
In this article, we discuss the third phase in compiler design where the semantic consistency of the code is validated.
Table of contents:
- Introduction.
- Semantics.
- Semantic Errors.
- Declarations.
- Processing declarations.
- Actions performed during semantic analysis.
- Limitations of CFGs.
- Syntax Directed Definition(SDD).
- Syntax Directed Translation(SDT).
- Attributes.
- Types of Attributes.
- Synthesized Attributes.
- Inherited Attributes.
- Attribute grammar.
- Defining an Attribute Grammar.
- Abstract Syntax Trees(ASTs).
- Implementing Semantic Actions during Recursive Descent parsing.
- Roles of this phase.
- References.
Introduction.
This is the third phase in compiler design where by the semantics used in a program are validated to ensure correctness.
Semantic analysis involves a collection of procedures which are called at appropriate times by the parser as the grammar requires.
These semantics are clear and consistent with the way in which data types and controls structures are supposed to be used.
A semantic analyzer will use information stored in the syntax tree and symbol table to check the source program's semantic consistency according to the language definition.
The output of this stage is a representation of the program in either object code in the case of one pass compilers or intermediate representation of the program in the case of other compilers.
An example of semantic analysis;
float a = 12.5;
float b = x * 4;
In this case the integer 4 will be type-casted to 4.0 so that multiplication can occur.
Semantics.
The semantics of a language provide meaning to the language constructs such as its tokens and syntax structure.
Semantics can be either static or dynamic.
Static Semantics
These are the program semantics that don't change, they are declared before their and are checked at compile time.
Dynamic Semantics
These are semantics that live, move and exist during the runtime of the program.
They define the meaning of different units of a source program such as statements and expressions.
Semantic Errors.
Semantic errors, also called logic errors are errors that arise when a statement used in a program is not meaningful, that is, it does not correspond the the set of rules(semantics) for that language being used.
These can be;
- Type mismatch.
- Multiple declaration of variables in a scope.
- Undeclared variables.
- Access of an out of scope variable.
- Actual and formal parameter mismatch.
- Misuse of reserved identifier.
Question? Can you spot the semantic error here?
int x = "value"
Types an declarations.
These are divide into 3 main categories which are base types, compound types and complex types.
Base types.
These are primitive types provided directly by the hardware such as int, float, double, char, bool.
Compound types.
These are types constructed as aggregations of the base types and simple compound types.
They include arrays, records, structs, unions, pointers, classes.
Complex types.
These are abstract data types, a high level language may or may not support these types, in the case they are not supported, a programmer may opt to construct the needed type.
They include, lists, queues, trees, heaps, tables, stacks.
Processing declarations.
Types are stored in a symbol table before any type checking can occur.
When processing the program's header statement;
- The program's identifier is assigned the type program.
- The current scope pointer is set to point the the main program.
If the language allows user-defined data types, installation of these data types must have occurred in the symbol table entries for the declared identifiers.
These identifiers are then added to the abstract syntax tree.
Actions performed during semantic analysis
-
Type Checking.
This will ensure that data types are used in a consistent according to their definitions. -
Label checking.
This ensures that label references are used in the program. -
Flow control checks.
Ensures that control structures are used in the right way, e.g, ensuring in a loop, a break statement only happens inside the loop. -
Scope resolution.
This involves determining the scope of a name. -
Array-bound checking.
This is determining whether all array references in a program are within the declared range.
Limitations of CFGs.
Context free grammars deal with syntactic categories rather than specific words.
The declare before use rule requires knowledge which cannot be encoded in a CFG and thus CFGs cannot match an instance of a variable name with another.
Hence the we introduce the attribute grammar framework.
Syntax directed definition.
This is a context free grammar with rules and attributes.
It specifies values of attributes by associating semantic rules with grammar productions.
An example
| Production | Semantic Rule |
|---|---|
| E → E1 + T | E.code = E1.code |
Syntax Directed Translation
This is a compiler implementation method whereby the source language translation is completely driven by the parser.
The parsing process and parse tree are used to direct semantic analysis and translation of the source program.
