
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article, we discuss the lex, a tool used to generate a lexical analyzer used in the lexical analysis phase of a compiler.
Table of contents:
- Introduction.
- Structure of lex programs.
- Declarations.
- Translation rules.
- Auxilliary functions.
- yyvariables.
- yyin.
- yytext.
- yyleng.
- yyfunctions.
- yylex.
- yywrap.
- A token simulator.
- Conflict resolution in lex.
- Pattern matching using lex.
- Constructing a DFA from a regular expression.
- The lookahead operator.
- Conclusion.
- References.
Introduction.
A lex is a tool used to generate a lexical analyzer. It translates a set of regular expressions given as input from an input file into a C implementation of a corresponding finite state machine.
Upon execution, this program yields an executable lexical analyzer.
The lexical analyzer takes in a stream of input characters and returns a stream of tokens.
It can either be generated by NFA or DFA.
DFA is preferable for the implementation of a lex.

Structure of lex programs.
A lex program has the following structure,
DECLARATIONS
%%
RULES
%%
AUXILLIARY FUNCTIONS
Declarations.
This are instructions for the C compiler.
They are used for include header files, defining global variables and constants and declaration of functions.
They consist of two parts, auxiliary declarations and regular definitions.
They are not processed by the lex tool instead are copied by the lex to the output file lex.yy.c file.
Auxiliary declarations are written in C and enclosed with '%{' and '%}'.
An example of auxiliary declarations
%{
#include<stdio.h>
int global_variable;
%}
An example of Regular definitions
number [0-9]+
op[-|+|*|/|^|=]
Translation Rules.
These consist of regular expressions(patterns to be matched) and code segments(corresponding code to be executed).
An example
%%
{number} {printf("" number");}
{op} {printf(" operator");}
%%
Using the above rules we have the following outputs for the corresponding inputs;
| Input | Output |
|---|---|
| 13 | number |
| + | operator |
| 13 + 17 | number operator number |
Auxiliary Functions.
After C code is generated for the rules specified in the previous section, this code is placed into a function called yylex().
The programmer can also implement additional functions used for actions.
These functions are compiled separately and loaded with lexical analyzer.
An example
/* declarations */
%%
/* rules */
%%
/* functions */
int main()
{
yylex();
return 1;
}
Declarations and functions are then copied to the lex.yy.c file which is compiled using the command gcc lex.yy.c.
yyvariables.
These are variables given by the lex which enable the programmer to design a sophisticated lexical analyzer.
They include yyin which points to the input file, yytext which will hold the lexeme currently found and yyleng which is a int variable that stores the length of the lexeme pointed to by yytext as we shall see in later sections.
yyin.
It points to the input file set by the programmer, if not assigned, it defaults to point to the console input(stdin).
An example
/* Declarations */
%%
/* Rules */
%%
main(int argc, char* argv[]){
if(argc > 1){
FILE *fp = fopen(argv[1], "r");
if(fp)
yyin = fp;
}
yylex();
return 1;
}
yytext.
Each invocation of yylex() function will result in a yytext which carries a pointer to the lexeme found in the input stream yylex().
This is overwritten on each yylex() function invocation.
An example
%option noyywrap
%{
#include <stdlib.h>
#include <stdio.h>
%}
number [0-9]+
%%
{number} {printf("Accept: %d\n",atoi(yytext));}
%%
int main(){
yylex();
return 1;
}
Compilation
lex filename.c
gcc lex.yy.c
./a.out
I/O
Input: 33
Output: Accept: 33
From the above code snippet, when yylex() is called, input is read from yyin and string "33" is found as a match to a number, the corresponding action which uses atoi() function to convert string to int is executed and result is printed as output.
yytext points to the location of the string in memory.
yyleng.
An example
/* Declarations */
%%
/* Rules */
%%
{number} printf(yyleng);
I/O
Input: 549908
Output: 6
The output is the number of digits in 549908.
yyfunctions.
These are yylex() and yywrap()
yylex().
It is defined by lex in lex.yy.c but it not called by it.
It is called in the auxilliary functions section in the lex program and returns an int.
Code generated by the lex is defined by yylex() function according to the specified rules.
An Example
/* Declarations */
%%
{number} {return atoi(yytext);}
%%
int main(){
int num = yylex();
printf("Found: %d",num);
return 1;
}
I/O
Input: 34
Output: Found: 34
When called, input is read from yyin(not defined, therefore read from console) and scans through input for a matching pattern(part of or whole).
When pattern is found, the corresponding action is executed(return atoi(yytext)).
The matched number is stored in num variable and printed using printf().
This continues until a return statement is invoked or end of input is reached
yywrap().
It is defined in the auxilliary function section.
It is called by the yylex() function when end of input is encountered and has an int return type.
If the function returns a non-zero(true), yylex() will terminate the scanning process and returns 0, otherwise if yywrap() returns 0(false), yylex() will assume that there is more input and will continue scanning from location pointed at by yyin.
% option noyywrap is declared in the declarations section to avoid calling of yywrap() in lex.yy.c file.
It is mandatory to either define yywrap() or indicate its absence using the describe option above.
