
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Introduction
Cluster indexing is a technique used in database management systems (DBMS) to improve the efficiency of queries involving range searches and sorting. It involves organizing the data in a table based on one or more attributes, called the clustering key. In this article at OpenGenus, we will discuss the two approaches to cluster single level indexing in DBMS.
Table of contents:
- Main file requirements
- Method 1: Continuous blocks referencing first occurrence blocks in main memory
- Method 2: Blocks assigned to each Non-Primary Attribute (NPA)
- Applications of Cluster Indexing
Main file requirements
Before diving into the two approaches, let's first discuss the main file requirements for cluster indexing. The main file should be sorted on the clustering key, and each block in the file should contain a subset of records that have the same clustering key value. Additionally, each block should have a block pointer that points to the next block with the same clustering key value.
Method 1: Continuous blocks referencing first occurrence blocks in main memory
Overview
The first approach to cluster single level indexing involves using the first occurrence in each block as a reference point in the cluster index file. This means that the cluster index file will contain pointers to the first occurrence of each clustering key value in the main file. The rest of the blocks with the same clustering key value can then be accessed by following the block pointers in the main file.
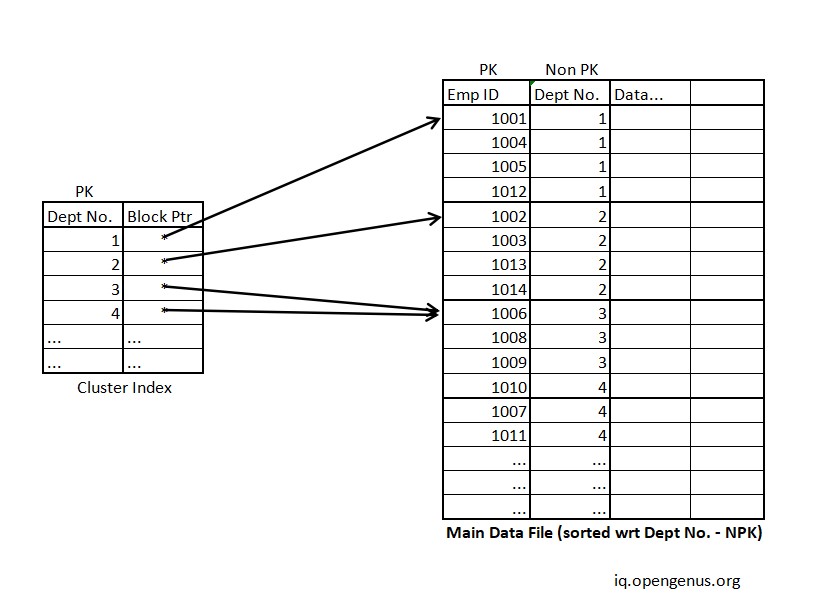
Detailed Explanation with example
Suppose we have a table with the following schema:
CREATE TABLE Employee (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
dept_id INT,
salary FLOAT
);
We want to cluster the table based on the dept_id attribute. The main file will contain blocks with records sorted by dept_id, and each block will contain a subset of records with the same dept_id value. The first occurrence of each dept_id value in the main file will be stored in the cluster index file.
For example, suppose we have the following data:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 1 | Alice | 10 | 50000.0 |
| 2 | Bob | 10 | 60000.0 |
| 3 | Charlie | 20 | 55000.0 |
| 4 | David | 30 | 70000.0 |
| 5 | Emily | 30 | 45000.0 |
| 6 | Frank | 30 | 55000.0 |
Let us assume that the main file will contain three blocks, one for each unique dept_id value:
Block 1:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 1 | Alice | 10 | 50000.0 |
| 2 | Bob | 10 | 60000.0 |
Block 2:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 3 | Charlie | 20 | 55000.0 |
| 4 | David | 30 | 70000.0 |
Block 3:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 5 | Emily | 30 | 45000.0 |
| 6 | Frank | 30 | 55000.0 |
The cluster index file will contain pointers to the first occurrence of each dept_id value in the main file:
| dept_id | block_ptr |
|---|---|
| 10 | 1 |
| 20 | 2 |
| 30 | 2 |
Note that the block referanced for 30 as dept_id will be 2nd block as the first occurance of 30 lies in block 2. We access all blocks starting from the referance id to next dept_id. i.e. If we wished to access all occurances of dept_id = 10 we would access all blocks from refered block in cluster index (block 1) till the block refered by next record of the cluster index i.e. dept_id = 20. This block will also be checked as it cannot be guaranteed that this starts at dept_id = 20. We may have occurances of dept_id = 10 that we must not miss. All blocks beyond this are guaranteed to have no occurances of dept_id = 10 due to the sorted nature of the file.
