
Abstract
Deep learning has revolutionized the field of artificial intelligence by enabling machines to learn and make decisions on their own, similar to the human brain. The training process of deep learning models is a crucial aspect of this technology, as it determines the model's ability to generalize and perform well on unseen data. In this article at OpenGenus, we will delve into the training process, explore key terms such as epoch and Adam optimizer, and briefly discuss how the process varies across different model types.
Table of Content
| No. | Table of Contents |
|---|---|
| 1 | Deep Learning |
| 2 | How are Deep Learning Models trained? |
| 2.1 | Data Collection |
| 2.2 | Data Preprocessing |
| 2.3 | Model Architecture |
| 2.4 | Initialization |
| 2.5 | Forward Pass |
| 2.6 | Loss Calculation |
| 2.7 | Backpropagation |
| 2.8 | Optimization Techniques |
| 3 | Variation in training among different models |
| 4 | Factors Affecting Model Training |
| 5 | Compute Intensive Training Process |
| 6 | A few more concepts in Deep Learning Training |
| 6.1 | Early Stopping |
| 6.2 | Calibration |
| 6.3 | Knowledge Distillation |
| 7 | Conclusion |
Deep Learning
Deep learning is a type of artificial intelligence where machines learn to understand and solve complex problems on their own, without explicit programming. It mimics how the human brain works, using layers of interconnected artificial neurons to process and learn from vast amounts of data. Deep learning has enabled significant advancements in areas like image recognition, natural language processing etc. Training of deep learning models is essential in shaping their capacity to generalize and excel in handling new and unseen data.
How are Deep Learning Models trained?
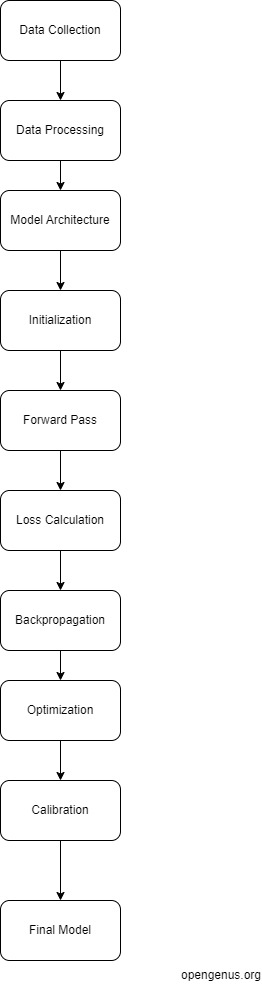
The training process in deep learning involves feeding the model with a large dataset, allowing it to learn patterns and adjusting its parameters to reduce errors. It can be summarized in the following steps:
Data Collection: A huge and diverse dataset is gathered to train the model. High-quality data is essential for the model to learn representative features and generalize well.
Example:
Suppose we are building an image classifier to identify whether an image contains a cat or a dog. We gather a large and diverse dataset of labeled images of cats and dogs. This is the data collection process.
Data Preprocessing: The collected data is preprocessed to ensure uniformity, remove noise, and make it suitable for input to the model. This step includes normalization, scaling, and data augmentation.
Example:
Continuing with our above example, we preprocess the images by resizing them to a consistent size, normalizing the pixel values to a certain range and applying data augmentation techniques to increase the diversity of the training samples.
Model Architecture: Choosing an appropriate model architecture is crucial. Different model types, such as convolutional neural networks (CNNs), recurrent neural networks (RNNs) and others, have distinct structures to do specific tasks.
Example:
We choose a simple neural network architecture consisting of an input layer, a hidden layer with ReLU activation, and an output layer with a sigmoid activation function.
Initialization: When we create a machine learning model, it consists of many internal components called parameters, which can be adjusted to make better predictions. For example, in a neural network, the parameters are the weights and biases of the neurons. To start the training process, we randomly set these parameters to small values. If we set them to zero or the same value, the model won't be able to learn effectively because all the neurons will behave the same way. Proper initialization is vital to prevent the model from getting stuck in local minima during training.
Example:
We initialize the weights and biases of the neurons in the hidden and output layers with small random values. This random initialization helps the model learn diverse features from the data.
