
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article at OpenGenus, we will cover some basic ideas of leaderless replication. I will first introduce the leaderless replication to help you have an overview about what the leaderless replication is. Then, I will explain its key principles, benefits, challenges, and implementation.
-
Table of Contents
- Overview about Leaderless Replication
- Different Replication
- Key Principles
- Benefits
- Challenges
- Implementation
- Conclusion
-
Overview
Leaderless replication is a distributed data replication strategy applied in computer system to improve the availability, fail tolerance, and performance. Before we continue, the word node I used here also refers to server. Unlike the leader replication which has a designated leader node manages and coordinates the replication process, leaderless replication does not have a central leader, and every node will take their reponsibilities to function accordingly.
In leaderless replication, each node is equal and autonomous because all of them are able to read and write replica independently. Also, the read and write replica will be sent to every node in parallel. Once a certain predefined thresholds of node return success value, the client will be informed about this. Hope the rest explanation will help you understand better. Before we dive deep into the leaderless replication. I want to first introduce different types of replication strategies to you.
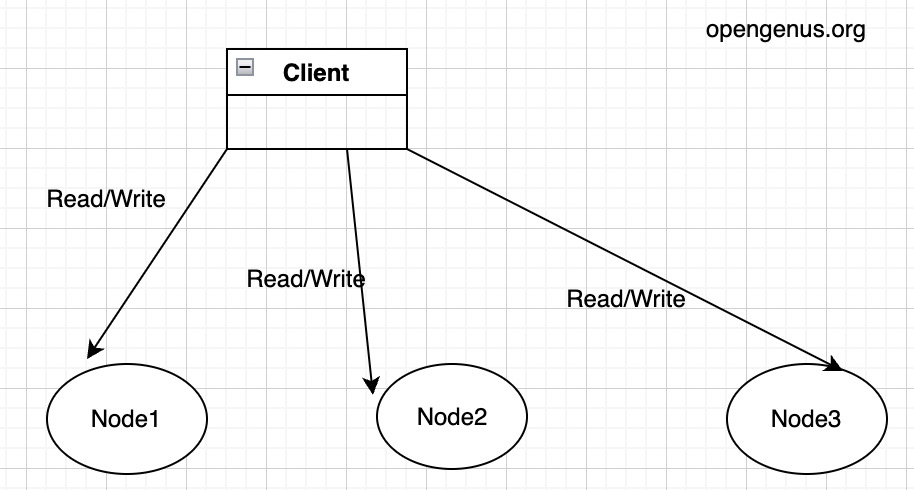
-
Different Replication Strategies
There are different kinds of replication strategies in the distributed systems. The leaderless replication we discover here is just one of them. The one that correspond to the leaderless replication is the leader-based replication. In this strategy, a designated deader node manages and coordinates the replication process. All write operations are directed to the leader, which then propagates the changes to the follower nodes. Read operations can be served by either the leader or the followers.
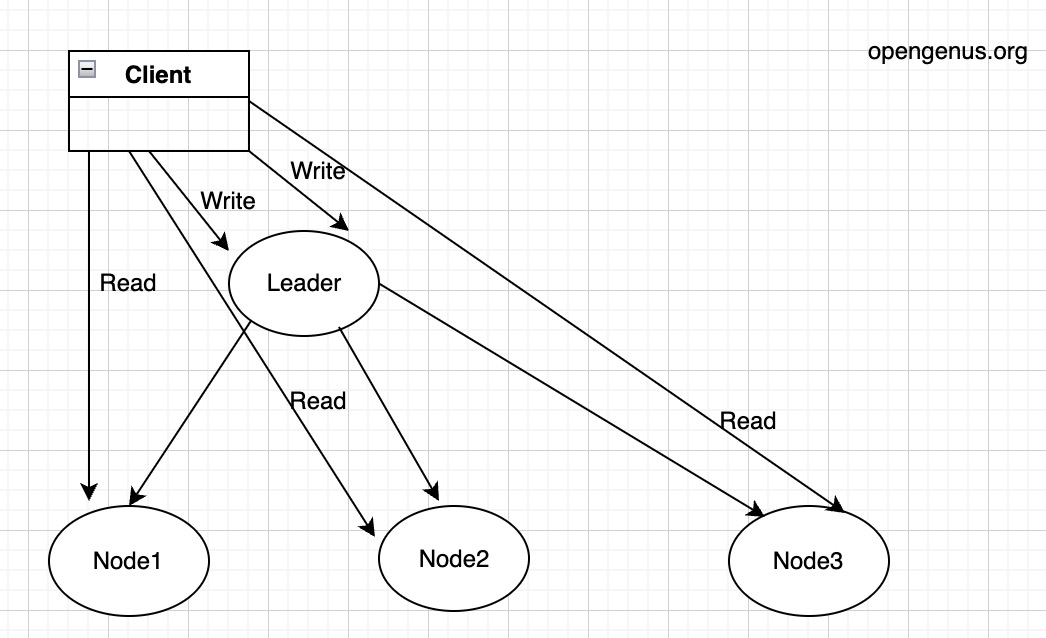
Besides this graph showing the single leader, there are also multi-leader replication in the system design.
