
Get this book -> Problems on Array: For Interviews and Competitive Programming
Key Takeaways
- Models assume constant patterns, but real-world data changes; monitor for concept drift (shift in relationships) for accurate predictions.
- Data characteristics evolve over time; be vigilant for data drift (distributional changes) to maintain model relevance.
- Utilize monitoring tools to detect shifts in data patterns, ensuring models adapt to changing environments.
- Regularly update models with new data to counter concept and data drift, preserving prediction accuracy.
- Continuously assess feature importance; shifts can indicate changing variables impacting predictions.
- Design models to handle gradual changes; robust architectures better withstand drift challenges for prolonged accuracy.
Table of contents:
- What is Drift?
- What Causes Machine Learning Models to Experience Drift?
- Types of Drift
- Concept Drift
- Data Drift
- Methods for Detecting Data Drift
"Drift" is a concept frequently employed in machine learning to delineate the gradual deterioration in the operational efficacy of a machine learning model over an extended period. Several factors can contribute to this phenomenon, including shifts in the underlying data distribution over time or alterations in the association between the input variables (x) and the target outcome (y).
The challenge of drift becomes particularly pronounced in practical applications of machine learning, where data is characterized by its dynamic and ever-evolving nature.
What is Drift?
Machine learning models undergo training with historical data, yet their real-world deployment can lead to a decline in accuracy over time, a phenomenon commonly referred to as drift. Drift manifests as a gradual transformation in the statistical characteristics of the data employed for model training, thereby introducing potential inaccuracies or deviations from the model's intended performance.
In simpler terms, "drift" signifies the diminishing predictive capability of a model as it encounters alterations in its operational environment.
What Causes Machine Learning Models to Experience Drift?
There exist several factors contributing to the phenomenon of machine learning model drift.
A prevalent factor is the simple fact that the data utilized during the model's training becomes outdated or ceases to accurately represent prevailing conditions.
For instance, envision a machine learning model trained to forecast a company's stock price by drawing from historical data. If this model was trained on data from a stable market, it may initially perform well. However, if market conditions become increasingly volatile over time, the model's predictive accuracy might diminish. This occurs because the statistical properties of the data have undergone significant changes.
Another factor behind model drift arises when the model lacks adaptability to changing data. While certain machine learning models exhibit greater resilience to data shifts than others, no model is entirely immune to the effects of drift.
Types of Drift
Let's explore the two different types of drift to consider:
1. Concept Drift
Concept drift, sometimes referred to as model drift, manifests when the objective a model was originally intended for undergoes alterations over time. Consider this scenario: a machine learning model initially trained to identify spam emails based on their content. If the nature of spam emails evolves substantially, the model may lose its ability to effectively discern spam from legitimate messages.
Concept drift can be subdivided into four distinct categories, as detailed in the study "Learning under Concept Drift: A Review" authored by Jie Lu et al.:
- Sudden Drift
- Gradual Drift
- Incremental Drift
- Recurring Concepts
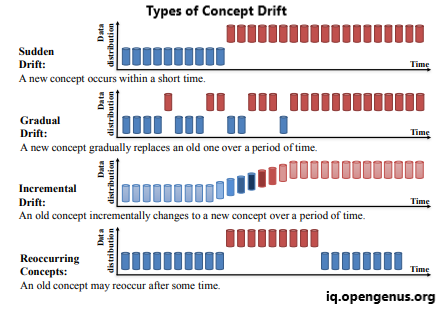
Here's a more detailed explanation of concept drift:
- Data Distribution Changes: Concept drift occurs when the distribution of the input data (features) or the relationship between the input variables and the target variable (often denoted as 'x' and 'y') shifts over time. This means that the patterns, trends, and relationships that the model learned during training may no longer hold in the operational environment.
- Causes of Concept Drift: There are various reasons for concept drift, including:
- Seasonal Patterns: Data may exhibit different patterns or behaviors at different times of the year, leading to seasonal concept drift.
- External Factors: Changes in external factors, such as economic conditions, user behavior, or market dynamics, can cause concept drift.
- Instrumentation Changes: Changes in the way data is collected or measured can affect the data's statistical properties.
- Gradual Evolution: Sometimes, concept drift happens slowly and gradually over time, making it challenging to detect.
- Impact on Models: Concept drift can have detrimental effects on machine learning models deployed in real-world applications. When the model's underlying assumptions no longer hold, it may produce inaccurate predictions or classifications. This can lead to financial losses, poor decision-making, or other undesirable consequences.
- Detecting and Mitigating Concept Drift: To address concept drift, continuous monitoring of model performance in the real-world setting is crucial. Some strategies for dealing with concept drift include:
- Retraining: Periodically retraining the model using more recent data to adapt to the changing patterns.
- Online Learning: Using online learning techniques that can update the model as new data arrives.
- Feature Engineering: Creating robust features that are less sensitive to changes in the data distribution.
- Ensemble Methods: Combining predictions from multiple models to reduce the impact of concept drift.
- Domain Expertise: In many cases, domain expertise is essential for understanding the causes of concept drift and making informed decisions on how to adapt the model to changing conditions.