Forward Pass: The training process begins by giving the model some input data, which could be images, text, or any other type of data the model is designed to handle. The input data is fed into the model, where it goes through a series of mathematical operations and transformations in different layers of the model. Each layer learns to recognize different patterns or features in the data. As the data flows through the layers, the model becomes more capable of understanding the patterns and relationships in the data.
Example:
We take an input image and feed it through the network. The image's pixel values are passed through the layers, and the hidden layer applies the ReLU activation function to the weighted sum of inputs. The output layer applies the sigmoid activation to produce a prediction between 0 and 1, indicating the probability of the image being a dog.
Loss Calculation: After the data has passed through the model and predictions have been made, we need to evaluate how well the model did. To do this, we compare its predictions to the actual correct answers from the training data. The difference between the predictions and the correct answers is calculated using a loss function. There are various types of loss functions, depending on the problem we are trying to solve. For example, in a regression problem (predicting a continuous value), we might use mean squared error, while in a classification problem (predicting categories), we could use cross-entropy loss. The loss function gives us a single number that represents how far off the model's predictions are from the true values. The bigger the difference, the larger the loss value. The goal of training is to minimize this loss by adjusting the model's parameters.
Example:
We compare the model's prediction to the actual label (cat or dog) of the input image. Let's say the actual label is 1 (dog). We use a loss function such as binary cross-entropy to calculate the difference between the predicted probability and the actual label.
Backpropagation: Backpropagation is an important technique used to update the model's parameters based on the computed loss. It propagates the error backward through the layers to calculate gradients, indicating the direction and magnitude of parameter updates. The number of epochs (one complete pass through the entire training dataset during the model's learning process) determines how many times the entire dataset is used during the backpropagation process, helping the model finetune its parameters and improve its performance.
Example:
Backpropagation propagates the gradients backward through the layers, while updating the parameters in the opposite direction of the gradient to minimize the loss. This process involves adjusting the weights and biases in the hidden and output layers to make the model's prediction more accurate.
Optimization techniques play a crucial role in training deep learning models by helping them find the best parameters to minimize errors and improve performance. After calculating the loss and gradients during the forward pass, the optimization algorithm is used to update the model's parameters based on these gradients. The goal is to minimize the loss function.
The Adam optimizer, short for Adaptive Moment Estimation, is one of the most popular optimization algorithms. It combines the strengths of AdaGrad and RMSprop, to achieve faster convergence and better results. Adam optimizes the learning rate for each parameter based on their historical gradients, enabling the model to find an optimal solution efficiently.
Other optimization techniques include Stochastic Gradient Descent (SGD) and its variants like Mini Batch Gradient Descent and Batch Gradient Descent, which update parameters based on the gradients computed on small batches of data. Momentum optimization accelerates training by considering the direction of previous parameter updates, allowing the model to bypass local minima and speed up convergence.
Variation in training among different models
The training process can vary significantly among different deep learning models based on their architecture and the nature of the data they process. Here are a few examples:
Convolutional Neural Networks (CNNs): CNNs are widely used for image-related tasks. Their training involves learning spatial hierarchies of features through convolutional layers and pooling. Data augmentation is commonly used to increase the diversity of training samples and improve generalization.
Recurrent Neural Networks (RNNs): RNNs are designed for sequential data like text or time series data. Training RNNs involves handling vanishing gradients, which can be addressed using specialized units like LSTM (Long short-term memory) or GRU (Gated Recurrent Unit).
Generative Adversarial Networks (GANs): GANs are used to generate synthetic data. Their training process involves two competing networks, the generator and discriminator, which require careful tuning to achieve stability and convergence.
Transformer Models: Transformers are popular for natural language processing tasks. They rely on self-attention mechanisms and parallel processing, which makes their training process computationally intensive.
Reinforcement Learning Models: In reinforcement learning, the model learns by interacting with an environment and receiving feedback. The training process involves finding optimal policies through trial and error, which requires balancing exploration and exploitation.
The variations in training among these models highlight the importance of selecting the appropriate architecture and fine-tuning the training process to get optimal performance.
