
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Abstract
In the fast-paced world of technology, the demand for powerful yet compact solutions has led to innovations in various domains. One such innovation is MobileNetV3, a revolutionary neural network architecture designed to provide efficient deep learning capabilities on resource-constrained mobile devices. In this article, we delve into the essence of MobileNetV3, exploring its history, applications, advantages, disadvantages, and underlying architecture.
Table of Contents
| Topics | |
|---|---|
| 1 | Neural Network Models |
| 2 | History of MobileNetV3 |
| 3 | Why MobileNetV3? |
| 4 | Advantages of MobileNetV3 |
| 5 | Disadvantages of MobileNetV3 |
| 6 | An Overview of the MobileNetV3 Architecture |
| * Input Layer | |
| * Convolutional Layers | |
| * Downsampling and Bottlenecks | |
| * Activation and Pooling | |
| * Output Layer | |
| 7 | What are Convolutional Layers? |
| 8 | Differences between MobileNetV3 and its Predecessors |
| 9 | MobileNetV3 Large and MobileNetV3 Small |
| 10 | Conclusion |
Neural Network Models
Before talking about MobileNetV3, it's important to grasp the concept of a neural network model. Neural networks are computational models inspired by the human brain's interconnected neurons. These networks consist of layers of interconnected nodes, each contributing to the extraction and transformation of features from input data. They have gained immense popularity in machine learning due to their ability to tackle complex tasks such as image recognition, natural language processing, and more.
Examples:
Autoencoders - Data compression, feature learning.
MobileNetV3 - Efficient on-device image processing.
YOLO (You Only Look Once) - Real-time object detection.
InceptionNet (GoogleNet) - Image classification and feature extraction.
History of MobileNetV3
MobileNetV3 was developed by a team of researchers at Google's AI research division, Google Brain. The MobileNetV3 architecture was introduced in a paper titled "Searching for MobileNetV3", authored by Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, and Hartwig Adam. The paper was published in 2019, and it presented significant enhancements to the MobileNet family of models.
Why MobileNet V3?
MobileNet addresses a critical challenge: deploying complex neural networks on devices with limited computational resources. With the proliferation of smartphones, IoT devices, and edge computing, there emerged a need for models that could balance performance and efficiency. MobileNet V3, with its lightweight design, serves as a solution for real-time applications like image recognition, object detection, and more, right at the edge, without the need for extensive cloud computing resources. It introduces innovations such as adaptive width and resolution adjustments, Squeeze-and-Excitation (SE) blocks, and advanced activation functions, resulting in improved performance for various tasks.
Advantages of MobileNetV3:
Efficiency: MobileNetV3 is designed for efficient inference on mobile and embedded devices. Its architecture utilizes advanced techniques, such as network architecture search (NAS), to optimize performance while maintaining efficiency.
Network Architecture Search (NAS) is a technique that automates the process of finding optimal neural network architectures for a given task. Instead of relying on manual design by human experts, NAS employs algorithms to explore a search space of potential neural network architectures and identify the ones that perform best on a specific task. It is widely used in tasks like image classification, object detection, natural language processing, and more to automatically find architectures that outperform manually designed networks.
Low Memory Footprint: Due to its lightweight design, MobileNetV3 models require less memory, making them suitable for devices with limited resources and enabling faster loading times.
Fast Inference: MobileNetV3's efficient architecture allows for faster inference times, which is crucial for real-time applications like object detection and image classification on mobile devices.
Disadvantages of MobileNetV3:
Reduced Accuracy: While MobileNetV3's design optimizes for efficiency, it may sacrifice some accuracy compared to larger and more complex architectures, especially on tasks where fine-grained details are crucial.
Limited Complexity: The lightweight architecture of MobileNetV3 may not be suitable for tasks that require modeling intricate relationships or capturing very high-level features in the data.
Less Effective for Large Inputs: MobileNetV3's efficiency comes from its design choices, which might not perform as well on larger input images or in scenarios where higher-resolution data is essential.
An Overview of the MobileNetV3 Architecture
Input Layer: MobileNetV3 takes an input image of fixed size as input.
Convolutional Layers: The architecture primarily consists of depthwise separable convolutions (a type of convolutional operation used to reduce computational complexity while maintaining accuracy), which are composed of two consecutive layers:
- Depthwise Convolution: In this step, each input channel is convolved separately with a specific kernel. It involves using a small filter for each input channel, which reduces the computation compared to standard convolutions.
- Pointwise Convolution: This is used to create a linear combination of the output channels from the depthwise convolution. This helps in combining information from different channels.
Downsampling and Bottlenecks: The network often includes layers that perform downsampling using strided convolutions to reduce spatial dimensions. Bottleneck layers (1x1 followed by 3x3 depthwise convolution) are also used to reduce the number of input channels before applying depthwise separable convolutions.
Activation and Pooling: Activation functions (they determine whether a neuron in a neural network should activate or not, based on the weighted sum of its inputs) like ReLU (Rectified Linear Unit) are applied after each convolutional layer to introduce non-linearity. Global Average Pooling (GAP) is used at the end to reduce the spatial dimensions to a single value per channel, which is then followed by a fully connected layer.