This approach has the advantage of requiring fewer block pointers in the cluster index file, as each unique clustering key value is only stored once. However, it may not be suitable for cases where the data is frequently updated, as inserting a new record with a clustering key value in the middle of the main file may require shifting all the subsequent records to make room for the new record.
Method 2: Blocks assigned to each Non-Primary Attribute (NPA)
Overview
The second approach involves keeping blocks assigned to one Non-primary Attribute (NPA) and connecting other blocks with the same NPA with a hanger pointer for easier insertion and deletion. This approach requires an additional level of indirection, where the cluster index file contains a list of block pointers for each NPA value. This means that each block in the main file can be assigned to one NPA value, and the cluster index file will contain pointers to the blocks based on the NPA value.
Detailed Explanation with example
This method is somewhat similar to the last one but is optimised for insertion and deletion while bieng wasteful in space.
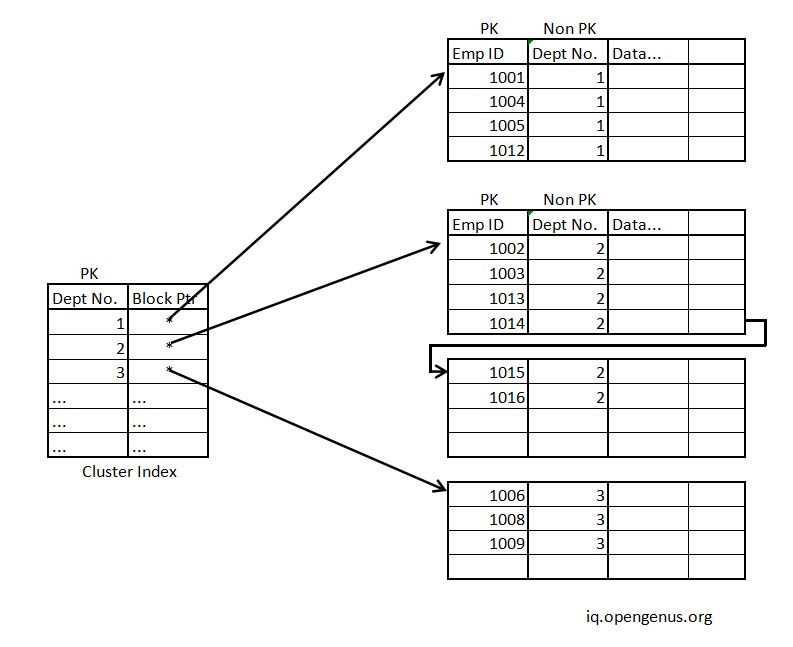
To understand this approach let us take the same example as in method 1:
Main File:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 1 | Alice | 10 | 50000.0 |
| 2 | Bob | 10 | 60000.0 |
| 3 | Charlie | 20 | 55000.0 |
| 4 | David | 30 | 70000.0 |
| 5 | Emily | 30 | 45000.0 |
| 6 | Frank | 30 | 55000.0 |
Main file blocks:
Block 1:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 1 | Alice | 10 | 50000.0 |
| 2 | Bob | 10 | 60000.0 |
Block 2:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 3 | Charlie | 20 | 55000.0 |
Block 3:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 4 | David | 30 | 70000.0 |
| 5 | Emily | 30 | 45000.0 |
Block 4:
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 6 | Frank | 30 | 55000.0 |
Here, the Cluster index would be like:
| dept_id | block_ptr |
|---|---|
| 10 | 1 |
| 20 | 2 |
| 30 | 3 |
NOTE: Block 4 would be connected via a block pointer named hanger pointer as shown for dept_id = 2 in illustration above.
Applications of Cluster Indexing
Cluster indexing has several applications in DBMS. It can improve the performance of queries involving range searches and sorting. For example, if a query involves selecting all the records with a particular clustering key value, cluster indexing can be used to quickly locate all the blocks with that key value. Additionally, cluster indexing can be used to reduce the I/O cost of queries that require accessing large portions of the table, as the blocks with the same clustering key value are stored contiguously in the main file.
In conclusion, cluster single level indexing is an important technique in DBMS that can improve the efficiency of queries involving range searches and sorting. The two approaches discussed in this article, continuous blocks referencing first occurrence blocks in main memory and blocks assigned to each NPA, both have their advantages and disadvantages. It is important to choose the appropriate approach based on the specific requirements of the database application.