An Example
%{
#include<stdio.h>
char *file1;
%}
%%
[0-9]+ printf("number");
%%
int yywrap(){
FILE *newFilePointer;
char *file2 = "inputFile2.l";
newFilePointer = fopen("inputFile2.l","r");
if(strcmp(file1, file2) != 0){
file1 = file2;
yyin = newFilePointer;
return 0;
}
else
return 1;
}
int main(){
file1 = "inputFile.l";
yyin = fopen("inputFile.l","r");
yylex();
return 1;
}
Compilation
lex filename.c
gcc lex.yy.c
./a.out
Explanation
yylex() scans the first input file and invokes yywrap() after completion.
yywrap sets the pointer of the input file to inputFile2.l and returns 0.
The scanner will continue scanning inputFile2.l during which an EOF(end of file) is encountered and yywrap() returns 1 therefore yylex() terminates scanning.
An complete lex program(token simulator)
%{
#include<stdio.h>
//Identifier and error tokens
#define ID 1
#define ER 2
%}
low [a-z]
upp [A-Z]
number [0-9]
%option noyywrap
%%
({low}|{upp})({low}|{upp})*({number}) return ID;
(.)* return ER;
%%
int main(){
int token = yylex();
if(token==ID)
printf("Accept\n");
else if(token==ER)
printf("Reject\n");
return 1;
}
Compilation
lex filename.c
gcc lex.yy.c
./a.out
I/O
Input: z0
Output: Accept
Input: z
Ouptut: Reject
Explanation
The code will scan the input given which is in the format sting number eg F9, z0, l4, aBc7.
The DFA constructed by the lex will accept the string and its corresponding action 'return ID' will be invoked.
yylex() will return the token ID and the main function will print either Accept or Reject as output.
Conflict resolution in lex.
yylex() function uses two important rules for selecting the right actions for execution in case there exists more than one pattern matching a string in a given input.
1. Always prefer a longer prefix to a shortest one
An example
“break” {return BREAK;}
[a-zA-Z][a-zA-Z0-9]* {return IDENTIFIER;}
In this case if 'break' is found in the input, it is matched with the first pattern and BREAK is returned by yylex() function.
If another word eg, 'random' is found, it will be matched with the second pattern and yylex() returns IDENTIFIER.
2. Always choose the first match.
An example
/* Declarations section */
%%
“-” {return MINUS;}
“--” {return DECREMENT;}
%%
/* Auxiliary functions */
I/O
Input: -
Output: MINUS
Input: --
Output: DECREMENT
Input: ---
Output: DECREMENT MINUS
In the case of '--', yylex() function does not return two MINUS tokens instead it returns a DECREMENT token.
Pattern matching using lex.
The concept of lex is to construct a finite state machine that will recognize all regular expressions specified in the lex program file.
The code written by a programmer is executed when this machine reached an accept state.
A transition table is used to store to store information about the finite state machine.
A transition function that takes the current state and input as its parameters is used to access the decision table.
To view the decision table -T flag is used to compile the program.
Constructing a DFA from a regular expression.
For constructing a DFA we keep the following rules in mind
- Give preference to an existing path.
- Create a new path only when there is no path to use.
The steps involved are as follows.
- Determine the minimum number of states required in the DFA and draw them out.
Here we use the following rule, - We first calculate the length of the substring then all strings that start with 'n' length substring will require a minimum of (n+2) states in the DFA.
- Decide the strings for which the DFA will be constructed for.
- Construct the DFA for the strings which we decided from the previous step
- Don't send left possible combinations over the starting state instead send them to the dead state.
An example.
Given the regular expression ab(a+b)*
Solution
All strings start with the substring 'ab' therefore the length of the substring is 1
The minimum number of states required in the DFA will be 4(2+2)
We construct the DFA using ab, aba, abab, strings.
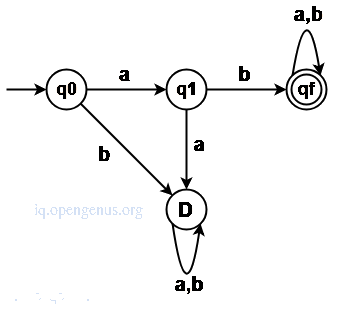
The above steps can be simulated by the following algorithm;
DFA_simulator()
currentState = startState
c = get_next_char()
while(c != EOF)
currentState = transition(currentState , c)
c = get_next_char()
if(currentState ∈ FinalStates)
/*ACCEPT*/
else
/*REJECT*/
Information about all transitions are obtained from the a 2d matrix decision table by use of the transition function.
The lookahead operator.
This is an additional operator read by the lex in order to distinguish additional patterns for a token.
The lexical analyzer will read one character ahead of a valid lexeme then refracts to produce a token hence the name lookahead.
The /(slash) is placed at the end of an input to indicate the end of part of a pattern that matches with a lexeme.
Conflicts may be caused by unreserved keywords for a language,
eg; Given the statements;
IF(I, J) = 5
and IF(condition) THEN,
Conflict may arise whereby a we don't know whether to produce IF as an array name of a keyword.
We resolve this by writing the lex rule for the keyword IF as such
IF^(.*\){letter}
Conclusion
We are now familiar wit the lexical analyzer generator and its structure and functions, it is also important to note that one can opt to hand-code a custom lexical analyzer generator in three generalized steps namely, specification of tokens, construction of finite automata and recognition of tokens by the finite automata.
References
- Introduction to Compilers and Language Design 2nd Prof. Douglas Thain
- Compilers Principles, Techniques, & Tools 2nd Edition.