
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
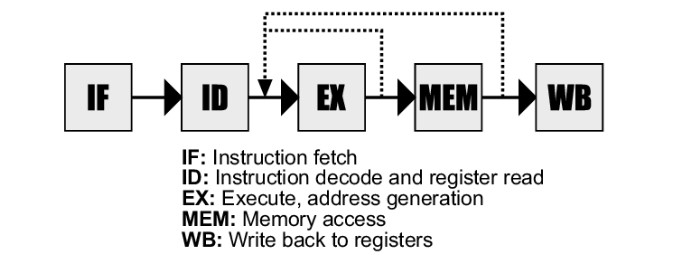
Pipelining is an important concept in CPU optimization and utilization. It is a powerful technique used in modern CPUs to improve their performance and efficiency, but it also requires careful design and management to overcome the challenges and limitations associated with it. Let's dive into the world of Pipelining in CPU optimization and utilization.
Table of Contents:
- Introduction to Pipelining in CPU
- Basic Principles of Pipelining
- Benefits and Drawbacks of Pipelining
- Implementing Pipelining in CPU
- Performance Complexity Analysis of Pipelining
- Real-Life Applications of Pipelining
- Questions
Introduction to Pipelining in CPU
Pipelining is a powerful concept in computer architecture that allows a processor to execute multiple instructions simultaneously by breaking them down into smaller sequential steps, which can then be processed in parallel. It is widely used in modern CPUs to improve their performance and speed by reducing the time it takes to execute instructions.
Before pipelining, CPUs relied on a simple approach called single-cycle execution, where each instruction was executed one at a time. However, this method was inefficient, as it meant that the processor would often remain idle for long periods while waiting for an instruction to complete. Pipelining addressed this problem by dividing the execution of each instruction into multiple smaller stages, with each stage handling a specific task in the instruction execution process.
A pipeline comprises a sequence of stages, with each stage responsible for performing a specific task. The instruction execution process is broken down into stages such as fetching, decoding, execution, memory access, and write-back. When an instruction enters the pipeline, it moves through each stage in a sequential manner, with each stage processing a different instruction simultaneously.
Pipelining has become an essential component of modern CPUs, as it enables faster execution of instructions and higher processing power. However, the effectiveness of pipelining can be limited by factors such as instruction dependencies, branch instructions, and pipeline stalls.
This article at OpenGenus offers an in-depth exploration of pipelining in CPU optimization and utilization. In the previous section, I introduced the fundamental concept of pipelining and its significance in enhancing CPU performance and speed. I also highlighted the inefficiencies of single-cycle execution and how pipelining overcomes them by breaking down instruction execution into smaller stages. In the following sections, I will delve deeper into various aspects of pipelining, including its basic principles, advantages and drawbacks, implementation strategies, performance analysis, real-life applications and questions to test your understanding. By the end of this article, you will have a comprehensive understanding of pipelining and its impact on CPU performance and efficiency.
Basic Principles of Pipelining
Pipelining is a design technique used in CPUs to improve their performance by allowing for the concurrent execution of multiple instructions. Without pipelining, CPUs would have to wait for the current instruction to complete before moving on to the next one, leading to inefficient use of resources.
To overcome this limitation, pipelining breaks down the processing of an instruction into a sequence of smaller, independent steps. Each of these steps can be executed concurrently, allowing multiple instructions to be processed simultaneously. This is done by dividing the CPU's hardware into a series of stages, with each stage dedicated to performing a specific part of the instruction processing.
The stages of an instruction pipeline may vary depending on the CPU architecture, but they generally include the following:
Instruction Fetch: This stage fetches the instruction from memory and loads it into a special register in the CPU.
Instruction Decode: This stage decodes the instruction and determines the operation to be performed.
Execute: This stage performs the operation specified by the instruction.
Memory Access: This stage accesses memory to read or write data, as required by the instruction.
Write Back: This stage writes the result of the operation back to the appropriate register or memory location.
Each stage of the pipeline operates on a separate instruction at the same time. Once an instruction completes a stage, it moves to the next stage of the pipeline, and the next instruction takes its place in the previous stage. This allows multiple instructions to be in various stages of the pipeline at the same time, resulting in a significant increase in overall CPU performance.
