
In this article, we discuss how programs written in a functional programming paradigm are compiled.
Table of contents.
- Introduction.
- Compiling functional languages.
- Desugaring.
- Graph reduction.
- Code generation for functional cores.
- Optimizing the functional core.
- Advanced graph manipulation.
Introduction.
Functional programming is a programming paradigm whereby building software relies heavily on the use of pure functions.
A pure function is a function whose results are dependent on the input parameters and its operations have no side effects and thus makes no impact apart from the return value.
Pros of functional programming include; bug-free code, useful for parallel programming, efficiency, nested functions support.
Compiling functional languages.
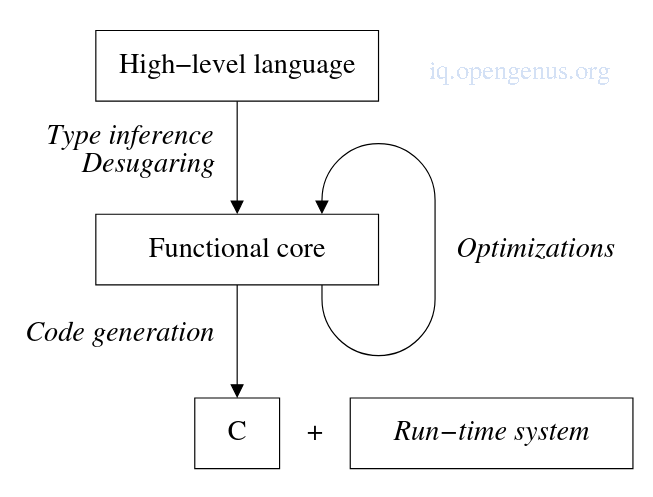
Functional languages requires additional work during compilation because of its additional aspects such as List notations, polymorphic type checking, etc, as can be seen in the image below.

Higher-order functions and lazy evaluation is usually deferred to the run-time system, which is itself a functional language larger than most imperative languages and includes functions such as garbage collection, dynamic function creation/invocation and suspension/resumption of lazy computations.
Compiler structure.
After initial translation of the high-level language into the functional core, optimizations such as constant folding, common sub-expression elimination, function in-lining are implemented to improve code quality.
The code generation phase will take the functional core and transform it into C programming language which is the target code.
The C program in finally compiled with a c compiler and linked with the run-time system into an executable.
Functional core.
A functional core must be high-level enough to server as a target for the compiler front-end to compile syntactic sugar away and on the other hand it must be low-level enough so as to allow concise descriptions of optimizations often expressed in case analyses of core constructs.
When using C, the code should not be as low-level as when generating assembly code.
An example in Haskell
fac :: int -> int
fac n = if (n == 0) then 1
else n * fac (n - 1)
Mapping in C
int fac(int n){
return (n == 0 ? 1 : n * fac(n-1));
}
Code generation phase focuses on making high-order functions and lazy-evaluation explicit by generating calls to the run time system.
Polymorphic type checking.
Polymorphic type checking e.g in haskell is much more difficult compared to imperative(monomorphic) languages such as C this is because type declarations are optional and type equivalence needs redefinition when polymorphic types are declared.
The haskell type checker would be responsible for deriving the type information based on the function definition.
An example
map f[] = []
map f(x:xs) = f x : map f xs
The [] pattern tells us that the second argument is a list same as the result of the map.
The list types are unrelated therefore the first equation constrains the type to the following;
map :: a -> [b] -> [c] Where a, b and c are type variables representing arbitrary types.
The second equation has the subexpression x which tells us that f is a function.
The general type of a function is α -> β. We know however x is an element of the argument list with type[b] and that f x is part of the map's result with type[c] and thus we conclude that the type of f is b -> c.
The type of map will be constrained to map :: (b -> c) [b] -> [c].
Type checking in haskell boils down to handling the function's application which is the building block of expressions and involves polymorphic functions as well as arguments.
Desugaring.
This is removal of syntactic sugar from haskell and transforming it into its functional-core equivalent.
In this section we desugar lists however, be sure to go through the references provided at the references section so as to learn how the rest of functional program aspects such as pattern matchings, list comprehensions and nested functions are translated.
Translating lists.
List notations contains the following syntactic three syntactic sugars, :, , and .. infix operators.
The : operator constructs a node with three fields namely a type tag Cons, an element and a list.
An example
x : xs is transformed to (Cons x xs).
Another example
[1, 2, 3]
is transformed to (Cons 1( Cons 2 (Cons 3[])))
Lists e.g [1..100] and [1..] are translated to calls to library functions expressing these lists in terms of : and [].
Graph reduction.
A graph reducer is an interpreter at the heart of a run-time system which operates on heap-allocated data structures representing expressions that are part of the functional program being executed.
It deals with higher-order functions and lazy evaluation.
It is used in the code generator to handle applications of standard and higher-order functions to their functions.
A function application can represent a curried function consisting of a function and some arguments or a lazy function application with all arguments present whose value might not be needed during the remainder computation.
Execution of a functional program starts with the construction of a graph representing the initial expression whose value must be computed.
Then the graph reducer selects the reducible expression or redex which is part of the graph representing an expression.
The redex is reduced and this process is repeated until the reducer cannot find a reducible expression.
A fully reduced expression is returned as the result.
Reduction order.
The reduction order will involve only reducing redexes which are essential for the final result.
An algorithm for finding an essential redex is as follows;
Start at root, if it is not an application node stop and exit otherwise reduce it.
Traverse the application spine down to the left to find a function that must be applied.
Check whether the spine contains the necessary number of arguments for the function f, if not we have a curried function that cannot be applied, so we stop.
