
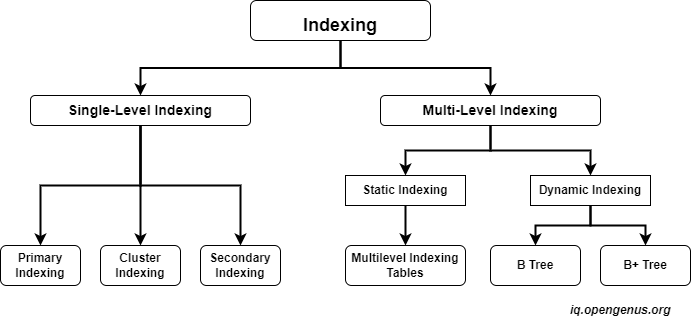
What is Primary Indexing?
Primary indexing is a type of indexing used in databases to improve the speed of accessing data by creating an index based on the primary key of a table. A primary key is a unique identifier for each record in the table, and the primary index is organized in ascending or descending order based on the primary key value.
How Does Primary Indexing Work?
To explain the Primary Indexing in a short and crisp language, Primary indexing is Applied on tables with data that is sorted according to Primary Key (PK).
Let us understand how it works though.
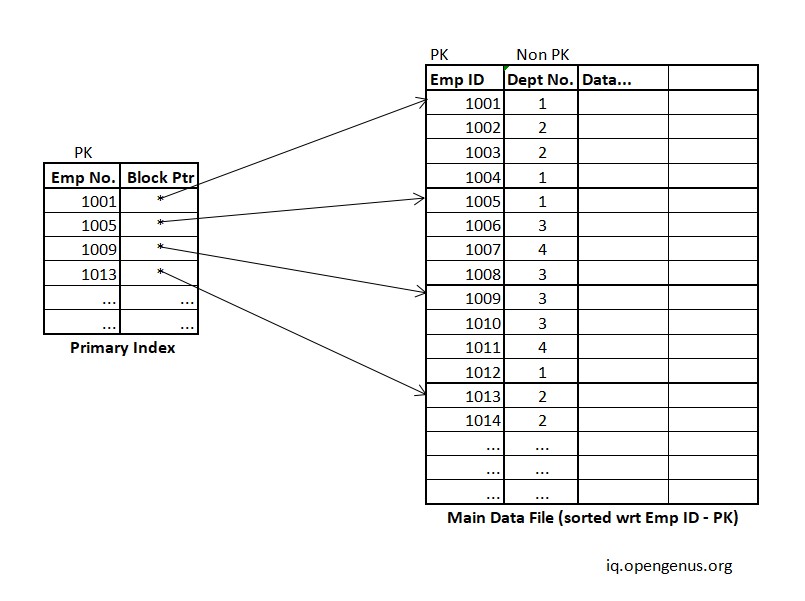
As seen above, the Data is stored as blocks in the main memory as denoted by the thick border box enclosing 4 records inside it in the Main Memory. When the data in table is sorted with respect to its Primary Keys (PK) we can use Primary indexing to access it faster.
In the above example, if we need to find 14 we would need an access to 4 blocks of memory in linear search. This can be reduced using primary indexing where we find the number just smaller than target in the primary index table (here 13) using binary search and only bring that block from memory, now we can use binary search on this block or use linear search based on whichever is preferable. In this case the number of block access or Cost is 2 = 1 for index table (not allways 1, equal to logn(no. of blocks in Primary indexing file) + 1 for bringing block with record 14 from the memory)
(Note: size of Main file record and PI file are different so we cannot directly say that there will be 4 records per block in Indexing table)
But this is how it works in theory, what about Database implementation though?
To understand how primary indexing works, let's use an example of a database table called "Customers." This table contains information about customers, including their ID, name, email, and phone number.
Lets understand this through an example:
| ID | Name | Phone | |
|---|---|---|---|
| 1 | John | john@example.com | (555) 555-1234 |
| 2 | Mary | mary@example.com | (555) 555-5678 |
| 3 | Tom | tom@example.com | (555) 555-9012 |
| 4 | Sarah | sarah@example.com | (555) 555-3456 |
| 5 | Robert | robert@example.com | (555) 555-7890 |
| 6 | Lisa | lisa@example.com | (555) 555-2345 |
| 7 | Mark | mark@example.com | (555) 555-6789 |
| 8 | Emily | emily@example.com | (555) 555-0123 |
| 9 | Jack | jack@example.com | (555) 555-4567 |
| 10 | Alice | alice@example.com | (555) 555-8901 |
In this example, the primary key is the "ID" column. To create a primary index for this table, the database will create an index structure that stores the values of the ID column in sorted order, along with pointers to the corresponding rows in the table.
Here's what the primary index might look like in a simple table:
| ID | Row Pointer |
|---|---|
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
| 4 | 400 |
| 5 | 500 |
| 6 | 600 |
| 7 | 700 |
| 8 | 800 |
| 9 | 900 |
| 10 | 1000 |
In this example, the "Row Pointer" column contains the physical addresses of the rows in the table that correspond to each ID value. The database can use this index to quickly find the row that corresponds to a particular ID value, without having to scan the entire table.
For example, if we wanted to find the row for the customer with ID=5, the database could simply look up the value "5" in the primary index and find the corresponding row pointer "500". It could then use this pointer to retrieve the row from the table at the physical address "500".
Advantages of Employing Primary Indexing?
Primary indexing provides several advantages for databases:
-
Faster access to data: With a primary index, the database can quickly locate the physical address of a row in the table based on its primary key value, without having to scan the entire table.
-
Efficient use of disk space: Because the primary index only contains the primary key values and row pointers, it takes up much less disk space than the entire table.
-
Improved performance for join operations: When joining two tables on their primary keys, the database can use the primary index to quickly match up rows from the two tables without having to scan either table in full. This can greatly improve the speed of join operations.
-
Faster sorting: If a query requires sorting the data based on the primary key, the database can use the primary index to quickly sort the data in the correct order, rather than having to perform a slow sort operation on the entire table.
-
Efficient use of memory: When performing queries that only require a subset of the data, the database can use the primary index to quickly locate the relevant rows and retrieve only those rows from memory. This can greatly reduce the amount of memory required for each query.
Overall, primary indexing is an essential technique for optimizing the performance of database queries, especially in large tables where scanning the entire table can be slow and inefficient. By organizing the data based on the primary key, the database can quickly locate the rows that are needed for each query, resulting in faster and more efficient data access.
Thank you for reading this far, Let's test your knowlege using a question:
Question
Primary Index is made using ____ file with respect to ____ ?
A. Sorted, Foreign Key
B. Unsorted, Primary Key
C. Sorted, Primary Key
D. Unsorted, Foreign Key
Answer: C
Reason: Primary Index is built on a file that is sorted with respect to the unique or Primary.
With this article at OpenGenus, you must have the complete idea of Primary indexing.