Here's an example of a simple implementation of an instruction pipeline in C++:
#include <iostream>
using namespace std;
// Define the stages of the pipeline as functions
void instructionFetch(int instruction) {
// Fetch the instruction from memory
cout << "Instruction " << instruction << " fetched." << endl;
}
void instructionDecode(int instruction) {
// Decode the instruction and determine the operation to be performed
cout << "Instruction " << instruction << " decoded." << endl;
}
void execute(int instruction) {
// Perform the operation specified by the instruction
cout << "Instruction " << instruction << " executed." << endl;
}
void memoryAccess(int instruction) {
// Access memory to read or write data, as required by the instruction
cout << "Instruction " << instruction << " memory accessed." << endl;
}
void writeBack(int instruction) {
// Write the result of the operation back to the appropriate register or memory location
cout << "Instruction " << instruction << " write back." << endl;
}
int main() {
// Example pipeline with two instructions
int instruction1 = 100;
int instruction2 = 200;
// Execute the pipeline stages for instruction1
instructionFetch(instruction1);
instructionDecode(instruction1);
execute(instruction1);
memoryAccess(instruction1);
writeBack(instruction1);
// Execute the pipeline stages for instruction2
instructionFetch(instruction2);
instructionDecode(instruction2);
execute(instruction2);
memoryAccess(instruction2);
writeBack(instruction2);
return 0;
}
In this example, the stages of the pipeline are defined as functions, which take an instruction as a parameter and perform the respective operation. The main function demonstrates how the stages are executed sequentially for two different instructions, simulating a basic instruction pipeline. The output of the program shows which stage is being executed for each instruction. Note that this is a very basic example and in real-world implementations, there are many additional complexities and optimization techniques involved.
Benefits and Drawbacks of Pipelining
Pipelining is a popular technique used in CPU design to improve its performance. Although it offers several advantages, it also comes with some drawbacks that need to be considered.
Advantages of Pipelining
-
Improved performance: Pipelining allows multiple instructions to be executed simultaneously, which leads to an improvement in CPU performance.
-
Better resource utilization: Pipelining keeps all parts of the processor busy, thus improving resource utilization.
-
Increased throughput: Pipelining reduces the time taken to complete a single instruction, thus increasing the overall throughput of the processor.
-
Reduced cycle time: Pipelining breaks down the instruction execution into smaller stages, reducing the cycle time of the processor.
-
Easier hardware design: Pipelining allows the use of simpler and smaller hardware components, making the design of the processor easier.
Disadvantages of Pipelining
-
Pipeline hazards: Pipelining introduces hazards that can cause the processor to stall, reducing the benefits of pipelining.
-
Instruction dependency: Dependencies between instructions can cause delays in pipelining, resulting in reduced performance.
-
Complex design: Pipelining requires a more complex hardware design than non-pipelined processors.
-
Increased power consumption: Pipelining increases power consumption due to the need to keep all parts of the processor active.
-
Cost: Pipelined processors are generally more expensive to design and manufacture than non-pipelined processors.
Therefore, while pipelining can provide significant benefits, it is important to consider these drawbacks and carefully weigh the costs and benefits of using this technique in CPU design.
Implementing Pipelining in CPU
To implement pipelining in a CPU, one needs a thorough understanding of the CPU architecture and instruction set architecture, along with hardware and software design skills. Despite its complexity, the benefits of pipelining, such as increased CPU performance and throughput, make it a valuable technique for modern CPUs.
The hardware and software requirements for implementing pipelining includes
- CPU architecture that supports pipelining
- Instruction set architecture that allows for independent instruction processing
- A hazard detection unit to detect and resolve data dependencies and other hazards
- A branch predictor to predict the outcome of conditional branches
- Compiler support for instruction scheduling and reordering
- Memory hierarchy that supports pipelining, such as cache memories and pipelined memory systems
- A pipeline control unit to manage pipeline stages and their synchronization
- Debugging tools to monitor pipeline performance and detect pipeline stalls and hazards.
To implement pipelining in a CPU, one can follow a step-by-step guide that includes the following steps:
-
Understand the CPU architecture and instruction set architecture to identify the stages of the pipeline and the instructions that can be processed concurrently.
