
Table of Contents
-
Unveiling Multi-Head Attention
- 1.1 Introduction
- 1.2 Mathematical Foundation
- 1.3 Interpretation
-
- 8.1 Bias Mitigation
- 8.2 Ethical Auditing
- 11.1 Healthcare
- 11.2 Autonomous Vehicles
- 11.3 Finance and Trading
- 11.4 Education and Personalization
- 11.5 Entertainment and Content Creation
- 11.6 Environmental Monitoring
- 11.7 Human-Machine Interaction
- 11.8 Security and Anomaly Detection
- 11.9 Social Impact
1. Unveiling Multi-Head Attention
Introduction
- Multi-Head Attention, a foundational component in modern neural networks, has transformed the way we process and understand sequential and structured data. It's a key building block of the Transformer architecture, which has revolutionized various fields in AI, particularly natural language processing (NLP).
- Multi-Head Attention allows models to weigh the importance of different elements in a sequence, enabling them to focus on relevant information and capture complex relationships within data.
- This section dives into the mathematical foundations and key concepts of Multi-Head Attention.
1.A. Mathematical Foundation
-
Key Components
- Multi-Head Attention relies on three essential components: Query (Q), Key (K), and Value (V), which are linear transformations of the input data.
- These linear transformations are crucial for projecting the input data into a common space where the dot product operation can be performed.
- The dot product between Query and Key is scaled using a softmax function to calculate attention weights.
-
Mathematical Formula
-The heart of Multi-Head Attention lies in the calculation of attention weights. These weights determine how much importance each element in the input sequence should receive when processing a specific element. The attention weight for an element at positionicompared to elementjis calculated as follows:
Here,
- Interpretation
- This formula demonstrates how Multi-Head Attention assigns weights to elements based on their relevance, enabling neural networks to focus on important information. It's the cornerstone of attention mechanisms in deep learning.
Let's break down the steps involved in calculating attention weights:- Calculate the dot product between the query vector and the key vector . This measures the similarity or relevance between the two elements.
- Apply the softmax function to the dot product. This scales the values to produce a probability distribution over all elements in the sequence.
- The resulting attention weights determine how much each element contributes to the final output. Elements with higher weights are considered more relevant.
- This formula demonstrates how Multi-Head Attention assigns weights to elements based on their relevance, enabling neural networks to focus on important information. It's the cornerstone of attention mechanisms in deep learning.
2. Understanding Attention Mechanisms
-
The Essence of Attention
- Attention mechanisms in AI mimic human attention, allowing models to prioritize specific elements within data.
- It's like reading a sentence and naturally focusing on crucial keywords for comprehension.
-
Single-Head vs Multi-Head
- Single-Head Attention, the predecessor to Multi-Head Attention, focuses on one aspect of input data.
- Multi-Head Attention expands this concept, enabling models to attend to different parts of data simultaneously for a deeper understanding.
Let's dive deeper into the advantages of Multi-Head Attention:
- Parallel Processing: Multi-Head Attention allows models to process multiple aspects of the input sequence in parallel, making it more efficient and capable of capturing diverse patterns.
- Enhanced Representations: By learning multiple sets of Query, Key, and Value transformations, models can capture different perspectives and nuances in the data, leading to richer representations.
- Improved Generalization: Multi-Head Attention helps models generalize better across a range of tasks by considering various aspects of the input, making it a versatile choice for various applications.
3. Multi-Head Attention Architecture
-
Key, Query, and Value
- Multi-Head Attention revolves around three key components: Key, Query, and Value.
- Key and Value encode information, while Query determines what to focus on.
-
The Multi-Head Split
- In Multi-Head Attention, these components are split into multiple heads.
- Each head learns a different representation of the data, enabling diverse perspectives to be captured.
Mathematically, this splitting into multiple heads can be represented as follows:
Where each
- Attention Mapping
- Attention mapping, the crux of Multi-Head Attention, determines how much focus each element receives.
- It generates a weighted combination of Values based on attention weights, forming a comprehensive representation of the data.
The attention mapping process can be summarized as follows:
- Calculate attention weights for each head.
- Use these weights to combine the corresponding Values for each head.
- Concatenate the outputs from all heads and apply a linear transformation to produce the final Multi-Head Attention output.
4. Applications in Natural Language Processing
-
Transformer Architecture
- The Transformer architecture, driven by Multi-Head Attention, revolutionized NLP tasks.
- This architecture's ability to handle long-range dependencies and contextual information led to breakthroughs in machine translation, text generation, and more.
