
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we discuss garbage collection, a mechanism that is performed by the garbage collector which reclaims memory that it can prove is not used.
Table of Contents.
- Introduction.
- Garbage collection.
- Garbage collection as a graph traversal problem.
- Assumptions in garbage collection.
- Garbage collection algorithms.
- Summary.
- References
Introduction.
Traditional memory management divides memory into 3 categories namely, global data, the stack and the heap.
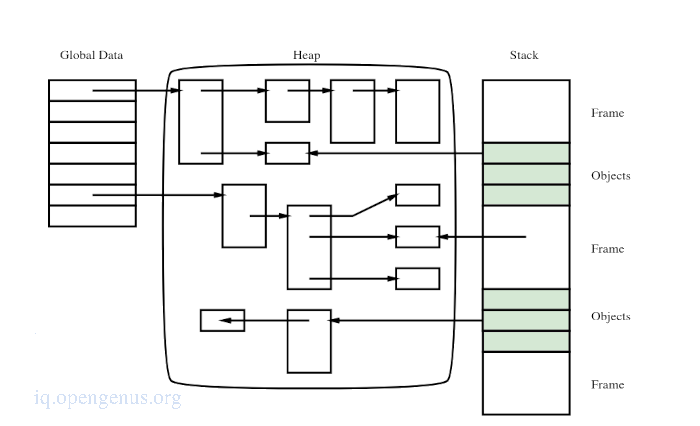
Global data is a collection of global variables. It is globally visible throughout the execution of a program and of constant size.
The stack will contain a series of frames where each frame will represent a function scope. Stack frames are deallocated when the procedure which is associated by them terminates.
Both global data and the stack have references called roots, in the heap which holds chunks.
These chunks on the heap are allocated and deallocated explicitly. A program will detect whether a chunk is no longer needed so that it may be deallocated and the memory previously used by the deallocated chunk reused.
A free list is the structure responsible for management of deallocated memory that is waiting for reallocation.
Issues with this type of memory management.
- Poor decision making, deciding whether a chunk is still in use can lead either to memory leaks or dangling pointers. These are catastrophic if they occur.
- Allocation and deallocation using the traditional algorithms(first fit, binary search tree, size partitioning) are very costly in terms of processor time and memory accesses.
- Structure and type of chunks on the heap are highly dependent on the domain of application and language being implemented.
Garbage collection.
Instead of the application task explicitly deallocating chunks when they are no longer needed, a garbage collector uses program's state information to determine whether any valid sequence of mutator actions could be referencing a chunk.
If no program actions reference a chunk, then this chunk is unnecessary in the on-going computation and therefore it is considered garbage therefore it is reclaimed by the collector.
The remaining referenced chunks are referred to as live since they are still referenced by the sequence of actions.
Note, the cost of allocating stack frames on associated chunks on the garbage collector heap is comparable to the cost of using the traditional stack allocation.
Garbage collection as a graph traversal problem.
Reachable objects are those objects that can be referenced by a future sequence of valid mutator actions.
Live objects are those that will referenced in the future by the mutator, these are necessary for ongoing computations.
A garbage collector can be thought of as performing a liveness analysis on heap objects by locating chunks that cannot be referenced directly from a root set(stack and global variables) or from a root set via other chunks on the heap.
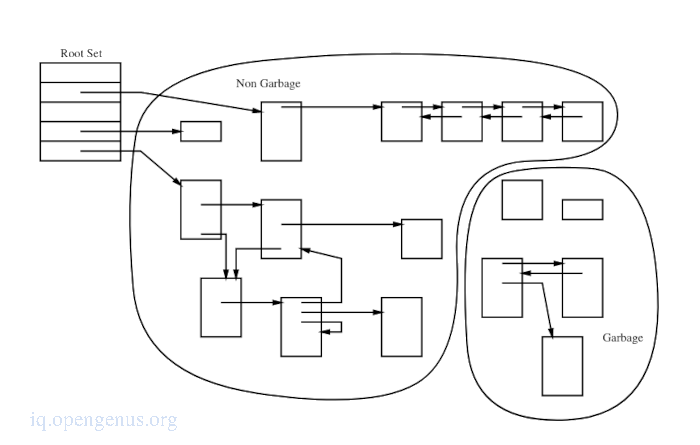
From the image we can see that live chunks are accessible from root set and no garbage chunks is reachable.
Looking at garbage collection as a graph traversal problem will permit application of graph algorithms such as breadth first and depth first search traversal for tracing the heap to determine whether a chunk is garbage.
