
Table of Contents:
- Introduction
- Understanding Large Language Models
- Challenges with retaining LTM
- Working
- Embeddings
- Vector Indexing
- Key Takeaways
Introduction:
In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have become the cornerstone of various applications, from natural language processing to content generation. These models, such as GPT-3 and its successors, demonstrate unparalleled language understanding and generation capabilities. However, the question of long-term memory retention poses a significant challenge. Enter vector databases, the innovative solution reshaping the way LLMs store and access information over extended periods.
Understanding Large Language Models:
Large Language Models, or LLMs, are sophisticated neural networks designed to process and generate human-like text. These models are trained on vast amounts of data, allowing them to capture intricate patterns, context, and linguistic nuances. Context search and semantic search are two important aspects of natural language processing and understanding, and they play a significant role in the capabilities of Large Language Models (LLMs) like GPT-3. Let's delve into these concepts:
-
Context Search in LLMs:
Definition: Context search involves the ability of an LLM to understand and use context from the surrounding text to generate more accurate and contextually relevant responses.
How LLMs Handle Context:
- LLMs like GPT-3 are trained on large datasets that include diverse contexts, allowing them to understand and generate responses based on the context provided.
- The model uses an attention mechanism that gives more weight to certain words or tokens in the input sequence, allowing it to focus on relevant information.
Example:
- If a user asks, "Who is the president of the United States?" and follows up with "Where was he born?" without explicitly mentioning the president's name, a context-aware LLM can infer that the second question is still referring to the same context as the first.
Challenges:
- While LLMs excel in capturing context, they may face challenges in maintaining long-term context, especially when dealing with extensive or complex information.
-
Semantic Search in LLMs:
Definition: Semantic search involves understanding the meaning or semantics behind a query and retrieving results that are conceptually related, even if the exact words or phrases don't match.
How LLMs Perform Semantic Search:
- LLMs leverage their training on vast amounts of data to understand the semantic relationships between words and concepts.
- They use word embeddings and contextual information to grasp the meaning of queries and documents, enabling them to retrieve semantically relevant results.
Example:
- If a user searches for "healthy recipes," a semantic search by an LLM could retrieve results related to nutrition, balanced meals, and cooking methods, even if the exact phrase "healthy recipes" is not present in the documents.
Challenges:
- The success of semantic search in LLMs depends on the quality and diversity of the training data. If the training data lacks coverage of certain semantic relationships, the model may struggle to retrieve relevant information.
The Problem with retaining Long-Term Memory
The main components of LLMs are token-based memory structures and attention processes, which are good at processing information in a sequential fashion but less effective at remembering context throughout large texts or across different types of datasets. As a result, there is a need for a more efficient and scalable solution to serve as the long-term memory for these models, This is where Vector Databases come into the picture.
Vector Databases as the Solution:
Vector databases, designed for storing and retrieving high-dimensional vectors efficiently, are emerging as a groundbreaking solution to the long-term memory challenge for LLMs. Vector databases improve the accuracy of large language models (LLMs) in natural language processing (NLP) in several ways:
Semantic understanding: Vector databases enable LLMs to understand the context and meaning of user queries, leading to more accurate and relevant search results.
Efficient data storage and retrieval: Provides efficient storage and retrieval of vector representations of data, accelerating operations like text similarity matching and sentiment analysis.
Compared to standard databases, vector databases typically require less storage capacity, especially when handling unstructured data. This is a result of their use of sophisticated indexing and search algorithms to manage vast volumes of complicated unstructured data, including text, photos, and videos, by storing data as high-dimensional vectors. These vectors, which are numerical arrays that can represent a variety of unstructured data formats, enable quick and effective similarity searches.
Enhanced memory (Providing Long-term memory (LTM) for LLMs: Vector databases act as external memory for LLMs, allowing them to remember previous interactions and query factual information outside of general knowledge.
Semantic/vector search: Vector databases enable semantic or vector-based searches, allowing LLMs to search data based on meaning instead of just literal matches.