-
Design a pipeline control unit that manages pipeline stages and their synchronization. This unit should control the flow of instructions through the pipeline and ensure that each stage completes its operation before passing the instruction to the next stage.
-
Implement the pipeline stages, such as instruction fetch, decode, execute, memory access, and write-back. These stages should be designed to work independently and be as efficient as possible to reduce pipeline stall times.
-
Develop a hazard detection unit to identify data dependencies and other hazards that can cause pipeline stalls or incorrect results. This unit should be designed to detect hazards as early as possible to minimize their impact on pipeline performance.
-
Implement a branch predictor to predict the outcome of conditional branches and minimize pipeline stalls due to branch mispredictions. This unit should use a combination of hardware and software techniques to improve its accuracy.
-
Use compiler support to schedule instructions and reorder them to minimize pipeline stalls and improve performance. This may involve rearranging the order of instructions or inserting no-operation (NOP) instructions to fill pipeline bubbles.
-
Implement a memory hierarchy that supports pipelining, such as cache memories and pipelined memory systems. This should be designed to reduce memory access times and minimize pipeline stalls due to memory dependencies.
-
Use debugging tools to monitor pipeline performance and detect pipeline stalls and hazards. This will help to identify any bottlenecks or issues that may be affecting pipeline performance and allow for further optimizations.
By following this step-by-step guide, one can successfully implement pipelining in a CPU, thereby improving its performance and throughput.
Here's another sample code snippet in C++ that demonstrates the implementation of a pipelined CPU
// Define the stages of the pipeline
enum PipelineStage {
FETCH,
DECODE,
EXECUTE,
MEMORY_ACCESS,
WRITE_BACK
};
// Define the instruction structure
struct Instruction {
unsigned int opcode;
unsigned int operand1;
unsigned int operand2;
unsigned int result;
};
// Define the pipeline registers
Instruction fetch_register;
Instruction decode_register;
Instruction execute_register;
Instruction memory_access_register;
Instruction write_back_register;
// Define the pipeline control unit
class PipelineControlUnit {
public:
PipelineControlUnit() {
current_stage = FETCH;
}
void run_pipeline_stage() {
switch (current_stage) {
case FETCH:
// Fetch the instruction from memory
fetch_register = fetch_instruction(PC);
// Increment the program counter
PC++;
// Move to the next stage
current_stage = DECODE;
break;
case DECODE:
// Decode the instruction
decode_register = decode_instruction(fetch_register);
// Move to the next stage
current_stage = EXECUTE;
break;
case EXECUTE:
// Execute the instruction
execute_register = execute_instruction(decode_register);
// Move to the next stage
current_stage = MEMORY_ACCESS;
break;
case MEMORY_ACCESS:
// Access memory (if needed)
memory_access_register = access_memory(execute_register);
// Move to the next stage
current_stage = WRITE_BACK;
break;
case WRITE_BACK:
// Write the result back to a register or memory
write_back_register = write_back(memory_access_register);
// Move to the next stage
current_stage = FETCH;
break;
}
}
private:
PipelineStage current_stage;
};
// Define the main function
int main() {
// Initialize the pipeline control unit
PipelineControlUnit pipeline;
// Run the pipeline
while (true) {
pipeline.run_pipeline_stage();
}
return 0;
}
This diagram provides a visual representation of how to implement pipelining in a CPU. The diagram illustrates the addition of pipeline registers between pipeline stages and the modification of the state controller to support the pipeline.