2. Data Drift
Data drift, also referred to as covariate shift, materializes when there are shifts in the underlying distribution of input data over time. To illustrate, envision a machine learning model initially trained to assess the likelihood of a customer making a purchase, considering their age and income. Should there be substantial alterations in the age and income distributions among customers over time, the model's predictive accuracy could diminish.
It is crucial to remain cognizant of both concept drift and data drift and implement measures to preempt or alleviate their impact. Some tactics for managing drift encompass continuous vigilance and assessment of model performance, regular model updates with fresh data, and the adoption of machine learning models engineered to be more resilient against drift.
Here's a more in-depth explanation of data drift:
- Changing Data Distribution: Data drift occurs when the statistical characteristics of the input data used for model training differ from those of the data encountered in the operational environment. This can include changes in the mean, variance, shape, or other properties of the data distribution.
- Causes of Data Drift:
- Seasonal Variations: Data collected over different time periods may exhibit distinct patterns or characteristics. For example, sales data may have different trends during holidays compared to non-holiday periods.
- Geographical Changes: Data collected from different locations may have variations in distributions. This is relevant for applications like predicting weather patterns or customer behavior.
- Instrumentation Changes: Alterations in data collection methods or instruments can affect the data's statistical properties. For example, a change in the type of sensors used for collecting temperature data.
- External Factors: Shifts in external factors, such as regulatory changes or economic events, can lead to data distribution changes.
- Sampling Bias: Changes in the way data is sampled or collected can introduce bias, leading to data drift.
- Impact on Models: Data drift can lead to model performance degradation. When a machine learning model is trained on one data distribution but encounters a different distribution in the real world, it may produce inaccurate predictions or classifications. This can have practical consequences, such as financial losses or incorrect decisions.
- Detecting Data Drift:
- Statistical Tests: Various statistical tests and techniques can be employed to detect changes in data distribution. These tests assess whether the new data deviates significantly from the training data distribution.
- Visualization: Data drift can often be detected through data visualization techniques that compare the characteristics of new data to the training data.
- Monitoring Systems: Building monitoring systems that continuously track model performance and data distribution can help in early detection of data drift.
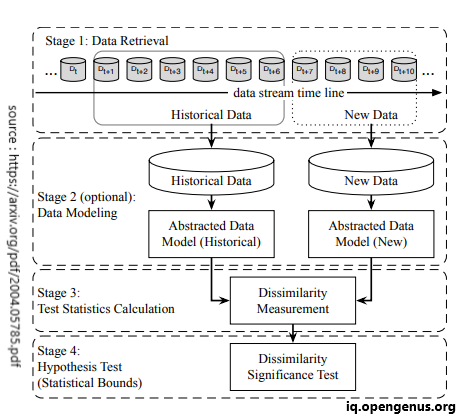
Fig. - General framework for data drift detection - Phase 1 (Data Retrieval) involves gathering data from data streams in chunks. This approach is necessary because a single data point does not contain sufficient information to deduce the entire distribution.
- Phase 2 (Data Modeling) is employed to identify essential features. These features, crucial for determining system impact in the event of drift, are extracted from the data during this stage.
- Phase 3 (Test Statistics Calculation) is dedicated to evaluating drift and computing the necessary test statistics for the hypothesis test.
- Phase 4 (Hypothesis Test) is applied to assess the statistical significance of the observed change measured in Phase 3, often indicated by the p-value.
- Mitigating Data Drift:
- Re-Training: Periodically retraining the machine learning model with recent data to adapt it to the new data distribution.
- Feature Engineering: Creating features that are less sensitive to changes in data distribution can make the model more robust.
- Ensemble Methods: Combining predictions from multiple models trained on different data distributions can mitigate the impact of data drift.
Methods for Detecting Data Drift
- Kolmogorov-Smirnov Test or KS Test: The K-S test is a statistical tool used to assess whether two datasets share the same distribution. It helps determine if a sample aligns with a specific population or if two samples stem from the same population. Rejecting the null hypothesis implies a drift in the model. This test is valuable for comparing datasets and gauging distributional similarities.
- Population Stability Index (PSI): PSI quantifies changes in the distribution of a categorical variable between two datasets. Originally designed for risk scorecards, it now evaluates shifts in all model-related attributes. A high PSI value signals significant distribution differences, potentially indicating model drift. When variables change notably, recalibrating or rebuilding the model may be necessary.
- Page-Hinkley Method: This statistical technique identifies variations in the mean of a data series over time. It is widely employed to monitor machine learning model performance and spot data distribution changes indicative of model drift. The method involves defining a threshold value and decision function. A value of 1 from the decision function indicates detected changes, signaling potential model drift. The Page-Hinkley method is adept at detecting subtle mean changes, but careful threshold and function selection is crucial to prevent false alarms.
In conclusion, concept drift and data drift are crucial considerations in real-world machine learning deployments. To maintain model performance, organizations must continuously monitor their models, collect fresh data, and adapt their models to changing conditions, whether in the relationships between features and labels (concept drift) or in the data distribution (data drift). Detecting drift is essential to ensure model accuracy and reliability in dynamic environments.