
Reading time: 30 minutes
Kafka is a word that gets heard a lot nowadays, A lot of Digital companies seem to use it as well. But what it is actually?
In basic terms, Kafka is a messaging framework that is intended to be quick, scalable, adaptable, and durable. It is an open-source stream processing system. Apache Kafka started at LinkedIn and later turned into an open-source Apache venture in 2011, and then it became a top-notch Apache Foundation project in 2012. Kafka has improved a lot since then, Nowadays it is a big platform allowing you to store redundantly store absurd amounts of data.
Kafka is developed by Franz Kafka and is written in Scala and Java. It aims at generating a high-throughput, low-latency platform for taking care of constant real-time information feeds.
Apache Kafka is a publish-subscribe messaging system. A messaging system lets you send messages between Processes, Apps and Servers.
Apache Kafka is a software where topics can be defined dynamically (imagine a topic of a Application ) to where applications can add, process and reprocess data ( Messages ).
Applications can connect to this system and transfer the realtime data feeds into these topics. A message can include any kind of information like commit logs, logs generated by a website or it can be anything that needs to be processed in real time. The data you send is stored in RAM or Hard Drive until a specified retention period has passed by. For example kafka is used in:
- commit logs
- Stream processing
- log aggregation systems
as they all need to process data in realtime.

Why Kafka?
In Big Data, a tremendous volume of information feeds are utilized. Regardless, how are we going to assemble this tremendous volume of data and analyse it? To deal this problem, we need a messaging system. That is the main reason why we need Kafka. The functionalities that it gives are well-suited to our requirements, and we use Kafka for:
- Building realtime data applications to respond to the flooding realtime data feeds.
- Building realtime data streaming pipelines that can transfer data between apps and system.
Getting Familiar With kafka
Kafka is a distributed streaming platform that allows us to:
- Publish and subscribe streams of records.
- Store streams of records in a fault-tolerant way.
- Allows various types of compression of data.
- Process streams of data as they occour (~real time)
- Allows Partitoning of data
Features of Kafka
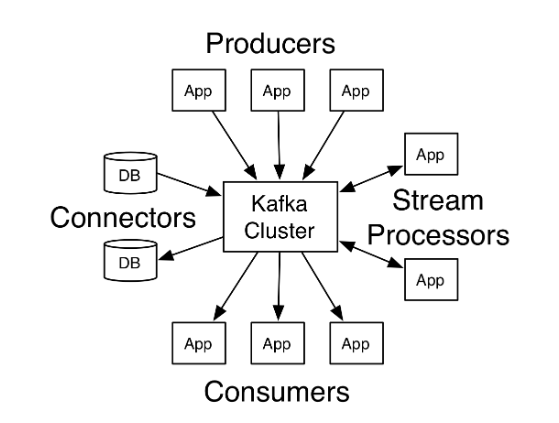
1. Producers:
Producers publish data to the topics of users choice. It isresponsible for electing the optimal record to assign to which partition in the topic.This can be done in a round-robin way simply to balance the load or it can be done according to some semantic partitioning function.
2. Consumers:
Consumers itselves label as a consumer group name, and each record published to a topic are delivered to one consumer within each subscribing consumer group. Consumer instances can be in different processes or on different machines.
If all the consumer instance have similar consumer group, then the records will effectively load balanced over the consumer instances.
3. Distribution:
The partition of logs are distributed over the servers in kafka with each server handling data and requests for the sharing of partitions.
Each partition has a server which acts as the "leader" and rest all servers acts as "follower". Leader handles all read and write requests for each partition while the followers actively replicate the leader. If the leader fails, one of the followers which contains the exact copy of the failed server will automatically become the new leader.
4. Geo-Replication:
Kafka MirrorMaker is a standalone tool which replicates data between two or more apache kafka clusters. Data is read from the topics in the origin cluster and written to a topic with the same name in the destination cluster. You can run as many mirroring processes to increase throughput and fault-tolerance behaviour.
Benefits of using kafka
1. Reliability:
It provides distributed processing, partitioning, replication factor, fault tolerant services. Kafka replicate data several times to provide a fault tolerant support to multiple subscribers.
2. Scalability:
It is a highly scalable messaging que application. It scales easily and quickly without incourring any downtime.
3. Durability:
It is durable because Kafka uses Distributed Commit Logs, which means messages will persist on the disk very fast.
4. Extensibility:
There are variety of ways by a which an application can connect with kafka to generate data. In addition kafka provides various ways to write a connector to establish a connection as needed by the user.
API's used in Kafka
Kafka has its four main core API's :
-
The Producer API allows the application to publish a stream of record to more than one Kafka topics.
-
The Consumer API allows the application to subscribe to more than one topics at a time and process the stream of record produced to them.
-
The Stream API allows the application to act as a stream processor, consuming the input stream from one or more topics and producing the output stream to one or more output topics, effectively transforming the I/O streams.