Hence, Vector Databases offer much better solutions than traditional database systems for large scare LLM Applications. Now let's see how vector databases work.
How do they work?
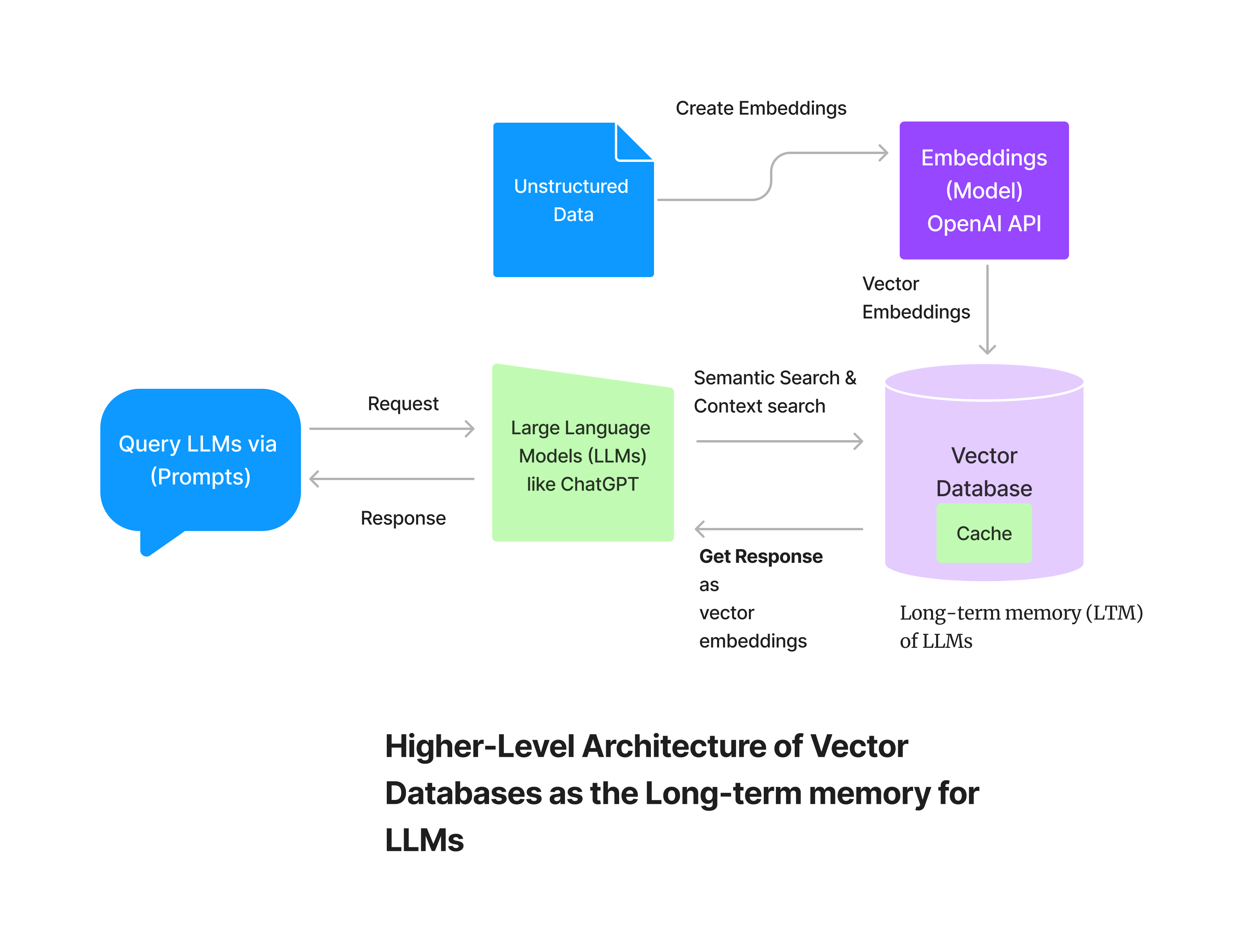
Before getting into Vector databases, you must first understand what are embeddings and how you can create them for your semantic search testing using OpenAI API for Embeddings and single store for storing the vector embeddings.
