
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article at OpenGenus, we will learn about the concept of Data Lake. A data lake is a centralized storage repository that holds big data from many sources in different formats. It gives users the ability to effectively make use of more data from more sources. It also gives users control to collaborate and analyze data in many ways which adds values to any organizations.
Table of contents:
- What is a Data Lake?
- Data Lake Architecture
- Pros and Cons of Using a Data Lake
- Data Warehouse vs Data Lake vs Data Lakehouse
- Data Lake Use Cases
What is a Data Lake?
A data lake is a centralized repository that can hold data in its original form. The data can come from cloud, on-premises or edge-computing systems.
A data lake can accommodate all types of data in structured, semi-structured and unstructured formats at any scale without scraficing fidelity.
- Structured format ex. Database tables, Excel sheets
- Semi-structured format ex. XML files, webpages
- Unstructured format ex. images, audio files, tweets
Data Lake Architecture
Note:
The data lake architecture below is a commone-case prototype. Real-world data lake architecture varies from application to application.
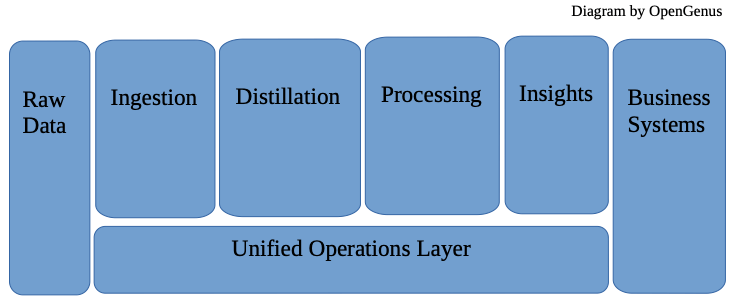
Here is the layers of Data Lake Architecture
Data Ingestion Layer
- This layer is ingested with raw data in batches or in real-time. Modification of raw data is prohibited.
- It extracts data from various sources, such as social networks, IoT devices, websites, mobile apps, and existing Data Management systems, is required. And it can accommodate any types of data from any systems.
Distillation Layer
- This layer converts the data stored by the ingestion layer to structured data and stored as files or tables. The data is transformed to be comsistent in terms of encoding, format and data type.
Processing Layer
- This layer is production-ready because it runs user queries and analytical tools on structured data.
Insights Layer
- This layer is the output interface, or the query interface. It uses SQL or non-SQL queries to request and output data in reports or dashboards.
Unified Operations Layer
- This layer performs system monitoring and manages the system using workflow management, auditing, and proficiency management.
Pros and Cons of Using a Data Lake
Advantages of a Data Lake
A data lake is a cost-efficient way to store a growing amount of data that can function with advanced analytics tools.
- Scalability
- Data lakes keep raw data intact and can handle large data volumes that grow and fluctuate based on data inputs. Organizations that need increasig data storage would benefits from utilizing data lakes.
- Functionality
- Big data analytics tools like ML, AI algorithms, real-time advanced analytics, and predictive modeling work well with data lakes.
- Greater flexibility comes with "Schema on read” rather than “schema on write.” The same raw data can be transformed in different ways based on different needs.
- Low cost
- Open source technologies are used by data lakes. It's cost-effective for organizations and individuals.
Disadvantages of a Data Lake
Poor data management, lack of adequate data quality rules and bad governance could turn data lakes into data swamps with poor data integrity and security issues.
- Complexity
- It takes professionals like data scientists and data engineers to work on the large quantity of data in data lakes. Data scientists may require additional training to successfully mine data from a data lake.
- Data Quality Issues
- Data governance and proper management are needed to take care of the data in a data lake. Otherwise, it turns into a data swamp with unorganized and unusable data that lacks clear identifiers or metadata information..
- Security Risks
- Sensitive data could live in a data lake and be accessed by users who can access the data lake. Security issues and access control problems raise concerns.
Data Warehouse vs Data Lake vs Data Lakehouse
Quick Comparisons
| Data Warehouse | Data Lake | Data Lakehouse | |
|---|---|---|---|
| Storage Data Type | Works well with structured data | Works well with unstructured, semi-structured, structured data | Works well with unstructured, semi-structured, structured data |
| Purpose | Business intelligence (BI) and data analytics | Machine Learning (ML) and Artificial Intelligence (AI) | BI, data analytics, ML and AI |
| Cost | Storage is costly and time-consuming | Storage is cost-effective, fast, and flexible | Storage is cost-effective, fast, and flexible |
| ACID Compliance | Records data in an ACID-compliant manner to ensure the highest levels of integrity | Non-ACID compliance: updates and deletes are complex operations | ACID-compliant to ensure consistency as multiple parties concurrently read or write data |
Data warehouse is the oldest big-data storage technology in business intelligence (BI), reporting and analytics applications. Its disadvantages are expensive and doesn't work well with unstructured data.
Next, data lakes came up to solve the disadvantages of data warehouse. Nevertheless, Data lakes lack of the ACID (Atomicity, Consistency, Isolation, and Durability) transactional features of data warehouses.
Then, data lakehouse emerges. It combines the advantages of data warehouses and data lakes mentioned.
Note:
Although a data lakehouse combines all the benefits of data warehouses and data lakes, the choice of which big-data storage architecture to choose will depend on the type of data your organization needs.
Data Lake Use Cases
- Media and Entertainment
- Streaming music, radio and podcast by companies like Pandora and Spotify. This type of companies also collect and process insighes on cutomer behavior to improve music recommendation algorithms.
- Financial Services
- Powering machine learning when real-time market data is available to manage portfolio risks.
- Sales
- Predictive models are built by data scientists to determine customer behavior and increase customer loyalty.
- IoT
- Semi-structured and unstructured data is generated by IoT sensors every second. It's stored in data lakes for future analysis.