-
Key principles
- Peer-to-peer Communication: Node communicate with each other directly.
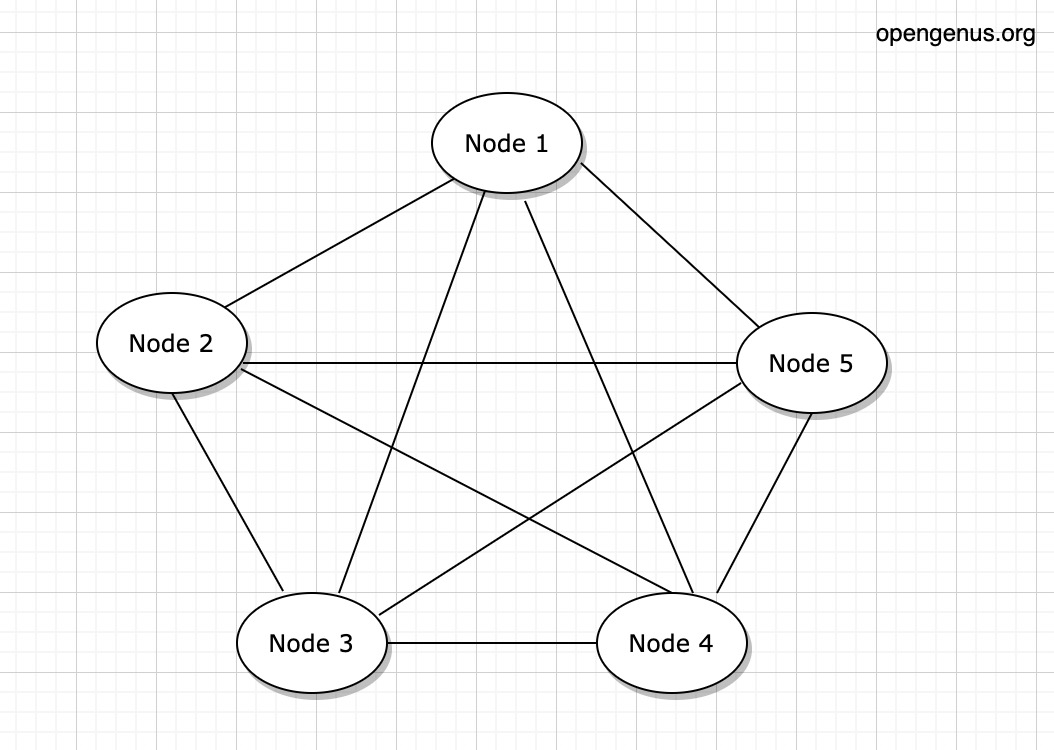
- Data Partitioning: The data is partitioned using a consistent hashing machanism to nodes. This principle makes sure that each node is responsible for taking care of a subset of data. This function allows the parallel processing and load balancing.