If the arguments are more than necessary, part of the spine is involved in the immediate reduction and the reduction must be a new function that can be applied to unused arguments.
If all n arguments are present in spine from root, this is an essential function, evaluate its strict arguments and apply f.
The replacement expression is also essential for the final result therefore we don't have to return to the root and can search the application spine from this point for a new function to apply.
Unwinding is the process of developing the graph and finding the next redex to be evaluated in the computation by always selecting the left outermost redex.
This reduction order is know as normal-order reduction and it is the underlying mechanism to implement lazy evaluation.
The reduction engine.
The reduction engine operates on four types of graph nodes numbers, list, functions applications and function descriptors.
An integer is represented directly by its value.
A list node holds one constructor consisting of pointers to the head and tail of the list.
A function descriptor will contain the arity of the function, its name for printing and debugging purposes and a pointer to the C code.
A binary application node will hold pointers to the function and argument.
Nodes are created by invoking associated constructor functions which call the memory manger to allocate a fresh node in the heap.
When the reduction engine detects a function descriptor, it checks if all arguments are present, if not reduction stops, otherwise if the arguments are present, the pointer to the function code is retrieved from the descriptor and the function is called.
The reduction engine also has several routines implementing the semantics of the built-in arithmetic and list operators.
Code generation for functional cores.
Generating C code for functional core programs is an almost trivial task when the graph reducer is in place since the only task for the C code is to create graphs for the interpreter eval().
A function descriptor and necessary code to build the right-hand side graph is generated for each function.
Translating a core construct into a function call
Expressions consisting of identifiers, numbers, function applications, arithmetic operators, if-then-else compounds and key expressions form the heart of the functional core.
Identifiers need no processing, names are used in the C code.
Numbers and booleans are allocated in the heap by being wrapped with their constructor functions.
Expressions involving arithmetic infix operators are regarded as syntactic sugar and are translated to code that constructs a graph.
If-then-else is translated into a call to the built-in conditional primitive.
The let-expression introduce local bindings which are translated into assignments to local variables which hold pointers to a graph node representing the named expression(can be a curried function).
Performance of interpreted core programs is poor due to the construction and interpretation of graphs to solve this, short-circuiting the construction of the application spine is implemented as an optimization technique.
The performance effect of this optimization depends on the interpreted program although improvements of a factor of two are common.
Optimizing the functional core.
Even if short-circuiting of application nodes is applied the performance will still be way off compared to the performance of imperative code.
Therefore to match the performance of imperative languages, functional languages have the following four optimizations which are performed on the AST after the source language has been simplified to an intermediate code representation.
These optimizations are;
Strictness analysis and boxing analysis which will deal with the overhead of manipulating graph nodes.
Tail call elimination and accumulation of arguments which deal with the function call overhead introduced in functional programming style.
These four optimization techniques allow code generation for example for a recursive factorial function to be as efficient as its imperative loop-based counter part.
Advanced graph manipulation.
The performance of functional programs is dependent on the amount of graph manipulation involved so streamlining the handling of graph nodes will have an impact in the performance.
Variable length nodes.
This is whereby each node in the graph will consist of a tag followed by a number of fields depending on the node type instead of using a single node type to represent different possibilities.
The performance improvements are demonstrated by less heap space being required and thus fewer garbage collections.
The cache performance also increases since unused parts of the uniform nodes don't tale up previous cache space.
Pointer tagging.
Graph nodes are small and the node tag field consumes memory and since the graph node is always identified as a pointer we can lift the tag from the node and place it in the pointer.
This is pointer tagging, it saves one word per graph node which reduces pressure on the cache and garbage collector.
Another advantage is that inspecting the tag will now consist of selecting a few bits from the pointer instead of dereferencing it.
The small cost for this is before dereferencing a tagged pointer, the tag bits are zeroed to convert it to a clean pointer which requires one AND operation.
Aggregate node allocation.
Previous code generation schemes translated a function into a sequence of calls so as to build a graph representing the function body, this causes nodes to be allocated one by one, however it is more efficient to allocate them all at once by using aggregate node allocation
Aggregate node allocation requires analysis of the AST so as to compute the total amount of heap space needed for the complete expression.
Vector apply nodes.
Using binary application nodes will support currying and higher-order functions however have the drawback of generating long application spines for functions with multiple arguments.
Aggregate allocation reduces the cost of building a spine but more can be achieved by representing the spine as a single vector of pointers to the arguments.
A vector apply node is a variable length graph node consisting of a function pointer, a length field and n argument pointers.
The length field is needed by the graph reducer and garbage collector for it to function properly.
An advantage of this is that it is space efficient than a spine of binary application nodes if the number of arguments exceed two(2 + n verses 2n).
Also unwinding nodes becomes cheaper since pointers in the application spine don't have to be traversed.
Vector apply nodes can be seen as self contained closures since they represent delayed function calls where the number of arguments match the arity of the function.
The graph reducer improves performance by discriminating closures from curried applications and thus saving processing and stack space.
This is an important optimization since most vector apply nodes hold closures and currying is used sparingly in most functional programs.
Summary.
Functional languages promote declarative programming where programmers can specify only what to compute and then it is up to the compiler and run time system to decide how, where and when the compute sub-results.
Functional languages demonstrate a special syntax and programming constructs which raise the level of abstraction which makes the compiler and run-time system complex.
References.
- Functional programming with haskell (PDF) "The Craft of Functional Programming" book by Simon Thompson at Federal University of Minas Gerais (UFMG).
- Modern Compiler Design, 2nd Edition, Dick Grune Kees van Reeuwijk Henri E. BalCeriel J.H. Jacobs Koen Langendoen.