Here we augment conventional grammar with information to control semantic analysis and translation. This grammar is referred to as attribute grammar.
The two main methods for SDT are Attribute grammars and syntax directed translation scheme
Attributes.
An attribute is a property whose value gets assigned to a grammar symbol.
Attribute computation functions, also known as semantic functions are functions associated with productions of a grammar and are used to compute the values of an attribute.
Predicate functions are functions that state some syntax and the static semantic rules of a particular grammar.
Types of Attributes
Type - these associate data objects with the allowed set of values.
Location - may be changed by the memory management routine of the operating system.
Value - These are the result of an assignment operation.
Name - These can be changed when a sub-program is called and returns.
Component - data objects comprised of other data objects. This binding is represented by a pointer and is subsequently changed.
Synthesized Attributes.
These attributes get values from the attribute values of their child nodes.
They are defined by a semantic rule associated with the production at a node such that the production has the non-terminal as its head.
An example
S → ABC
S is said to be a synthesized attribute if it takes values from its child node (A, B, C).
An example
E → E + T { E.value = E.value + T.value }
Parent node E gets its value from its child node.
Inherited Attributes.
These attributes take values from their parent and/or siblings.
They are defined by a semantic rule associated with the production at the parent such that the production has the non-terminal in its body.
They are useful when the structure of the parse tree does not match the abstract syntax tree of the source program.
They cannot be evaluated by a pre-order traversal of the parse tree since they depend on both left and right siblings.
An example;
S → ABC
A can get its values from S, B and C.
B can get its values from S, A and C
C can get its values from A, B and S
Expansion.
This is when a non-terminal is expanded to terminals as per the provided grammar.
.Reduction..
This is when a terminal is reduced to its corresponding non-terminal as per the grammar rules.
Note that syntax trees are parsed top, down and left to right
Attribute grammar
This is a special case of context free grammar where additional information is appended to one or more non-terminals in-order to provide context-sensitive information.
We can also define it as SDDs without side-effects.
It is the medium to provide semantics to a context free grammar and it helps with the specification of syntax and semantics of a programming language.
When viewed as a parse tree, it can pass information among nodes of a tree.
An Example
Given the CFG below;
E → E + T { E.value = E.value + T.value }
The right side contains semantic rules that specify how the grammar should be interpreted.
The non-terminal values of E and T are added and their result copied to the non-terminal E.
An Example
Consider the grammar for signed binary numbers
number → signlist
sign → + | −
list → listbit | bit
bit → 0 | 1
We want to build an attribute grammar that annotates Number with the value it represents.
First we associate attributes with grammar symbols
| Symbol | Attributes |
|---|---|
| number | val |
| sign | neg |
| list | pos, val |
| bit | pos, val |
The attribute grammar
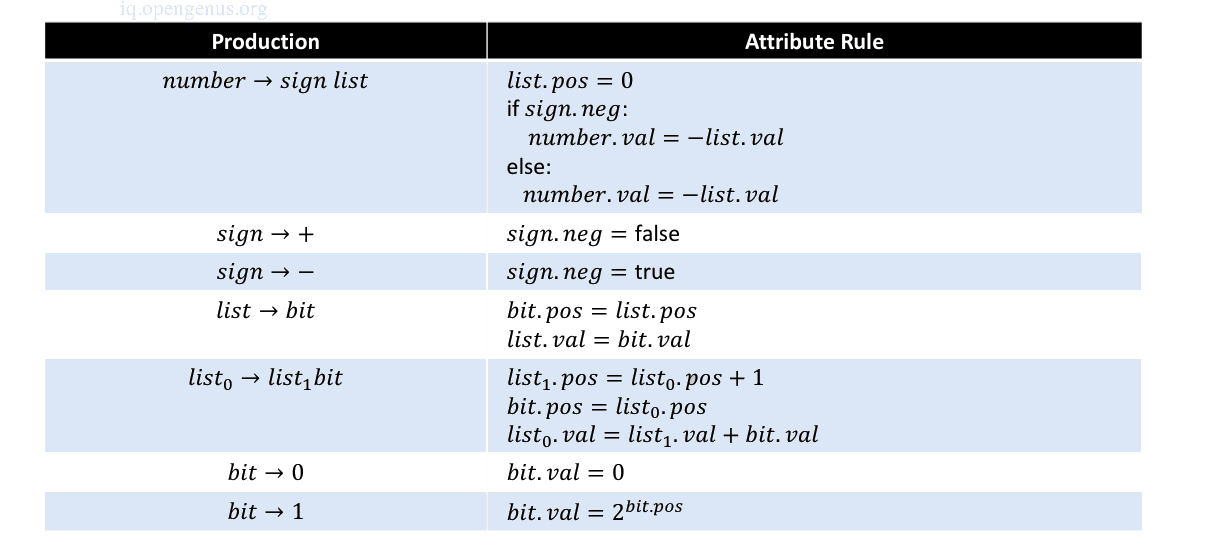
Defining an Attribute Grammar.