What are Embeddings?
For a variety of applications, including text analysis and recommendation systems, vector embeddings are numerical representations of data that capture semantic links and similarities. This allows for mathematical operations and comparisons to be performed on the data.
Think of embeddings as data, such as words or images or similar unstructured data converted into numerical arrays known as vectors. These vectors act as multi-dimensional maps, capturing relationships and patterns within the data. In a simplified 2D example, words like "dog" and "puppy" are represented by vectors close together, indicating their semantic similarity. Importantly, embeddings are not limited to words; images can also be transformed into vectors, enabling similarity searches, as seen in Google's image search functionality.
First, for creating the embeddings, we can use the OpenAI API, for that you'll need an API Key. This model takes unstructured data as an input and converts it into arrays of numbers also called vector embeddings using deep learning models. These embeddings are stored in a specialized data structure, called vector index.
Vector Indexing:
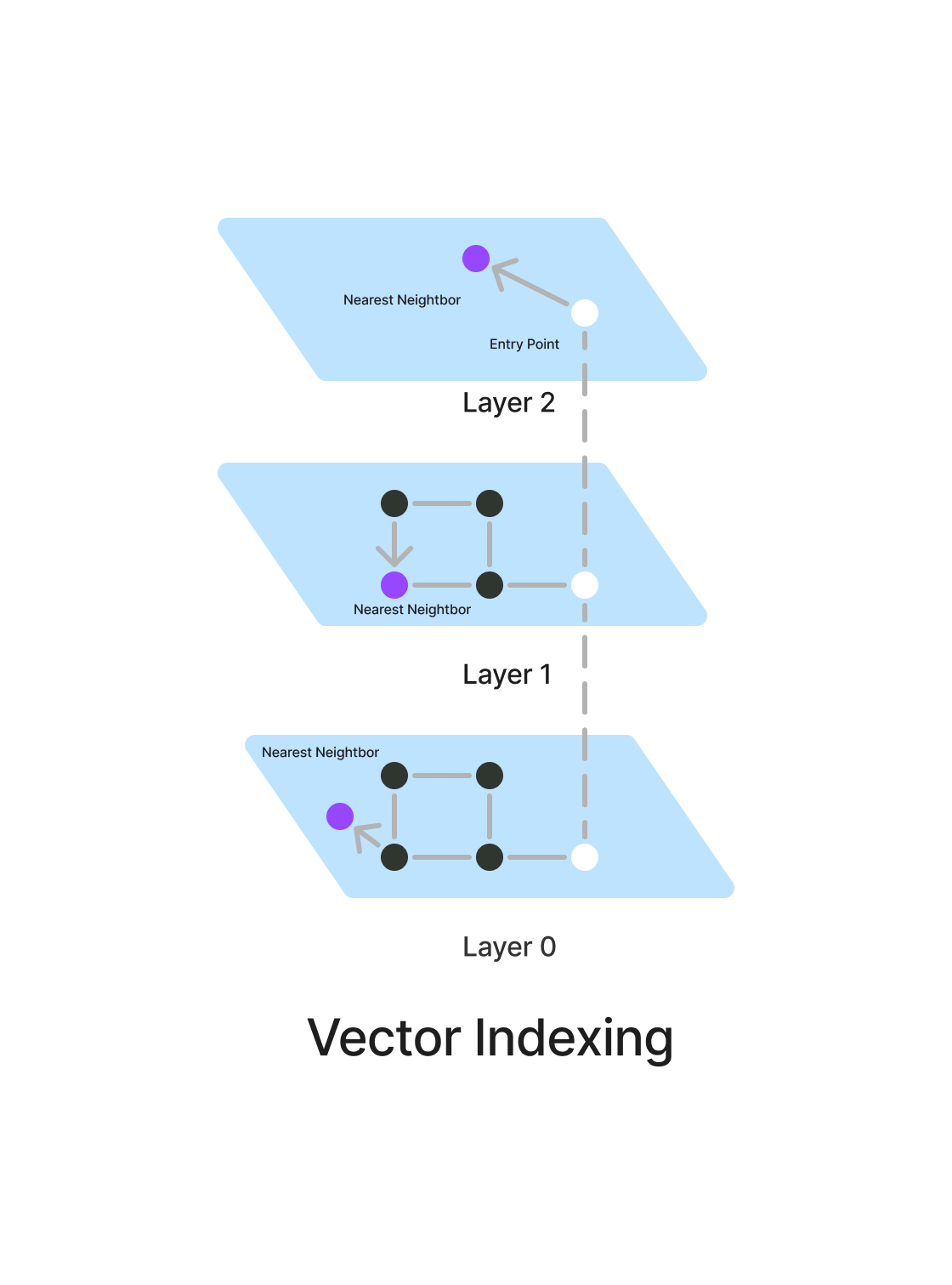
In computer science and information retrieval, a vector index is a data structure that is used to store and retrieve high-dimensional vector data effectively. This allows for quick similarity searches and closest neighbour inquiries. A vector index is a type of data structure that facilitates the precise and expeditious search and retrieval of vector embeddings from an extensive object dataset.