Assumptions in garbage collection.
- Depending on the nature of the compiler, objects that are reachable from current variables which may be shown by static analysis are said to be unnecessary and are assumed reachable. In such cases compilers aware of the use of a garbage collector assists the garbage collector without direct communication.
- Functions are assumed to return, for analyzing reachability without this assumption will be similar to the halting problem.
- Execution stacks share similar problems with registers but they rarely change therefore are cheaper to maintain type information.
- Programming languages with little type safety such as C/C++ must be made about every byte of every object on the heap.
- Type information of rapidly changing registers can only be maintained in expensive, non-portable ways therefore some implementations will make a conservative assumption that all registers are pointers. This may lead to memory retention but because of changes to registers, values wont be identical sequential collections and therefore will cause memory to be retained for at most one collection. This leads to an upper bound on retained memory.
Looking at assumptions 3, 4 and 5. We see that implementation trades off lack of type information for increased memory retention.
The effectiveness of this trade off depends on the following factors.
1. Pointer size.
A short pointer (16 or 32 bits) will lead to a relatively high density of objects in the address space which will lead to a high probability of random bit-pattern being mistaken for a valid pointer int the heap.
2. Volatility of data.
If an object is allocated to an address pointed to be static data, it is pinned for the lifetime of the program while changeable data is pointer elsewhere which will allow the pinned object to be freed.
3. Type maintenance cost.
Maintenance costs for maintaining type information for the given area of memory will vary between registers(high cost type maintenance) and the heap(low type maintenance cost).
In a non-type-safe language, cost of maintenance is very high.
4. Interconnectedness of chunks.
Large multi-cyclic data structures are likely to be retained for longer than single element object which are lacking pointers to them from other garbage.
These selections of assumptions to be made are dependent on the type-safety of the language. ie. in type safe languages(java) assumptions will be rarely made but non-type-safe languages(C++) assumptions must be made.
Garbage collection algorithms.
1. Reference counting.
This is one of the oldest garbage collection algorithms(1976).
It requires to keep a count of the number of inward references to a chunk, either in the chunk or an external table.
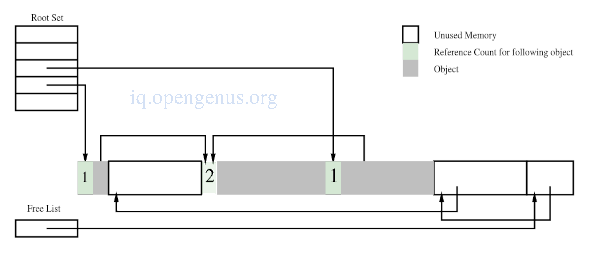
When the last reference to a chunk is removed, the chunk is unreachable by the mutator and is considered garbage.
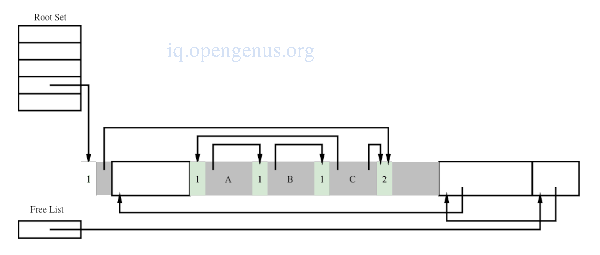
From the image we can see that the reference counting algorithm will be unable to collect circular structures since all chunks in these structures will still have inward references but are unreachable by the mutator.
Hybrids of reference counting have been proposed to enable the collection of circular structures.
Pros and cons of reference counting.
- No sweeping of chunks therefore demonstrates very good performance in a paged environment.
- No run-time information is required.
- Expensive assignment
- Cannot detect circular structures.
2. Mark and Sweep.
This algorithm has two phases namely, the marking phase where all reachable chunks are marked reachable and a collection phase/sweep where all unreachable chunks are reclaimed.
This algorithm works by traversing the stack to find pointers in the heap then follows each of them marking them reachable, in the next stage it sweeps through memory collecting unmarked objects into a free list leaving marked objects.
It is invoked when there is limited space for a requested allocation.This algorithm runs the risk of a fragmented memory which translates to poor performance because objects are never moved once allocated.
The cost of this algorithm is proportional to the available memory.
Since its first implementation, improvements and optimizations have been made, such as division of chunk size for efficiency.