-
The Connector API allows us building and running producers or consumers that connect Kafka topics to all the existing applications or data systems.
Nuts And Bolts of kafka
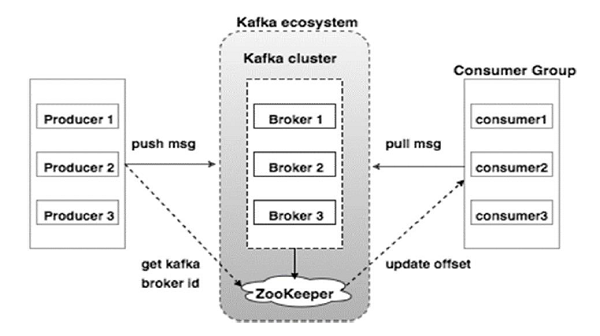
1. Zookeeper
Kafka uses zookeeper to use leadership election of kafka broker and topic partitons. Zookeeper manages and sends all the changes made to the topology of kafka so that each of its node when a new cluster joins them. The main functionn of zookeeper is to track the status of the kafka cluster nodes.
2. Topics
It is simply the named stream of records iswhat we call kafka topic. A topic in kafka is a category, stream name, feed. These topics are broken up in smaller units so as to increase the speed of execution, scalability and size as well.
3. Producers
A Kafka Producer is an application that acts as a source of streaming data from any application in a cluster. In order to genemrate message/tokens and publish it in one or more topics in kafka cluster, we use kafka producers.Producer API packs and send the message to kafka cluster.
4. Consumers
A kafka consumer is an application subscribes to a topic in kafka cluster and then furter feeds on the tokens from kafka topics. It uses a heartbeat protocol to show its availiability to the broker coordinator(zookeeper).
5. Brokers
It is also known as kafka server. Basically a broker is a mediator between the two.
In this case kafka broker is the one who establishes the connection between kafka Producers and Consumers. A single broker of kafka can handle the high read write requests(i.e Thousands of I/O requests per second).
6. Cluster
It is a container in which all brokers coordinates with each other to handle the high read write requests for each topics, partitions.
Architechture of a simple Kafka cluster
Creating a General Single Broker Cluster
Steps :
- Download Kafka ZIP file release 0.10.2.0 from here and extract them
> tar -xvf kafka_2.11-0.10.2.0.tgz
- Start kafka server
> sudo kafka_2.11-0.10.2.0/bin/kafka-server-start.sh kafka_2.11-0.10.2.0/config/server.properties
if kafka server doesn't start, it is possible that your Zookeeper instance is not running. zookeeper should be up as a deamon process by default; we can check that by entering this command in terminal..
netstat -ant | grep :2181
if zookkeeper is not up then we can start it by
sudo apt-get install zookeeperd
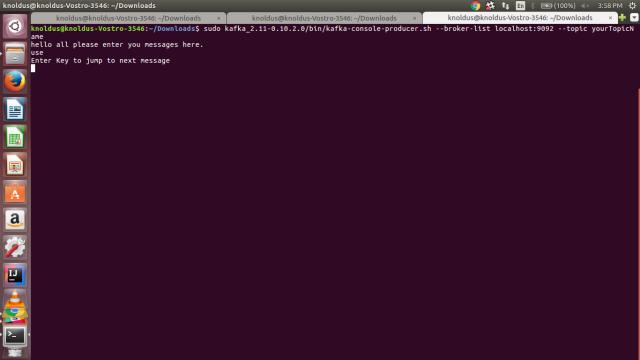
- Create Your Own Topic(Producer)
sudo kafka_2.11-0.10.2.0/bin/kafka-console-producer.sh –broker-list localhost:9092 –topic yourTopicName
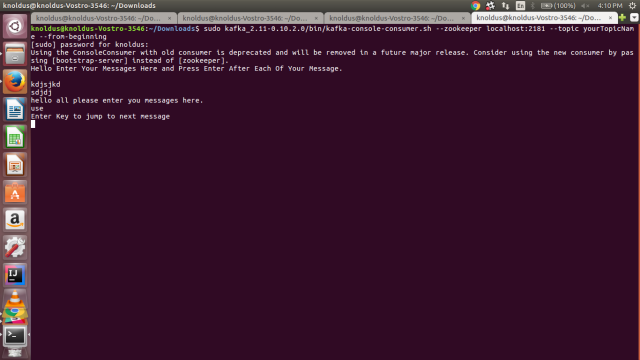
- Create the Consumer
sudo kafka_2.11-0.10.2.0/bin/kafka-console-consumer.sh –zookeeper localhost:2181 –topic yourTopicName –from-beginning
Here is the Snapshot of a basic Kafka cluster running ..
Producer
Consumer
For basic Kafka Commands you can visit our GithHub repository Here