-
Models Utilizing Attention Layers
- Multi-Head Attention is a crucial component in various state-of-the-art NLP models. These models employ attention layers to enhance their performance. Some notable models include:
- BERT (Bidirectional Encoder Representations from Transformers): BERT uses Multi-Head Attention to pre-train a deep bidirectional representation of text. It has achieved remarkable results in a wide range of NLP tasks, including question answering and sentiment analysis.
- GPT (Generative Pre-trained Transformer): GPT models utilize Multi-Head Attention in their architecture to generate coherent and context-aware text. They are renowned for their text generation capabilities.
- XLNet: XLNet, an extension of the Transformer architecture, leverages Multi-Head Attention for better modeling of dependencies between words. It has shown strong performance in various NLP benchmarks.
- T5 (Text-to-Text Transfer Transformer): T5 employs Multi-Head Attention to frame a wide array of NLP tasks as text-to-text problems. This unified approach simplifies the development of NLP models.
- Multi-Head Attention is a crucial component in various state-of-the-art NLP models. These models employ attention layers to enhance their performance. Some notable models include:
-
Sample Model Architecture (BERT)
- To illustrate the concept of Multi-Head Attention within an NLP model, let's take a look at a simplified architecture inspired by BERT:
[Input Text] -> [Tokenization] -> [Word Embeddings]
|
[Multi-Head Attention]
|
[Layer Normalization & Residual Connection]
|
[Feed-Forward Neural Networks]
|
[Layer Normalization & Residual Connection]
|
[Position-wise Feed-Forward Networks]
|
[Layer Normalization & Residual Connection]
|
[Masked Multi-Head Attention]
|
[Layer Normalization & Residual Connection]
|
[Feed-Forward Neural Networks]
|
[Layer Normalization & Residual Connection]
|
[Position-wise Feed-Forward Networks]
|
[Layer Normalization & Residual Connection]
|
[Position-wise Feed-Forward Networks]
|
[Layer Normalization & Residual Connection]
|
[Masked Multi-Head Attention]
|
[Layer Normalization & Residual Connection]
|
[Feed-Forward Neural Networks]
|
[Layer Normalization & Residual Connection]
|
[Position-wise Feed-Forward Networks]
|
[Layer Normalization & Residual Connection]
|
[Position-wise Feed-Forward Networks]
|
[Layer Normalization & Residual Connection]
|
[Classifier Output]
In this simplified BERT-like architecture, Multi-Head Attention is applied to capture relationships between words in the input text. Layer normalization and residual connections are used to stabilize training. The model's final output can be used for various downstream NLP tasks.
- Language Translation
In language translation, Multi-Head Attention excels at aligning words in source and target languages.
By focusing on relevant words, it captures intricate linguistic nuances, resulting in accurate translations that preserve meaning.
- Text Summarization
Multi-Head Attention is invaluable in text summarization, as it allows models to comprehend document structures and identify essential information.
This leads to coherent and concise summaries that capture the essence of the original text.
- Sentiment Analysis
Expanding the horizon of NLP applications, Multi-Head Attention is used in sentiment analysis.
It enables models to capture nuanced sentiment expressions by attending to specific words or phrases within a sentence.
- Question Answering
Multi-Head Attention has also found applications in question answering systems. It helps models focus on relevant parts of the passage while answering questions accurately.
Multi-Head Attention's versatility and ability to capture complex dependencies make it a fundamental tool in NLP.
5. Enhancements and Variations
- Self-Attention
-
Self-Attention, a foundational concept in Multi-Head Attention, enables models to understand relationships within a single sequence.
-
This is particularly useful in tasks like sentiment analysis, where the sentiment of a word depends on its context within the same sentence.
-
Self-Attention Formula
-
The self-attention mechanism within a single head is calculated as follows:
The self-attention mechanism within a single head is calculated as follows:
-
-
Here, represents the input sequence, , , and are linear transformations of , and is the dimension of the key vectors.
-
Scaled Dot-Product Attention
- Scaled Dot-Product Attention, a core computation in Multi-Head Attention, improves stability during training by scaling the dot-product of Key and Query.
- This ensures that attention weights don't grow too large, preventing drastic fluctuations.
-
Positional Encodings
-
Positional Encodings address the challenge of handling sequential data by providing information about word positions.
-
This enables models to understand the order of words and phrases, critical for capturing context.
-
Positional Encoding Formula
-
Positional encodings are typically added to the input embeddings and are calculated as follows:
Positional encodings are typically added to the input embeddings and are calculated as follows:
-
-
Here, represents the position of the word, and is the dimension of the positional encoding.