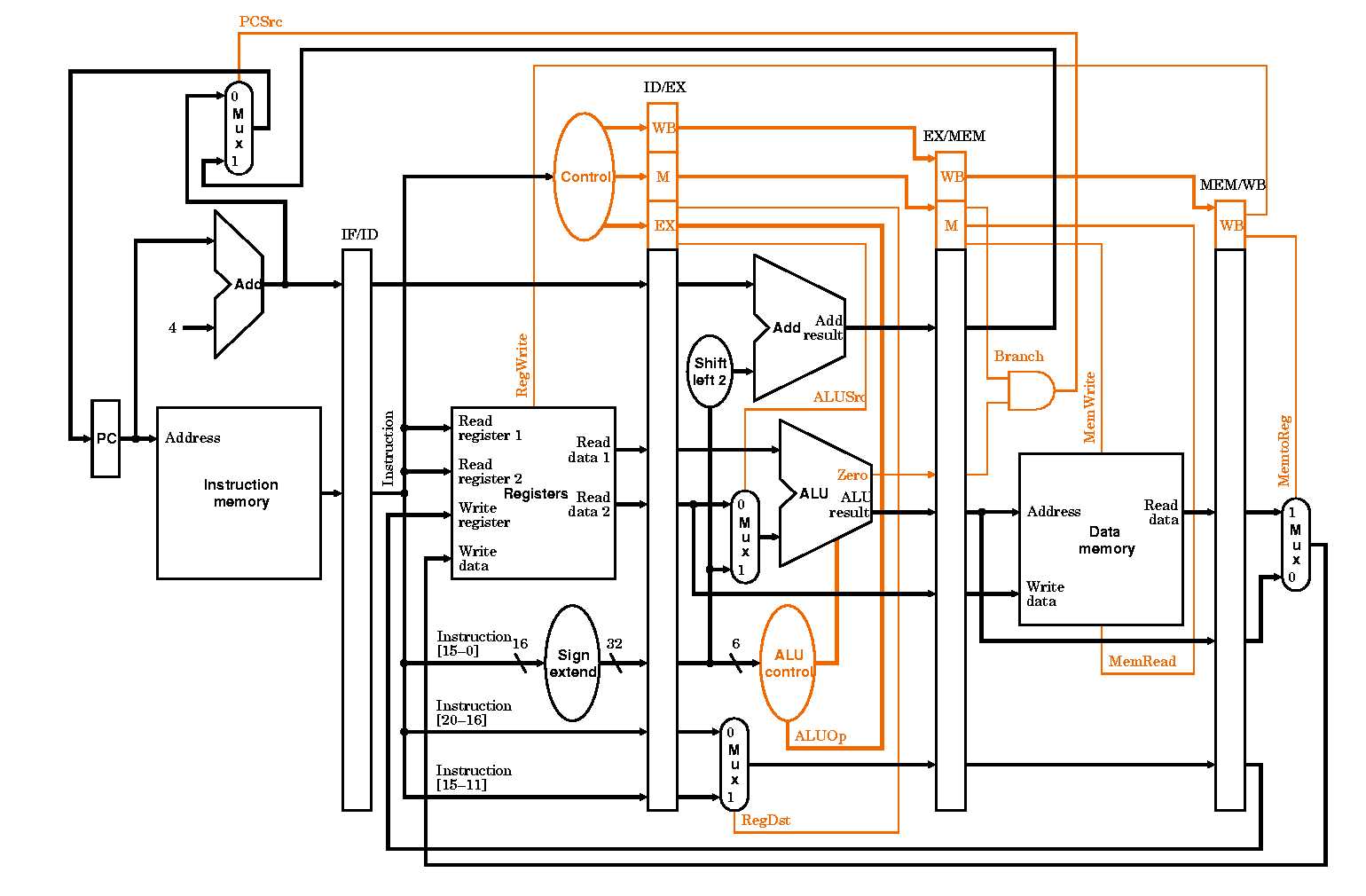
To implement pipelining in a CPU, the following steps can be taken:
- A new instruction word is loaded into the instruction register and is decoded by the control unit.
- The control unit generates control signals that are then routed to the first pipeline stage.
- At each clock cycle, the control signals are copied from the current stage to the next stage through the pipeline registers.
- At each stage, specific control signals are used to direct the flow of data and computation through certain units, such as MUX-es.
By using pipeline registers and modifying the state controller, the CPU can process instructions more efficiently and increase its overall performance. However, implementing pipelining requires a thorough understanding of the CPU architecture and instruction set architecture, as well as hardware and software design skills.
Performance Complexity Analysis of Pipelining
Performance complexity analysis is an important aspect of understanding the impact of pipelining on the performance of a CPU. There are several types of performance complexity analysis that can be conducted to measure the effectiveness of pipelining.
Types of Performance Complexity Analysis
-
Latency analysis: This type of analysis measures the time it takes for a single instruction to complete from start to finish. In a non-pipelined CPU, the entire instruction must be executed before the next instruction can be started. In a pipelined CPU, multiple instructions can be executed simultaneously, reducing the overall latency.