Various implementations use a time stamp to mark chunks mutated during a long making phase which allows both the mutator and collector free access to the heap.
Pros and cons of mark and sweep.
- Reclaims circular structures.
- Chunks are swept twice, during marking and during sweeping.
- Unable to defragment memory.
3. Mark and compact.
This is a variant of mark-sweep that solves the problem of memory fragmentation by compacting reachable chunks in the collector phase to remove space between them.
This algorithm is not useful if the relocated objects are destroyed.
After marking
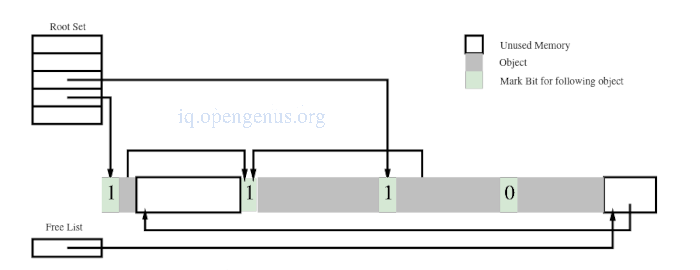
After non-compacting sweep
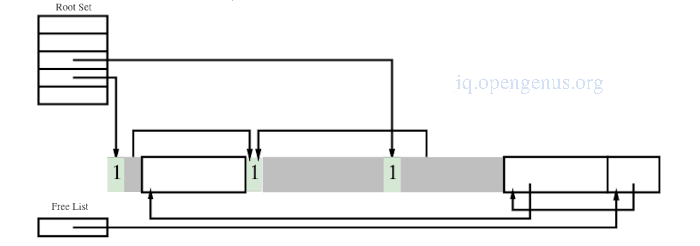
After compacting sweep
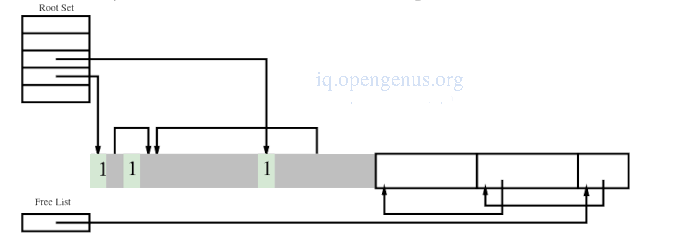
Steps
- Trace objects and mark and sweep.
- Identify sections with fewer objects.
- Move these objects into a linear region.
Pros and cons.
- Can reclaim circular structures.
- Defragmentation of memory.
- Its incremental variants require mutator checks on chunk referencing during the collection cycle.
4. Semi Space.
This algorithm will divide the heap into two contiguous areas called from-space and to-space.
In each garbage collection cycle all reachable chunks will be traced an copied from the from-space to the to-space.
Garbage collection begins with a flip that renames the from-space to the to-space and the to-space to the from-space.
A fixed number of chunks are copied, usually from the from-space to the to-space, each time a new chunk is allocated.
If the chunk being pointer to has not yet been copied, space is reserved for it in the to-space
A garbage collection cycle ends when all chunks have been copied.
New chunks are allocated in the two-space and when the to-space is full another garbage collection cycle starts.
If the semi-space garbage collector is incremental, that is, it only copies a portion of chunks before returning control to the mutator, then the mutator is responsible for determining which copy of the chunk to use(from-space or to-space).
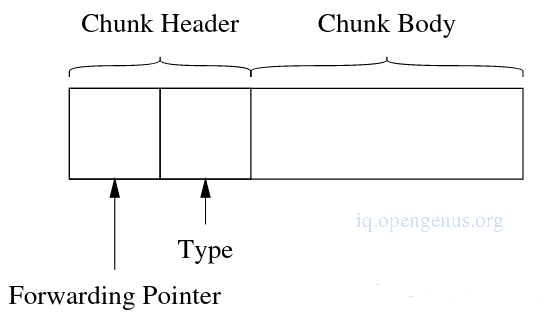
The value of the forwarding pointer in the chunks header is used to determine the copy of the chunk to use and requires a level of indirection every time a chunk is referenced by the application during garbage collection only until chunks have been copied.
Steps taken for an incremental semi-space copying algorithm.
Header structure.

