
In this article, we learn about types and the storage layouts for names declared within a procedure or class which are allocated at run time when the procedure is called or an object is created.
Table of contents.
- Introduction.
- Type expressions.
- Type equivalence.
- Declarations.
- Storage layout for local names.
- Sequences and declarations.
- Records and classes fields.
- Summary.
- References.
Introduction.
Applications of types are grouped under checking and translation. First type checking is used to reason about the behavior of a program at runtime by using logical rules.
In applications of translation, given the type of a name, the compiler can determine the storage needed for the name during runtime.
In this article, we learn about types and storage layouts for names declared within classes or procedures. The storage procedure call or an object is allocated during runtime when the procedure is called or when the object is created.
Type expressions
Types have a structure we will represent using type expressions, a type expression can either be formed by applying a type constructor operator to a type expression or can be a basic type.
Basic types are determined by the language that is being checked.
An example;
We have an array of type int[2][3] that is read as array of 2 arrays of 3 integers each. It is written as a type expression as follows; array(2, array(3, integer))
We represent it as a tree as shown below (1);
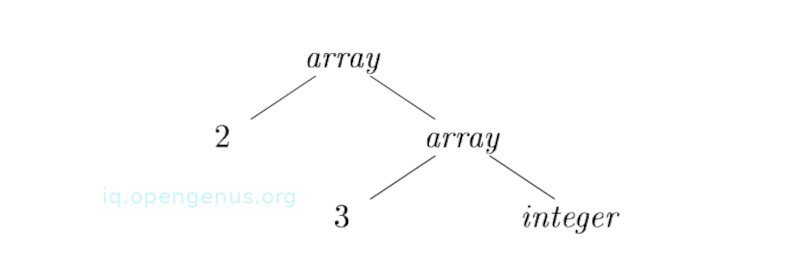
The following definitions are used for type expressions;
- A basic type expression. These include, boolean, char, integer, float and void.
- A type name is a type expression.
- A type expression is formed by applying an array type constructor to a number and type expression.
- A record is a data structure with named fields. A type expression is formed by applying the record type constructor to the fields' names and their types.
- A type expression is formed by using the type constructor → for function types. That is, we write s → t for 'function from type s to type t'.
- If s and t are type expressions, their cartesian product s x t is a type expression.
- Type expressions may contain variables whose values are type expressions.
Type equivalence
Type-checking rules are of the form; 'if two type expressions are equal then return a certain type, else return an error'.
When similar names are used for type expressions and other subsequent type expressions, ambiguities arise.
The problem is whether a name in a type expression represents itself or represents an abbreviation for another type expression.
When representing type expressions using graphs, we say that two types are structurally equivalent if and only if either of the conditions is true;
- They have the same basic type.
- They are formed by applying a similar constructor to structurally equivalent types.
- One is a type name that denotes the other.
If we treat type names as standing for themselves, then the first two conditions in the definition above lead to the name equivalence of type expressions.
Declarations
We learn about types and declarations using simplified grammar that declares a single name at a time.
We have the following grammar; (2)

The non-terminal D generates a sequence of declarations. Non-terminal T generates basic types, array, or record types.
The non-terminal B generates a basic type either an int or float.
The non-terminal C generates strings of zero or more integers, each surrounded by brackets.
An array type consists of the basic type specified by B followed by array components specified by a non-terminal C. A record type is a sequence of declarations for fields of the record surrounded by curly braces.
Storage layout for local names
Given a type name, we can determine the amount of storage that is needed for the name at runtime. During compile time we use these amounts to assign each name a relative address.
Type and relative addresses are stored in a symbol table entry for the name. Varying-length data such as strings or data whose size cannot be determined until runtime such as dynamic arrays is handled by keeping a fixed amount of storage for a pointer to data.
Assuming that storage is in blocks of contiguous bytes whereby a byte is the smallest unit of addressable memory. Multibyte objects are stored in consecutive bytes and given the address of the first byte.
We have the following SDT(Syntax Directed Translation) that computes types and their widths for basic and array types. (3)

The above SDT uses synthesized attributes type and width for each non-terminal and two variables t and w to pass type and width information from B node in a parse tree to a node fo the production C .
In an SDD(Syntax-Directed Definition), t and w would be inherited attributes for C.
The body of the T-production consists of a non-terminal B, an action, and a non-terminal C that appears on the next line. The action between B and C sets t to B-type and w to B.width.
If B int, B.type is set to an integer and B.width is set to 4 which is the width of an integer.
Similarly, if B float, B.type is float and B.width is 8, which is the width of a float.
Productions for C determine whether T generates a basic type or an array type. If C , then t is C.type and w is C.width.
Otherwise, C specifies an array component. The action for C [num] forms C.type by applying the type constructor array to the operands num.value and .type. For example, the resulting tree structure for applying an array can be seen from the first image.
To obtain the width of an array we multiply the width of an element by the number of elements in an array. If addresses of consecutive integers differ by 4, then the address calculations for an array of integers include multiplications by 4.
These multiplications give opportunities for optimization and therefore the front end needs to make them explicit.
Sequences and declarations
In programming languages such as C and Java, declarations in a single group are processed as a group. These declarations can be distributed within a Java procedure but can still be processed when the procedure s analyzed.
We can use a variable to track the next available relative address.
The following translation scheme(4) deals with a sequence of declarations in the form of T id where T generates a type as shown in image (3).

Before the first declaration is considered, a variable offset that tracks the next available relative address is set to 0.
The value of offset is incremented by the width of the type of x, x is a new name entered into the symbol table with its relative address set to the current value of offset.
The semantic action, within the production D T id, creates a symbol table entry by executing top.put(id.lexeme, T.type, offset). top denotes the current symbol table.
top.put creates a symbol table entry for id.lexeme with T.type and relative address offset in its data area.
The initialization of offset in image (4) is more evident in the first production that appears as;
P {offset = 0;} D
Non-terminals generating referred to as marker non-terminals are used to rewrite productions so that all actions appear at the right ends.
By using a maker non-terminal M, the above production is restated as;
P M D
*M { offset = 0; }
Records and classes fields
The translation of declarations in image (4) carries over to fields in records and classes. Record types are added to the grammar in image (3) by adding the following production;
T record '{' D '}'.
The fields in the record type are specified by a sequence of declarations that are generated by D.
The approach used in image (4) can be used to determine the types and relative addresses of fields as long as we are careful about the following;
- Field names within a record must be distinct, that is, a name can only appear once in declarations generated by D.
- The offset or relative address for a field name is relative to the data area for that record.
Summary.
Graphs are useful for representing type expressions.
Applications of types can be under checking or translation. Checking reasons about the behavior of a program at runtime by using logical rules.
For translation, given the type of a name, the compiler can determine the storage needed for the name during runtime.
References.
- Basics of Compiler Design - Torben Mogensen
- Compilers Principles, Techniques, & Tools - Alfred V. Aho Monica