
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article, we discuss 5 models for parallel programming and how they are expresses in parallel programming languages.
Table of contents.
- Introduction.
- Parallel programming models.
- Summary.
- References.
Introduction.
Parallel and distributed systems have multiple processors that communicate with each other and therefore programming languages used in such systems express concurrency and communication.
Multiple processors give rise to new problems for the language interpreter.
A parallel system will have the goal of solving a given problem as fast as possible by using multiple processors which cooperate to solve a problem.
They mainly feature applications that require huge amounts of compute time.
A distributed system will have many processors but unlike the parallel system, it will work on other different tasks.
A distributed system can also be used as a parallel system i.e by scheduling different jobs on different resources or running a parallel program on many distributed resources at the same time.
A distributed system offers fault tolerance in that if one component breaks other components will take over the tasks of the broken component, it can also be extended incrementally such that new components are integrated into the system seamlessly.
Examples of distributed systems are grids, which will have many computing and shared data resources across different organizations, computational clouds, which provide remote resources that can be hired by users.
Multiprocessors and Multicomputers.
The architecture of a system is an important factor in compiling parallel and distributed programs.
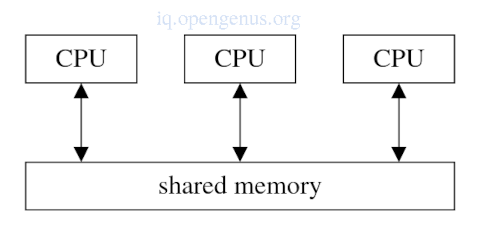
Multiprocessor
Processes in different processors run in shared address space.
All processors will have access to a single shared memory.
These processors exchange information by reading and writing variables in the shared memory space.
To simply construct a multiprocessor we can connect multiple processors onto a single bus.
Modern processors are multiprocessors as they have multiple cores which communicate through shared memory/caches.
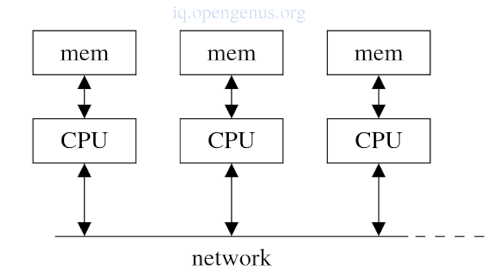
Multicomputer
These consist of multiple processes which are connected by a network.
Processes in different processors run on different address space.
Processors in a multicomputer communicate by sending messages over the network which can either be custom made for the multicomputer e.g IBM blue gene or a LAN e.g ethernet, myrinet or infiband.
A cluster is a multicomputer built of of off-the-self processors.
We can combine both multicomputer and multiprocessors into a single system by connecting multiple computer nodes using a network whereby each computer node is a PC with multiple processors and cores.
Parallel programming models.
A parallel programming model is responsible for providing support for existing parallelism, communications and synchronization between parallel tasks.
There are numerous models for parallel programming models and languages, in this section we focus on the 5 important models;
These are;
- shared variables
- message passing
- objects
- tuple space
- data-parallel programming
Shared variables and message passing are more focused on providing low level communication mechanisms for the underlying hardware while objects, tuple space and data-parallel programming are focused on providing high level communication expressed at a higher level of abstraction.
Implementation of parallel programming languages comes in the form of a large run-time system rather than compiler support e.g parallel programming systems such as PVM or MPI are implemented as libraries linked with a program written with a traditional programming language e.g C or FORTRAN.
This goes to show that these systems don't need direct compiler support and as such a programmer becomes responsible for making the correct library calls since there is no compiler to check the calls.
Mistakes such as incorrect library calls may occur e.g a process sending an integer value when a floating point is expected, this type error won't be caught and results in an incorrect program behavior.
Other programming systems consisting of complex run-times are designed as extensions to existing programming languages and often implemented by a compiler that will check for errors.
In languages with implicit parallelism, the programmer is required to use statements to coordinate parallel activities e.g message passing. On the other hand in languages with implicit parallelism the compiler will try to make the program parallel, such compilers are referred to as heroic compilers are are hard to construct.
The boundary between the OS and run-time system is not clearly defined as primitives such as processes and communication can be implemented by both.