Output Layer: The final fully connected layer produces the network's predictions. For classification tasks, this layer has as many units as the number of classes in the dataset, and a softmax function is typically applied to convert the raw outputs into class probabilities.
List of Operations:
| Operation | Description |
|---|---|
| 3x3 Depthwise Convolution | Depthwise convolution for spatial filtering |
| 1x1 Convolution | Pointwise convolution for feature generation |
| Linear Bottleneck Block | A building block with expansion, depthwise, and projection layers |
| Squeeze and Excitation (SE) | Lightweight attention mechanism |
| Swish Nonlinearity | Activation function |
| Hard Sigmoid | Activation function |
| Linear Bottleneck with SE | Linear bottleneck block with SE integration |
What are Convolutional Layers?
These layers are designed to capture local patterns and hierarchies of features in the input data through the application of convolutional operations.
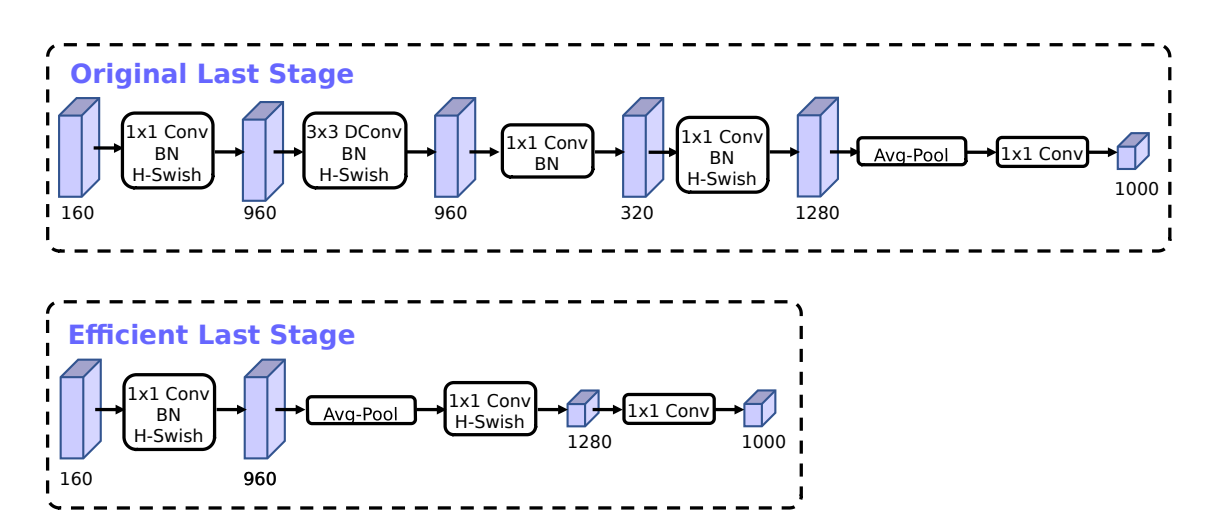
Convolutional Layers in MobileNetV3:
MobileNetV3, like many modern convolutional neural networks (CNNs), utilizes convolutional layers to process and extract features from input data. In the case of MobileNetV3, there are 28 convolutional layers that play a crucial role in capturing local patterns and hierarchies of features.
Here's an overview of convolutional layers and how they work:
Convolutional Operation:
The core operation of a convolutional layer is the convolution operation. It involves sliding a filter over the input data in a systematic way.
The filter is a small matrix that contains learnable weights. It's usually smaller than the input data but has the same number of input channels (depth) as the input.
At each step of the sliding process, the filter is element-wise multiplied with the input values it currently overlaps with. The element-wise products are summed up, producing a single value in the output. In MobileNetV3, each convolutional layer employs a set of filters (also known as kernels).
Multiple Filters and Channels:
A convolutional layer consists of multiple filters. Each filter is responsible for detecting a specific pattern or feature in the input data.
The outputs of these filters are combined to form the output of the convolutional layer, creating a new representation of the input data that highlights relevant features.
The number of filters in a convolutional layer is a hyperparameter and can vary based on the network architecture and task. Common values range from 32 to 512 or more.
MobileNetV3 uses different filter counts in different layers to gradually reduce the spatial dimensions of the input and increase the depth (number of channels) of the feature maps. This depth-wise expansion helps capture a wide range of features.
Stride and Padding:
Stride refers to the step size at which the filter is moved while performing the convolution. A larger stride reduces the spatial dimensions of the output.
Padding involves adding extra border pixels to the input before applying the convolution. Padding helps control the size of the output feature map and can also mitigate the reduction in spatial dimensions caused by the convolution operation. Stride and padding settings are carefully chosen in MobileNetV3 to control the spatial dimensions of the feature maps. For example, a stride of 2 reduces the spatial dimensions by half, which can be used for downsampling. Padding may be used to preserve spatial dimensions when necessary.
Activation Function:
After the convolution operation, an activation function (such as ReLU) is typically applied element-wise to the output of each filter.