Attribute grammar will consist of the following features;
- Each symbol X will have a set of attributes A(X)
- A(X) can be;
- Extrinsic attributes obtained outside the grammar, notable the symbol table
- Synthesized attributes passed up the parse tree
- Inherited attributes passed down the parse tree.
- Each production of the grammar will have a set of semantic functions and predicate functions(may be an empty set)
Based on the way an attribute gets its value, attributes can be divided into two categories; these are, Synthesized or inherited attributes.
Abstract Syntax Trees(ASTs).
These are a reduced form of a parse tree.
They don't check for string membership in the language of the grammar.
They represent relationships between language constructs and avoid derivations.
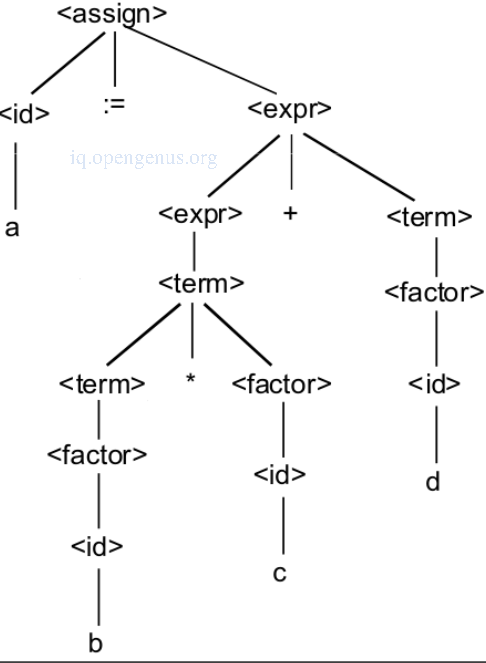
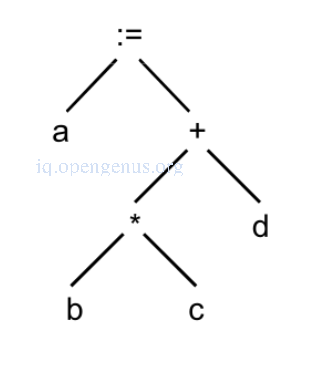
An example
The parse tree and abstract syntax tree for the expression a := b * c + d is.
The parse tree
The abstract syntax tree
Properties of abstract syntax trees.
- Good for optimizations.
- Easier evaluation.
- Easier traversals.
- Pretty printing(unparsing) is possible by in-order traversal.
- Postorder traversal of the tree is possible given a postfix notation.
Implementing Semantic Actions during Recursive Descent parsing.
During this parsing there exist a separate function for each non-terminal in the grammar.
The procedures will check the lookahead token against the terminals it expects to find.
Recursive descent recursively calls procedures to parse non-terminals it expects to find.
At certain points during parsing appropriate semantic actions that are to be performed are implemented.
Roles of this phase.
- Collection of type information and type compatibility checking.
- Type checking.
- Storage of type information collected to a symbol table or an abstract syntax tree.
- In case of a mismatch, type correction is implemented or a semantic error is generated.
- Checking if source language permits operands or not.
References.
- Introduction to Compilers and Language Design 2nd Edition Prof. Douglas Thain chapter 7.