Moving functionality from OS to the run-time system demonstrate advantages such as, saving of expensive interactions with the OS which gives the compiler more control over the implementation of the functionality.
1. Shared Variables and Monitors.
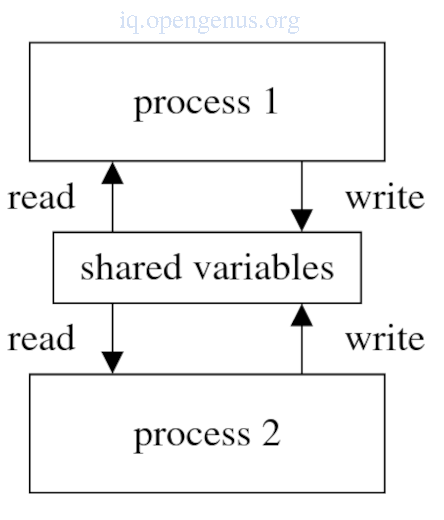
A process is an abstraction of a physical processor, It executes code sequentially.
The simplest form of parallel programming can be thought of a collection of these processes communicating through shared variables.
Conceptually, a process consists of a virtual processor which provides the processing power and address space(an abstraction of physical memory) to store data.
Creating a new process.
fork sort(A, 1, 10)
The fork statement forks off a copy of sort() as a new processes while passing three parameters is used to create a new process, we obtain parallelism by creating multiple processes.
In a shared-variable programming model part of the address spaces of the processes overlap therefore multiple processes end up sharing variables(shared variables).
Shared variables can be read and written by these processes and therefore provide a means of communication between processes.
A problem with this model is synchronizing access to these variables. If two processes simultaneously try to change a variable this will lead to an inconsistent unpredictable data structure.
An example of two processes simultaneously incrementing shared variable X.
X: shared integer;
X := X + 1
If X's initial value is 5, and two processes increment it, the obtained value will be 7. If however both processes read the value and increment, the obtained value will be 6, In this case the value 6 is assigned twice instead of being incremented twice.
Synchronization primitives are used to prevent this type of behavior by mutual exclusion synchronization whereby only one process can access a shared variable at any given time.
Lock variable is an example of such a primitive that has indivisible operations to acquire (set) and release the lock. If a process tries to acquire an acquired lock, it will block until the lock has been released.
An example of using lock variables
X:shared integer;
X_lock: lock;
Acquire_Lock(X_Lock);
X := X+1;
Release_Lock(X_Lock);
Only one of the process will be able to execute the increment statement at any given time.
This method is low-level and prone to errors e.g If a shared variable is not protected by a lock a program can still behave incorrectly.
A monitor is a high-level solution to the above problem. A monitor is an abstract data type in that will contain data and operations to access data.
Data encapsulated by a monitor will be shared by multiple processes and thus allow one operation inside the monitor any given time.
Condition synchronization is another form of synchronization where by a process is blocked until a condition occurs.
In monitors condition variables such as wait() and signal() are used to express this synchronization.
wait(c) on a condition variable c will block the invoking process and signal(c) wakes up the process.
An example of a monitor
monitor BinMonitor;
bin: integer;
occupied: Boolean:=false;
full, empty: Condition;
operation put(x: integer);
begin
while occupied do #wait if the bin already is occupied
wait(empty);
od;
bin := x; # put the item in the bin
occupied := true;
signal(full); # wake up a process blocked in get
end;
operation get(x:out integer);
begin
while not occupied do # wait if the bin is empty
wait(full);
od;
x := bin; # get the item from the bin
occupied := false;
signal(empty); # wakeup a process blocked in put
end;
end;
put() operation blocks if bin contains data.
get() operation blocks if bin does not have any data.
When operations wake up after blocking, they check bin status.
2. Message passing.
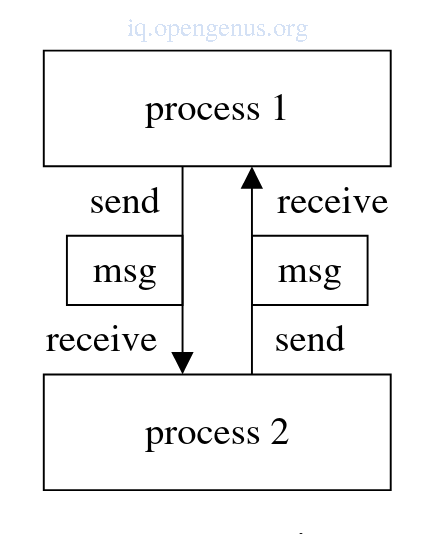
Intended for programming shared memory multiprocessors or machines with physical shared memory.