Multi-Head Attention Flowchart: Three linear inputs undergo scaled dot product attention and are then concatenated to produce a single linear output.
Image:
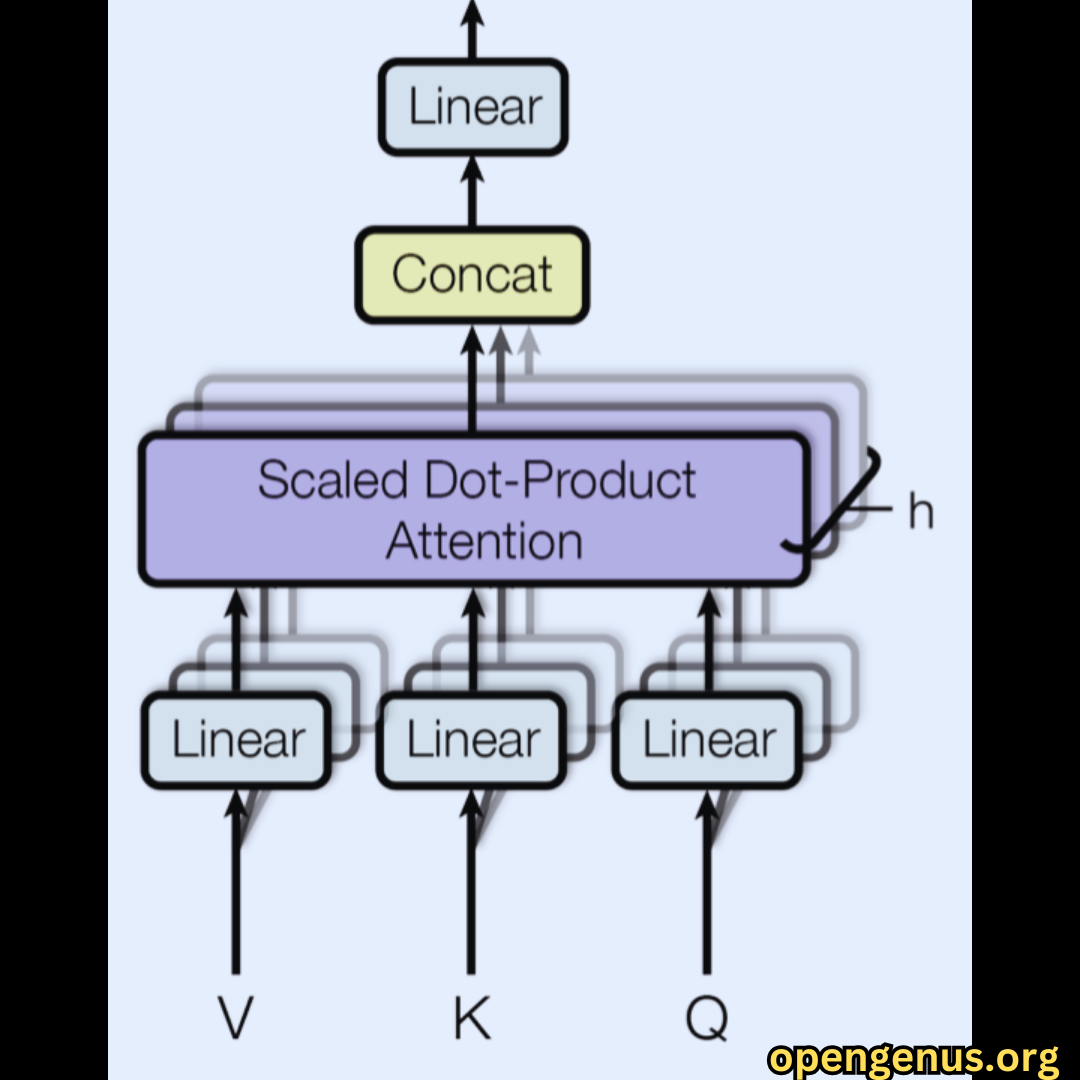
This image and caption provide a visual representation of the Multi-Head Attention process, enhancing the understanding of the topic.
6. Interpreting Multi-Head Attention
-
Attention Heatmaps
- Visualizing Multi-Head Attention reveals its inner workings.
- Attention heatmaps showcase how the model attends to different parts of the input.
- These heatmaps provide insights into the model's decision-making process and highlight which elements contribute most to predictions.
-
Interpreting Attention Patterns
- Analyzing attention heatmaps allows practitioners to gain a deeper understanding of the model's behavior.
- Patterns in the heatmaps can reveal if the model focuses on specific features, tokens, or context.