-
Throughput analysis: This type of analysis measures the number of instructions that can be completed per unit of time. In a non-pipelined CPU, the throughput is limited by the latency of each instruction. In a pipelined CPU, the throughput can be increased by overlapping the execution of multiple instructions.
-
Resource utilization analysis: This type of analysis measures the efficiency of the hardware resources used by the CPU. In a pipelined CPU, resources such as registers and execution units are shared by multiple stages of the pipeline, increasing resource utilization.
Measuring Performance with Pipelining
The performance of a pipelined CPU can be measured using several metrics, including:
-
CPI (cycles per instruction): This metric measures the number of clock cycles required to execute a single instruction on average. A lower CPI indicates better performance.
-
IPC (instructions per cycle): This metric measures the number of instructions that can be executed per clock cycle on average. A higher IPC indicates better performance.
-
Speedup: This metric measures the improvement in performance achieved by pipelining compared to a non-pipelined CPU. Speedup is calculated as the ratio of the execution time of a non-pipelined CPU to the execution time of a pipelined CPU.
Overall, pipelining can significantly improve the performance of a CPU by increasing throughput, reducing latency, and improving resource utilization. However, pipelining also introduces additional complexity and overhead, which can lead to decreased performance if not managed properly. Careful analysis and design are necessary to ensure that the benefits of pipelining outweigh the drawbacks.
Real-Life Applications of Pipelining
Pipelining is a technique used in various fields to improve performance and efficiency. In the field of computer architecture, pipelining is extensively used to increase the processing speed of CPUs. Here are some real-life applications of pipelining:
-
Microprocessors: Pipelining is extensively used in the design of microprocessors to improve their performance. Modern microprocessors use multiple stages of pipelining to perform multiple tasks concurrently, which helps to execute instructions at a faster rate.
-
Network Routers: Pipelining is used in network routers to improve packet processing performance. In a router, packets need to be processed quickly, and pipelining can help by dividing the packet processing into multiple stages, each stage being executed concurrently.
-
Industrial Automation: In industrial automation, pipelining is used to improve the speed and efficiency of assembly line production. Assembly line production requires various tasks to be completed in sequence, and pipelining can help by allowing the production process to be divided into smaller stages, each stage being performed concurrently.
-
Image and Video Processing: Pipelining is used in image and video processing to improve the speed of image and video processing. By dividing the image or video processing into smaller stages, each stage can be executed concurrently, resulting in faster processing times.
-
Compiler Design: Pipelining is used in compiler design to improve the performance of the compilation process. By dividing the compilation process into multiple stages, each stage can be executed concurrently, resulting in faster compilation times.
The importance of pipelining in real-world applications is significant as it helps to improve the speed and efficiency of various processes. Pipelining reduces the time required to complete a task and increases productivity. In applications such as microprocessors and network routers, pipelining is essential to achieve high processing speeds. In summary, pipelining is an essential technique used in various fields to improve performance and efficiency.
Questions
This section typically includes an interactive quiz to assess the reader's understanding of the topic. The quiz include multiple-choice questions and this provides an opportunity for readers to clarify their understanding of the topic and deepen their knowledge.
Here are some sample interactive quiz questions on the topic of pipelining in CPUs.
-
What is the purpose of pipelining in a CPU?
a) To process instructions serially
b) To process instructions in parallel
c) To store data in memory
d) To handle interrupts -
What is the main advantage of pipelining in a CPU?
a) Higher clock speeds
b) Reduced memory access times
c) Improved instruction throughput
d) Reduced power consumption -
Which of the following is a stage in the instruction pipeline of a CPU?
a) Fetch
b) Write
c) Read
d) Execute -
What is a potential drawback of pipelining in a CPU?
a) Reduced clock speeds
b) Increased power consumption
c) Increased complexity
d) Reduced instruction throughput -
What is the purpose of a hazard detection unit in a pipelined CPU?
a) To identify data dependencies between instructions
b) To detect hardware failures
c) To predict branch outcomes
d) To manage interrupts
These questions can be further modified or expanded based on the complexity and depth of the article on pipelining in CPUs.