In this model each process accesses its own local data.
Processes exchange data by sending messages to each other.
send statement and receive statements are primitives used for this model.
An example
process 1:
send message to process 2;
process 2:
receive message from process 1;
The first process sends a message to the second process.
Receive() blocks the second process until the message has arrived.
In low-level systems, the message is an array of bytes, in higher-level systems it is a record-like structured value with different fields.
In this basic model, sender and receiver will specify the name of each other however we can add more flexibility by letting the receiver accept any messages sent by a process in the program.
This is useful when receiver doesn't know who will send the next message.
We can add flexibility by avoiding specifying process names and using port names, that is, a message sent to a port is delivered to a process that issues a receive statement with the corresponding port.
In Synchronous message passing the sender waits until the receiver accepts a message so as to continue the sending process.
In Asynchronous message passing the sender will continue immediately after the sending process.
In some programming languages the receiver can for example a receiver may specify messages it will accept or the order of handling messages if it receives multiple messages.
An example
# accept small sized messages.
receive print(size, text) suchthat size < 4096;
#order messages incrementally
receive print(size, text) by size;
Implicit receipt is whereby a new thread(a light-weight subprocess with its counter and stack) is created for every incoming message.
The thread executes a message handler(a routine for each type of message) defined by the programmer after which it terminates.
Multiple threads can be executing in a single process and thus share the global variables of the process.
Threads can also be used for communication between processes whereby a separate thread is created for this.
3. Objects.
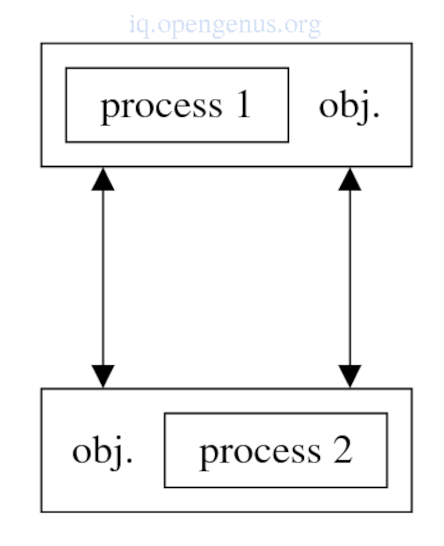
The key ideas in object oriented programming are encapsulation, polymorphism and inheritance.
Data encapsulated within an object can be only be accessed through operations/methods defined in the object.
OOP results in well-structured programs which can scale by the reuse of components.
These and many more advantages are just as important for parallel programming as for sequential thus the interest for parallel object oriented programming languages.
To implement parallelism we allow several objects to execute parallelly on different processors by letting a process execute inside the object.
Objects can invoke operations in another object's remote processors as a form of message passing.
Synchronous invocations will wait until the operation has been executed while asynchronous invocations continue immediately.
Receiving objects can accept invocations implicitly or explicitly.
A process inside an object can consist of multiple threads of control.
A popular model is whereby one thread executes the main process of the object and additional threads are created for each invocation of an operation.
A monitor is used for synchronizing these threads.
4. Linda tuple space.
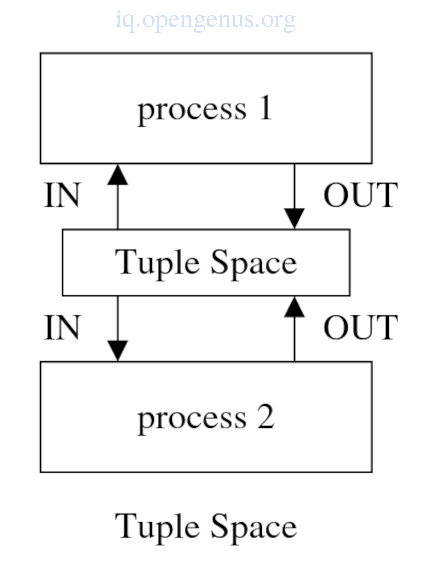
The Linda system is a set of primitives that can be added to an existing sequential language resulting in a new parallel language.