- This insight can lead to model improvements and better problem-solving strategies.
-
Attention Visualization Tools
- Various tools and libraries are available to create and visualize attention heatmaps.
- These tools simplify the process of exploring and interpreting Multi-Head Attention within neural networks.
- Researchers and practitioners can use these tools to debug models, identify biases, and optimize performance.
7. Challenges and Considerations
-
Computational Complexity
- The computational cost of Multi-Head Attention can be high, especially in models with numerous heads or extensive input sequences.
- Techniques like pruning, knowledge distillation, and hardware acceleration help mitigate this challenge.
-
Model Compression
- To address computational complexity, researchers are exploring model compression techniques.
- Methods like quantization and weight sharing reduce the model's size and computational requirements while preserving performance.
- These advancements make Multi-Head Attention more accessible for a broader range of applications.
-
Overfitting and Generalization
- While Multi-Head Attention enhances model understanding, an excessive number of heads can lead to overfitting.
- Regularization techniques and hyperparameter tuning are essential to strike the right balance.
-
Adaptive Head Selection
- To combat overfitting, models with adaptive head selection mechanisms have been proposed.
- These models dynamically choose relevant heads for a given task, reducing the risk of overfitting and improving generalization.
8. Ethical Implications
-
Bias Mitigation
- Multi-Head Attention, while powerful, can inadvertently amplify biases present in data.
- Ensuring diverse and representative training data, coupled with bias detection mechanisms, is crucial to mitigate this issue and promote fairness.
-
Ethical Auditing
- Ethical considerations in AI, especially in NLP applications, are gaining prominence.
- Ethical auditing processes evaluate models for biases, stereotypes, and fairness concerns.
- Ethical guidelines and standards are being developed to ensure responsible and unbiased AI deployment.
9. The Future of Multi-Head Attention
-
Innovations Ahead
- The future of Multi-Head Attention is promising.
- Ongoing research explores innovative architectures, attention mechanisms, and applications beyond NLP.
- Advancements in ethical AI, interpretability, and robustness are expected to shape the trajectory of this field.
-
Cross-Modal Applications
- Multi-Head Attention's adaptability extends to cross-modal applications, such as vision and language understanding.
- Models that can effectively fuse information from multiple modalities hold the potential for breakthroughs in various domains.
10. Conclusion: Your Journey of Discovery
- Embracing Creativity
- Multi-Head Attention stands as a testament to the ever-evolving landscape of AI.
- As you embark on your journey of mastering this mechanism, delve into its intricacies, explore its applications, and consider its ethical dimensions.
- The world of Multi-Head Attention invites you to push boundaries, spark innovation, and contribute to a field that is reshaping how AI understands and processes information.
- Your path of discovery awaits, where creativity meets technology, and the future is yet to be written.
11. Emerging Applications
-
Healthcare
- Multi-Head Attention is finding applications in medical image analysis, patient records processing, and drug discovery.
- Its ability to handle complex data relationships is invaluable in improving healthcare outcomes.
-
Autonomous Vehicles
- In the realm of autonomous vehicles, Multi-Head Attention aids in processing sensor data, understanding the environment, and making critical decisions in real-time.
- Safety and reliability are paramount in this domain.
-
Finance and Trading
- Multi-Head Attention is being employed in financial forecasting, risk assessment, and algorithmic trading.
- Its capacity to discern subtle market trends is reshaping financial strategies.
-
Education and Personalization
- Personalized learning platforms leverage Multi-Head Attention to tailor educational content to individual students.
- Adapting to students' strengths and weaknesses leads to more effective learning experiences.
-
Entertainment and Content Creation
- Multi-Head Attention plays a role in content recommendation, video editing, and creative writing.
- It enhances user engagement and content quality in the entertainment industry.
-
Environmental Monitoring
- Environmental scientists use Multi-Head Attention to analyze data from remote sensors and satellites.
- Monitoring climate change and natural disasters is vital for global sustainability.
-
Human-Machine Interaction
- Multi-Head Attention contributes to natural language understanding and human-robot interaction.
- It facilitates more intuitive and responsive AI interfaces.
-
Security and Anomaly Detection
- In cybersecurity, Multi-Head Attention assists in identifying unusual patterns and threats within networks.
- It strengthens digital security and data protection.
-
Social Impact
- Multi-Head Attention is harnessed for social good, such as disaster relief coordination and poverty analysis.
- It aids in addressing pressing global challenges.
These additional sections explore emerging applications of Multi-Head Attention, showcasing its versatility and potential impact across diverse domains.