The image below is an image of the heap at the beginning of the cycle
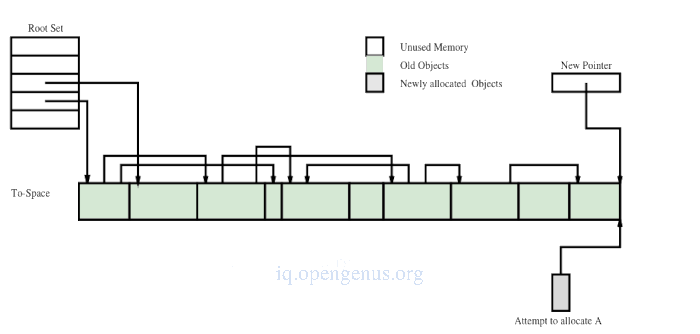
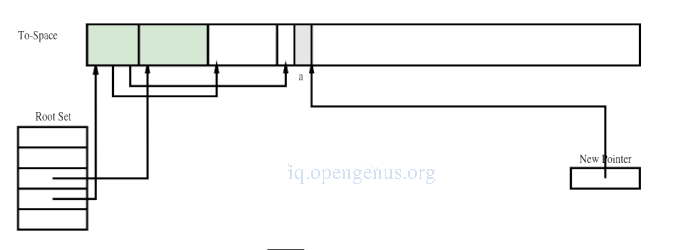
Heap after copying the first two chunks.

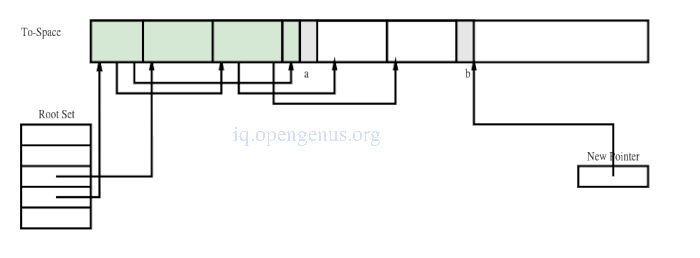
Heap after copying the first four chunks.

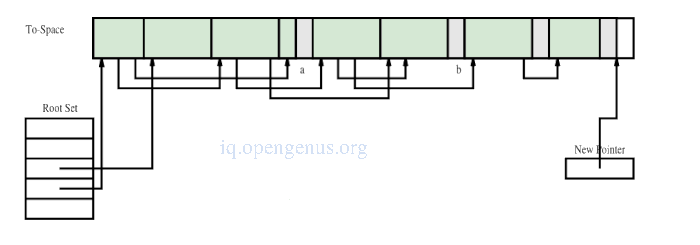
Heap at the end of cycle.

Pros and cons.
- Ability to defragment memory.
- Reclaiming of circular structures.
- It requires a run-time type system.
- Live chunks are swept at least once, at most twice during collection.
- Incremental variants require mutator checks on chunk references during the collection cycle.
5. Treadmill algorithm.
This algorithm converts the semi-space copy algorithm to a non-copying algorithm at the cost of not defragmenting memory thereby saving the costs of copying areas of memory.
It avoids defining semi-spaces as contiguous ranges of memory and optimally uses a circularly doubly linked list to create logical spaces.
Pros and cons.
- Inability to defragment memory
- Operations are performed in constant time
6. Generational algorithm.
These algorithms use spaces to hold objects based on their age.
Youngest chunks(newer generation) are managed similarly to semi-space garbage collections.
After surviving a fixed number of cycles, chunks are promoted to the older generation. A higher proportion of objects in the younger chunks will die with each cycle since they are smaller and thus less work is required.
A list of inter-generational references is held enabling older generations to be managed separately.
Treatment of older generations will differ across different implementations.
A generational implementation that uses train ordering algorithm which is an elaboration of reference counting will group chunks into ordered disjoint sets 'trains' such that circular structures will be grouped in the same train.
When the last reference is removed, the train is reclaimed.
This algorithm although useful faces drawback such as poor handling of popular chunks, slow garbage collection in case of misguided promotion criteria.
Pros and cons.
- Ability to defragment memory.
- Ability to reclaim circular structures.
- Incremental variants require mutator checks on chunk referencing during a cycle.
- Requires a run-time type system.
- Sweep youngest generation chunks at least once and most of them twice per cycle.
Summary.
We now know what is garbage collection and its usefulness in compilers, We also visualized garbage collection as a graph traversal algorithm so as to be able to apply graph traversal algorithms such as depth first and breadth first search.
We have given in detail the 4 main garbage collection algorithms, their pros and cons.
References.
- garbage collection algorithms in java
- Modern Compiler Design Dick Grune Part IV.