Purpose of indexing vectors
By using a vector index, specific data can be easily found in large sets of vector representations, facilitating a deeper understanding of the data. This is crucial for implementing Retrieval Augmented Generation (RAG) in generative AI applications and is fundamental for enabling AI models to understand and utilize the embedded context. Additionally, vector embeddings can be used to calculate distances between vectors, enabling tasks like de-duplication, recommendations, anomaly detection, and reverse image search. Therefore, indexing vector embeddings is essential for various AI applications, including natural language processing, computer vision, and semantic search etc.
The embeddings can be stored in a vector index, When creating a vector index or storing vector embeddings in a vector database, the vector embeddings are inserted into the index or database, with some reference to the original content the embedding was created from, Forming what is termed a vector database. The database serves various purposes, including searching, clustering, recommendations, and classification.
Now, let's dive into Vector Databases
Vector databases store embeddings of data points in a vector space, allowing for similarity-based search queries. LLMs can encode information into vectors and store them in the database. When faced with a query, the model can retrieve relevant vectors based on similarity scores, thereby accessing information from its long-term memory. This approach provides a more nuanced and context-aware method for LLMs to recall information.
K-Nearest Neighbors (KNN) algorithm is commonly used in vector databases to perform similarity search and retrieval of nearest neighbors.
KNN works by calculating the distance between a query vector and all vectors in the database, and then returning the K vectors that are closest based on some distance metric. This allows vector databases to find similar or related vectors based on their location in the vector space.
So, for instance, let's say a user at first prompts a LLM like ChatGPT and asks a question. This input query is taken as a request by the language model, and it uses semantic search for retrieving related data. It traces vector embeddings that are closely clustered with the input data or keywords in the prompt and provides the words that have the highest probability of being the desired answer. If the user asks a follow-up question, it looks up in the cache for context searching, and if no match is found, it fires up queries for semantic search in its database and provides more accurate search results.
Conclusion:
As Large Language Models continue to advance, the integration of vector databases as long-term memory solutions represents a crucial step forward. The marriage of LLMs and vector databases empowers these models with efficient, scalable, and context-aware memory, opening up new possibilities for natural language understanding, generation, and interaction in the AI landscape. As research and development in this field progress, we can anticipate further refinement and innovation in vector database technology, propelling the capabilities of Large Language Models to unprecedented heights.
Key Takeaways (Vector Databases)
- Introduction to LLMs and Memory Challenges:
LLMs like GPT-3 play a pivotal role in various AI applications but face challenges in long-term memory retention.
- Context and Semantic Search in LLMs:
Context search involves LLMs understanding and using context from surrounding text for relevant responses.
- Vector Databases as Long-Term Memory Solution: By efficiently storing high-dimensional vectors and enhancing semantic understanding for context-awareness and accurate recall.
With this article at OpenGenus.org, you must have the complete idea of vector database.