The activation function introduces non-linearity to the layer, enabling the network to capture complex relationships in the data. MobileNetV3 often uses the hard-swish activation function, which introduces non-linearity into the network.
Pooling and Downsampling:
MobileNetV3, like other CNN architectures, may include pooling layers (such as max pooling) after some convolutional layers to reduce the spatial dimensions of the feature maps.
Max pooling and average pooling are common pooling techniques. They downsample the feature maps by taking the maximum or average value within each pool. Common pooling sizes are 2x2 or 3x3.
Differences between MobileNetV3 and its Predecessors
MobileNetV3 shows a significant advancement over its predecessors, MobileNet and MobileNetV2, in several key ways. The key improvements that make MobileNetV3 stand out are:
Improved Efficiency
MobileNetV3 takes the efficiency of its predecessors to the next level. Through techniques like neural architecture search (NAS), it optimizes the architecture to provide even better performance with fewer computational resources. This means that MobileNetV3 can run faster and more efficiently on mobile and embedded devices while maintaining the performance of its predecessors.
It turns out MobileNetv3-Large is 27% faster than MobileNetV2 while maintaining similar mAP.
It can perform 225 Million FLOPs.
Enhanced Accuracy
MobileNetV3 achieves higher accuracy in image classification tasks, making it more versatile for a wider range of applications. This improved accuracy makes it a better choice for tasks where details and precision are crucial.
MobileNetV3-Small is 4.6% more accurate compared to MobileNetV2. MobileNetV3-Large is 25% faster at roughly the same accuracy as MobileNetV2 .
Adaptive Width and Resolution
MobileNetV3 introduces the concept of adaptive width and resolution into the MobileNet family. Adaptive width and resolution in machine learning models refer to the ability of a model to dynamically adjust its architecture and input data resolution based on the specific task or input data characteristics. This allows the model to dynamically adjust its architecture based on the available computational resources and input data resolution. It can efficiently adapt to different scenarios, making it highly versatile for various devices and use cases. This adaptive approach can enhance model performance, reduce computational costs, and make the model more robust across various inputs and tasks. Techniques like attention mechanisms and adaptive pooling layers can be employed to achieve this adaptability.
Squeeze-and-Excitation (SE) Blocks
MobileNetV3 incorporates Squeeze-and-Excitation (SE) blocks, which were not present in its predecessors. SE blocks enable the network to better capture channel-wise dependencies in the data. This helps improve the model's ability to extract meaningful features from the input, leading to enhanced performance in image recognition tasks.
Enhanced Activation Functions
MobileNetV3 utilizes advanced activation functions like h-swish and h-sigmoid. These functions provide smoother gradients during training, which can result in faster convergence and improved overall performance.
Reduced Latency
MobileNetV3 reduces inference latency even further compared to its predecessors. This reduction in latency is critical for real-time applications, such as object detection and augmented reality where low latency is essential for a seamless user experience.
MobileNetV3 has reduced latency by 5% as compared to MobileNetV2.
Versatility Across Architectures
MobileNetV3 is designed to be versatile and can be adapted for various model sizes depending on the specific application and device constraints.
MobileNetV3 Large and MobileNetV3 Small
MobileNetV3 comes in two main variants: MobileNetV3 Large and MobileNetV3 Small. These variants differ in terms of model architecture, complexity, and intended use cases. Here are a few differences:
Model Size and Complexity:
MobileNetV3 Large: As the name suggests, MobileNetV3 Large is the larger and more complex. It has a higher number of layers and more parameters compared to MobileNetV3 Small. The increased complexity allows it to capture more intricate features and patterns in the data but comes at the cost of a larger model size.
MobileNetV3 Small: MobileNetV3 Small is a more lightweight and compact version of the model. It has fewer layers and significantly fewer parameters compared to the large variant. The reduced complexity makes it more suitable for resource-constrained devices with limited computational power and memory.
Performance:
MobileNetV3 Large: Due to its increased complexity, MobileNetV3 Large generally achieves higher accuracy on various computer vision tasks, such as image classification and object detection.
MobileNetV3 Small: While MobileNetV3 Small sacrifices some accuracy compared to the large variant, it is optimized for efficiency. It provides a good balance between model size and performance and is ideal for scenarios where computational resources are limited, like on mobile devices, IoT devices, or edge devices.
Use Cases:
MobileNetV3 Large: MobileNetV3 Large is suitable for tasks where accuracy is critical and computational resources are abundant. It can be used in applications like high-accuracy image classification, object detection and semantic segmentation on devices with sufficient processing power and memory.
MobileNetV3 Small: MobileNetV3 Small is optimized for cases where resource efficiency is a priority. It is commonly employed in mobile apps, edge devices and IoT applications where lower power consumption, faster inference, and smaller model size are essential.
Conclusion
With its efficient architecture, MobileNetV3 has successfully bridged the gap between powerful neural networks and resource-constrained devices, enabling real-time applications that were once a distant dream. Its depthwise separable convolutions and linear bottlenecks have become hallmarks of efficiency, illustrating that innovation can arise from simplification. While MobileNetV3's accuracy might occasionally yield to more complex models, its impact in various domains, from image recognition to IoT, cannot be overstated.