
In this article at OpenGenus, we will learn about the concept of Data Pipeline. Data pipelines route raw data from various sources to destination for analysis or visualization. Data pipelines centralize data from disparate sources into one place which give you a more robust view of your customers, create consolidated financial dashboards and more.
Table of contents:
- What is a Data Pipeline?
- What Data Pipelines do?
- Data Pipeline Architectures
- Types of Data Pipelines
- Benefits of Data Pipelines
- Data Pipeline Use Cases
What is a Data Pipeline?
A data pipeline is called a data connector since it acts as the piping for data science projects or business intelligence (BI) dashboards.
A data pipeline is a set of tools and activities that transforms and moves data from a system to another. The two systems might manage and process the same data differently.

A data pipeline gets raw data from multiple data sources, process and transform the data, and then stores in a destination for analysis or visualization.
What Data Pipelines do?
Data pipelines consolidate data from various sources. For example, a company's marketing and commerce stack uses multiple platforms such as Google Analytics and Facebook Pixel, etc, would need a data pipeline to processing and transformation of the unstandardized data into a data storage.
In Addition, data pipelines can feed data from a data warehouse or data lake into operational systems such as a customer experience processing system like Qualtrics. Besides, data pipelines ensure consistent data quality, which is critical for reliable BI.
Data Pipeline Architectures
Data pipeline architectures describe the arrangeent of components to enable extraction, processing and transformation, and delivery and storage of data.
Data pipelines consist of three components:
-
Sources
- Data sources include an internal DB such as SQL or NoSQL (ex, MongoDB, PostgreSQL), a cloud platform such as Salesforce or Shopify, or an external data source such as Qualtrics and Nielsen.
-
Data Transformation
- Data transformation can be done manually using technologies like Apache Airflow or build your own software, or using pre-built tools like Trifacta or dbt.
-
Storages
- Data is deposited in data storages like data lake or data warehouse.
There are 2 common designs of the architectures:
1. ETL Data Pipelines
ETL (Extract, Transform, Load) is the most common data pipeline architecture. It extracts raw data from disparate sources, transform it into a single pre-defined format for standardization, and loads it into a target system for storgage.
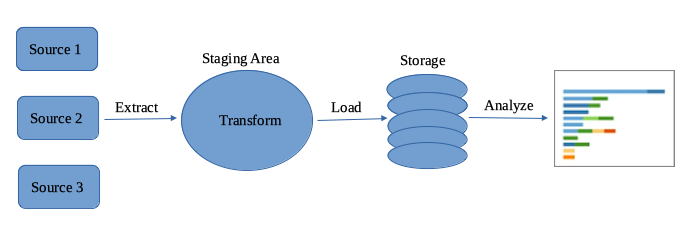
When data is collected from sources, it's usually raw data. Data scientists or data engineers restructure the data through a mix of exploratory data analysis and defined business requirements. Once appropriate data integration and standardization are done, it can be stored and surfaced for use in a range of data projects including exploratory data analyses, data visualizations, and machine learning tasks.
The drawback of the ETL architecture is that a data pipeline needs to be rebuilt every time business rule and data formats change. One remody is the ELT architecture.
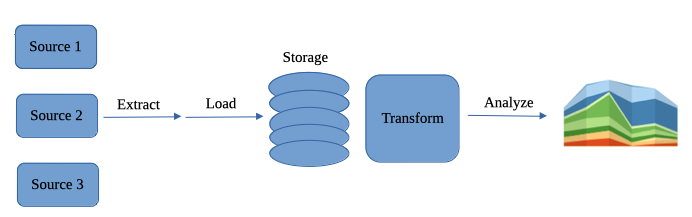
2. ELT Data Pipelines
The steps ELT differs from ETL are loading happens before the transformation. Instead of converting huge amounts of raw data, you first move it directly into a data warehouse or data lake. Then you can restructure your data as needed.
Types of Data Pipelines
There are 5 types of Data Pipelines depending on the kind and flow of data:
(1) Batch Processing Pipelines
Batch processing pupelines are used to transfer a large amount of data in batches. It's not done in real-time and is usually used for extensive systems such as data lakes for later processing and analysis.
(2) Real-Time/Streaming Data Pipelines
Real-Time/Streaming Data Pipelines utilize live-streaming or fluctuating data such as in stock markets to respond swiftly and offer real-time performance monitoring.
(3) Cloud Native Data Pipelines
Cloud Native Data Pipelines utilize cloud technologies to provide a robust infrastructure, higher scalability and more cost-efficiency compared to on-premises data pipelines.
(4) Open-Source Data Pipelines
Open-Source Data Pipelines is no-cost and allow you to edit the source code based on your needs. The downside is it's not very beginner friendly.
(5) Open-Premises Data Pipelines
Open-Premises Data Pipelines have better security and control comparing to its counter-example, cloud-native data pipelines.
Benefits of Data Pipelines
There are at least 5 benefits of adapting Data Pipelines:
1. Flexibility and agility
Data pipelines improve businesses by leveraging extensible, modular, and reusable pipeline structures. They offer agile and immediate provisioning when workloads and data sets grow, enable businesses to quickly deploy their entire pipelines, and simplify access to common shared data, without being limited by a hardware setup.
2. Data centralization and Improved Decision-Making
Data pipelines consolidate various sources, transforme and store store the data in a stroage. It allows an organization to work cross-functionally and ensure data transparency. Bueinss decisions are made quicker and easier from a centralized repository.
3. Data Standardization and Faster Integration
Data pipelines facilitate easier standardization of your data by determining the source, functions, transformations, and destination of data. In addition, data pipelines standardize and streamline the data ingestion process to provide quality data that helps data analysts to evaluate data.
4. Data Security
Security guidelines that protect your data are being setup when you build data pipelines for your organization. You can reuse them when subsequent pipelines and new data flows are being developed.
5. Monitoring and Governance
We can use workflow management systems such as Apache Airflow to monitor numerous data pipelines simultaneously and can scale data operations efficiently.
Data Pipeline Use Cases
Data management becomes crucial as big data continues to grow. The following are the 3 broad applications of data pipelines:
1. Exploratory data analysis (EDA)
EDA analyze data to help data scientists to discover patterns, spot anomalies, test a hypothesis, or check assumptions.
2. Data visualizations
The display of visual charts, plots, infographics, and even animations allow us to communicate complex data relationships and data-driven insights in aan easier way.
3. Machine learning
Machine learning algorithms utilize data to train to make classifications or predictions, uncovering key insights within data mining projects.