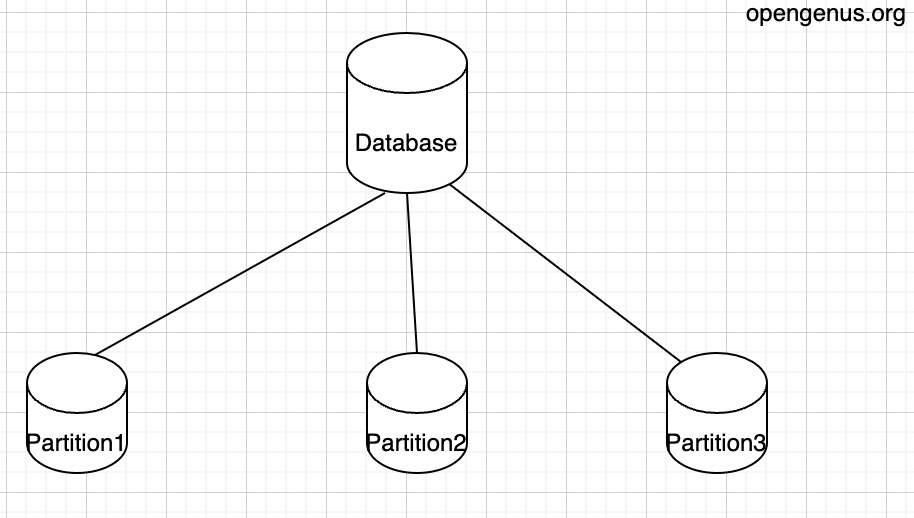
- Consistency Models: Leaderless replication apply different consistency models to determine the how the updates are propagated and merged across the nodes. Here, the consistency is a property of the distributed system. It makes sure that every node at a specific time has the same view of data no matter which node does the update process. There are various types of consistency models, including eventual consistency and strong consistency. In this article, we will briefly explain these two consistency. For the strong consistency, the main idea is that the data will get passed to all the nodes when a write request is sent to one of the servers of the database. However, during this process, the response to any of the later read or write requests of any of the node will be delayed. For the eventual consistency, it ensures that data of each node will get consistent eventually.
- Conflict Resolution: Since there is no leader in the system, conflicts may occur when concurrent updates are made to the same data. There are some mechanisms, including timestamps or vector clocks to solve those conflicts.
-
Benefits
- Increase Availability: In the leaderless replication, if a node fails, other nodes can continue serving read and write requests. This property increases the availability.
- Scalability: Leaderless replication allows linear scalability. New nodes can be added to the system easily, and the data can be dynamically rebalanced across the nodes to distribute the load evenly.
- Performance: Read and write request can be performed on any node. This reduce the latency which occurs when the node communicate with the leader. Also, parallel processing of requests simultaneously.
- Fault Tolerance: Leaderless replication provides fault tolerance because if a node fails, the data it holds can still be accessed from other nodes. This prevent the data loss.
-
Challenges
- Conflict Resolution: as mentioned previously, there may be concurrent updates to the same data. This will lead to some conflicts, and these conflicts require resolution mechanisms to help maintain data consistency. However, resolving these conflicts efficiently without sacrificing performance is difficult.
- Complexity: Leaderless replication brings additional complexity compared to leader replication. These include ensure data consistency, manage concurrent updates, handle the node failures.
- Network Overhead: As mentioned previously, in leaderless replication systems, nodes need to communicate with each other. This may lead to the increase network overhead which may impact the overall system performance.
-
Implementation
Therefore, after we have talked about the key principles, benefits, and challenges for the leaderless replication systems, we can briefly talk about how to implement the leaderless replication.
- Consistent Hashing: We have mentioned that the key principle for the leaderless replication is that the data needs to be partitioned into each node. Therefore, we will need an algorithm to handle this. The algorithm is called consistent hashing. Though we will not go depth to explain this algorithm, you may visit the document here if you are interested in this algorithm and learn more about it. It mainly ensures that each node is reponsible for a diverse range of data. It will enable load balacing and easy addtion or removal of nodes without very complex data redistribution.
- Replication Strategies: Leaderless replication systems employ different replication strategies to make sure of the data durability and availabitliy. These strategies contains full replicaiton, which means that each node will store a copy of all data. There is also one called partial replication. In this case, each node stores a subset of the data.
- Conflict Resolution Mechanisms: In previous contents, we talked about the challenges for the leaderless replication, including conflict resolution. Therefore, when we implement the leaderless replication, there are some mechanisms for them, including vector clocks, timestamps, operational transformation.
- Consistency Model: we have talked about this in the key principles part
- Failure Detection and Recovery: Leaderless replication systems need mechanisms to detect node failures and handle the recovery. In this way, as we mentioned in the availability, if one node crushed, the systems can still function. These mechanisms include heartbeat monitoring, meaning that nodes exchange messages to check their availability.
-
Conclusion
In conclusion, leaderless replication is a distributed data replication strategy that distributes the responsibility of replication across all nodes in a system. By eliminating the need for a central leader, it offers increased availability, fault tolerance, scalability, and performance. However, leaderless replication also introduces challenges, such as conflict resolution and increased network overhead. Proper implementation of consistent hashing, replication strategies, conflict resolution mechanisms, and failure detection is crucial to ensure the success of leaderless replication systems in practice.