural network that predicts the class labels for the objects straight from the bounding boxes of the object. The image is split into a grid, and within each grid the model creates mini bounding boxes for different portions of different potential objects and gives preliminary classifications. Later on, all these individual bounding boxes are combined to construct the final bounding box of the whole objects. While the model has less accuracy than R-CNN, it runs noticeably faster, and subsequent versions (YOLOv2, YOLOv3) have only improved on this performance.
Summary
In this article, you have learned about these three domains of computer vision and some of their corresponding techniques:
- Image denoising
- Image classification
- Object localization
- Semantic segmentaiton
- Instance segmentation
- Object detection