
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article, we discuss the language processing system whereby high level code is fed into a series of programs which form a system to produce code that can be understood and executed by the processor.
Table of contents.
- Definitions.
- The language processing system introduction.
- Components of a language processing system.
- Conclusion.
- References.
Definitions.
Preprocessor directives are directives for the preprocessor, the preprocessor resolves these directives before processing begins. e.g #include, define, #undef
Preprocessing involves actions performed before the actual code begins being processed such as getting code from other external files and libraries.
A Cross compiler is a platform that helps in generation of executable code.
Source to source compiler also called transcompiler or transpiler is a translator that takes source code written in one programming language as its input and translates it into an equivalent source code in another programming language.
For this, the programming languages should be operating at the same level of abstraction e.g translating a python source code into javascript source code and not java source code to byte code.
The language processing system.
This is a combination of programs such as preprocessors, compilers, assemblers, loaders and links which work together to convert source code written in a high level language such as java, c++ to executable target machine code.

Components of a language processing system.
1. Preprocessors
When we write code in a high level programming language it first goes to the initial phase inf language processing called preprocessing whereby replacements are made in the source code.
A preprocessor is responsible for making these replacements and preprocessor directives inform the preprocessor what to do.
In the C++ programming language a preprocessor directive starts with '#' symbol
Roles of preprocessor
1. Inclusion of source files
An example
#include<file>
The above directive will tell the preprocessor to insert/include contents of file into the program. With this the program is modified and expanded as if the included code had been written in the current file.
file inside the <> will inform the preprocessor to search for a file in the directory holding header files in the standard library.
#include "file"
"file" in this case will inform the preprocessor to look for the file in the current directory.
2. Macro substitution.
An example
#define MAX 0X86ff
The above directive will inform the preprocessor to replace MAX with 0X86ff.
#undef MAX
the above directive will remove the definition for MAX.
It is conventional to write symbols defined in preprocessor directives in upper case letters.
3. Macro expansion
#define MIN 234
MIN is a macro that holds the value 234, before compilation, the preprocessor replaces MIN by 234 across the whole program.
4. Conditional compilation.
To compile a program conditionally, we can use #if or #ifdef or #ifndef.
An example
#ifdef DEBUG
printf("debugging...")
#endif
The above code will inform the preprocessor to place printf line into source code if the symbol DEBUG is defined otherwise it will exclude it.
With this we decide which part of source code to compile and which part to ignore.
The result of this stage is a compiler.
2. Compiler.
This is a program that reads a high level programming language(source code) and produces an equivalent low level target machine executable code which can be run against various inputs.
A compiler operates in logically interrelated phases whereby source code is translated from one representation and produces output in another representation.
Phases include;
Lexical Analysis: At this first phase the high level program is converted into a sequence of tokens.
Syntax Analysis: Statements, expressions and declarations are identified using the tokens from the previous phase. This phase is aided by programming language grammars. Syntax errors are reported incase they exist.
Semantic analysis: At this phase semantic consistency is validated and semantic errors can be produced if the code is not meaningful.
Intermediate code generation: In this phase an intermediate representation of the final machine code is produced.
Code optimization: Code is optimized inorder to run faster and efficiently
Code generation: The optimized intermediate code is translated into assembly language for a specified machine architecture.
Error handling: At this stage, errors are detect and reported which will enable a programmer to debug a source program by determining where exactly the errors have occurred.
The output of this stage is object code or assembly language.
3. Assembler.
This is a program that will translate an assembly language code into machine code.
Assembly language is a low-level set of instructions intended to communicate directly with the computers hardware.
A programmer may opt to write assembly code for specific instructions.
Assembly language uses opcode for its instructions which give information about an instruction.
Opcode is represented as mnemonics which are easier to read and memorize.
An example:
ADD A,B
The above code instructs the processor to perform an addition of A and B where A, B are its operands.
Advantages of assembly language.
- Easier to debug
- Symbolic addresses
- Can be easily read
- Mnemonics are used for each machine instruction
Types of assemblers.
There are two types of assemblers;
1. One pass assembler.
These assemblers will perform a conversion from assembly code to machine code in on pass hence the name one pass.
2. Multi-pass/Two-pass assembler.
These assembler use an opcode table and symbol table where values from the first pass will be stored.
Machine code is then generated in the second pass.
Steps: 1 (first pass)
- Creation of symbol tables and opcode tables.
A symbol table will store the values of programming language symbols used in the source code and theory corresponding numeric values.
An opcode table stores the value of mnemonics and their corresponding numeric values. - Keep a record of the location counter.
A location counter is a counter which will store the address of the location where the current instruction is being stored. - Processing of pseudo-instructions.
Steps: 2 (second pass)
- Converting opcode into corresponding numeric opcode
- Generation of machine code according to the value of literals and symbols.
Differences between a compiler and assembler.
| Compiler | Assembler |
|---|---|
| The input is a high level source code. | The input is low level assembly code. |
| Produces machine code in the form of mnemonics. | Produces machine code in the form of bits(0s an 1s) |
| Source code is converted to machine code all at once. | Steps are involved to convert source code to machine code. |
| Has 7 phases including error handling. | It has two phases/passes. |
| It converts high level language source code into machine code. | It converts assembly level code into machine code. |
The output at this stage is machine code.
4. Linker.
This is a program that will take a collection of objects which were created from the previous steps and combines them to produce and executable program.
To do this it will search for referenced modules/routines in a source program and find out their memory locations thereby making the program have absolute reference.
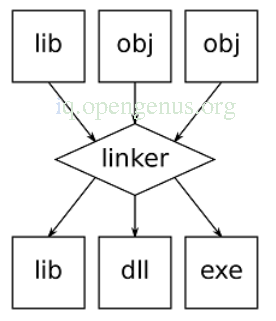
Linking can either be static or dynamic.
1. Static Linking
This is linking performed during compilation of source code whereby linking is performed before the execution of the program.
It is more portable since it doesn't not require libraries however It requires more storage and disk space as compared to dynamic linking.
It generates a fully linked object file that can be loaded and executed against inputs.
Tasks in static linking are;
-
Symbol resolution:
Each symbol will have a predefined task and is associated with exactly one symbol definition from which it belongs to. -
Relocation:
Modification of symbol references to the relocated memory, code and data sections.
2. Dynamic Linking.
This type of linking happens at runtime whereby multiple programs share a single copy of the library, that is, modules having the same object share information of an object with other modules with the same object. This eases on storage and disk space since object wont be repeatedly linked to same library.
Sharing can happen because the needed shared library will be held in a virtual memory which will help to reduce RAM used.
A draw back of dynamic linking is that there are increased chances of errors.
5. Loader.
This is a program that will take input as object code from the linker and load it to the main memory.
This code is then prepared for execution by the machine.
It is responsible for loading programs and libraries to an operating system.
Functions of the loader.
-
Allocation
The loader is responsible for determining and allocating the needed memory space for successful execution of a program -
Reallocation
The loader will map and reallocate address references to correspond to the new allocated memory spaces during execution. -
Loading
It is responsible for loading machine code which corresponds to object modules into the allocated memory space and preparing the program for execution.
Differences between linker and loader
| Linker | Loader |
|---|---|
| Performs linking | Loads program for execution |
| Part of library files | Part of the operating system |
| Generation of executable files from source code | Loading of executable program to memory |
| Combining of object modules | Allocation of addresses to executable files |
Conclusion.
From writing code in a high level programming language to compilation, asembling and linking the optimized code is now understandable to the machine are ready to be executed.