The tuple space was designed as part of the Linda system.
Some parallel languages with this model include C/Linda, Lisp/Linda.
The tuple space is regarded as a box of tuples that can be accessed by all processes regardless of the processors on which they run on.
In this sense it acts as a shared memory.
Operations in the tuple space are;
- Out which adds a tuple to the tuple space.
- Read which reads a matching tuple in the tuple space.
- In which reads a matching tuple in the tuple space and simultaneously remove the tuple from the space.
An example
out("item", 4, 5.48);
The code snippet in C/Linda will generate a tuple with 3 fields(string, integer, floating point number) and deposits it in the tuple space.
Read() and in() search for a tuple in the tuple space by specifying the actual parameter (an expression passed by the value) or a formal parameter(variable preceded by '?' passed by reference).
An example
float f;
in("item", 4, ? &f)
The code snippet specifies two actual parameters(string and integer) and a formal parameter(float) and tries to find a tuple T with three fields such that actual and formal parameters in the call have the same types and values as the corresponding tuple T fields.
If the above process, tuple matching, finds a tuple T, formal parameters in the call get values of the corresponding tuple fields of T and tuple T is removed from the Tuple space.
out("item", 4, 5.48)
If more than one tuple exists, one is selected arbitrarily, if no matching exists, call to in() or read() is suspended until a process adds a matching tuple.
Tuple space primitives are indivisible operations in that if two processes simultaneously try to be in the same tuple, only one succeeds and the other will block.
For modification of a tuple, the tuple is taken out of the space, modified and put back which provides mutual exclusion synchronization in the tuple space.
An example of incrementing '4' in the previous tuple above
int n;
float f;
in("item", ? &n, ? &f);
out("item", n + 1, f);
We remove the tuple from the tuple space.
Increment the tuple and put it back using the second statement.
5. Data-parallel languages.
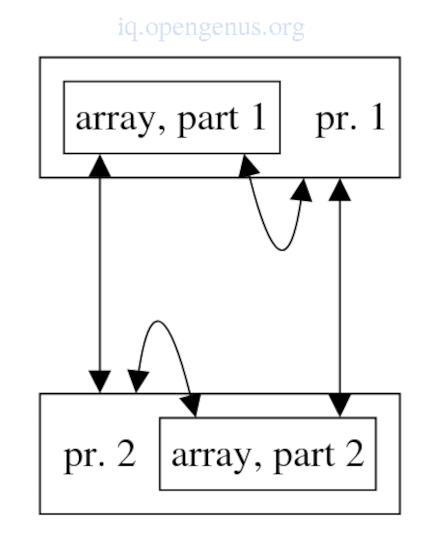
In data parallelism processors operate on different parts of the data set(usually and array) while executing the same algorithm.
Task parallelism contrasts data parallelism whereby in a parallel program using processes, different processes will execute different algorithms.
Data parallelism is more restrictive, less flexible but easier to use since a single algorithm will be defined for all processors.
To approach this, the programmer will define what is to be executed parallelly and the compiler be left to distribute computations and data among different processors.
The parallel loop statement is the simplest explicit language construct used for data-parallel-programming.
An example of matrix multiplication following data parallelism
partfor i := 1 to N do
partfor j := 1 to N do
C[i, j] := 0;
for k := 1 to N do
C[i, j] := C[i, j] + A[i, j] * B[j, k];
od;
od;
od;
The two outer loops are executed in parallel while the compiler will distribute the computations over the available processors.
Data-parallel program provide a simpler structure and therefore easier analysis by the compiler.
Summary.
The goal of parallel systems is to solve a given problem as fast as possible by utilizing multiple processors e.g a distributed system that contains multiple autonomous processors connected by a network and work on multiple different tasks.
We have discussed five models for parallel programming which are shared variables, message passing, shared objects and tuple space and data parallelism
References
- Parallel computer architectures (PDF) from the teachers at University of Macedonia in Thessaloniki, Greece.
- Distributed Systems (PDF) by Eero Vainikko from University of Tartu in Estonia.
- Modern Compiler Design Dick Grune Kees van Reeuwijk Henri E. BalCeriel J.H. Jacobs Koen Langendoen Second Edition Chapter 14.