Factors Affecting Training of Models
Training deep learning models can be affected by various factors, which can impact the model's performance and convergence. Some of the key factors include:
Dataset Size: The size of the training dataset can significantly influence the model's ability to learn representative features.
Data Quality: High-quality data is essential for training deep learning models. Noisy or incorrect data can adversely affect the model's performance.
Data Preprocessing: Proper data preprocessing, including normalization, scaling, and data augmentation, can impact how well the model learns from the data.
Model Architecture: Choosing an appropriate model architecture is crucial. Different architectures are suitable for different types of tasks and data.
Initialization: Random initialization of model parameters can impact how quickly the model converges during training.
Learning Rate: The learning rate determines the step size for parameter updates during training. An appropriate learning rate is essential for stable and effective training.
Optimizers: Different optimization algorithms, such as Adam, SGD, or RMSprop, can affect the speed and efficiency of model training.
Batch Size: The number of samples processed in each training iteration (batch) can impact the training process and convergence.
Compute Intensive Training Process
Training deep learning models can be extremely compute-intensive, especially for large-scale models and datasets. The computational demands arise from the huge number of operations involved in forward and backward passes during training. These operations include matrix multiplications, convolutions, gradient computations etc.
The time required to train a deep learning model depends on several factors, including the model's architecture, dataset size, hardware specifications (CPU/GPU), and hyperparameters like batch size and learning rate. Larger models with more parameters and complex architectures usually require more computational power and time for training. To estimate training times for specific CPUs/GPUs, we need to consider the hardware specifications and theoretical compute capabilities.
Here's how to estimate training time for a deep learning model on a specific CPU or GPU:
- Determine the number of FLOPS for the CPU/GPU.
- Calculate the FLOPS required for one forward and backward pass through the model.
- Estimate the number of iterations (epochs) required for convergence.
- Multiply the FLOPS required per iteration by the number of iterations to get the total FLOPS.
- Divide the total FLOPS by the CPU/GPU's FLOPS to get the estimated training time.
- Training times can be affected by various factors, such as data loading and preprocessing, communication overhead and implementation efficiency.
Here's an example:
Let us do a sample calculation for estimating the training time for a deep learning model on two specific CPUs/GPUs: A and B.
Assumptions:
- CPU/GPU A has 10 TFLOPS (10 trillion floating-point operations per second) compute capability.
- CPU/GPU B has 20 TFLOPS compute capability.
- The model requires 1 TFLOPS for one forward and backward pass.
- The model's training converges after 100 epochs.
Sample Calculation:
Let us determine FLOPS per iteration for the model:
Model's FLOPS per iteration = 1 TFLOPS
Estimating the total FLOPS for the entire training process
Total FLOPS = FLOPS per iteration * Number of iterations
Total FLOPS = 1 TFLOPS * 100 epochs = 100 TFLOPS
Estimate the training time for CPU/GPU A:
Training time for A (in seconds) = Total FLOPS / CPU/GPU A's FLOPS
Training time for A = 100 TFLOPS / 10 TFLOPS = 10 seconds
Estimate the training time for CPU/GPU B:
Training time for B (in seconds) = Total FLOPS / CPU/GPU B's FLOPS
Training time for B = 100 TFLOPS / 20 TFLOPS = 5 seconds
So, based on these calculations, the estimated training time for the model on CPU/GPU A would be approximately 10 seconds, while on CPU/GPU B, it would be about 5 seconds.
A few more concepts in Deep Learning Training
Early Stopping
Early stopping is a technique used to prevent overfitting during the training of deep learning models. Overfitting occurs when a model becomes too specialized to the training data and performs poorly on new and unseen data. Early stopping helps to find the right balance between model complexity and generalization. During the training process, the model's performance is monitored on a separate validation dataset. The training is stopped when the model's performance on the validation data starts to degrade or no longer improves. The model is saved at the point where it achieved the best performance on the validation set. By this, we ensure that the model generalizes well to new data and avoids memorizing noise in the training dataset.
Calibration
Calibration is a post-processing technique used to improve the reliability of probability estimates produced by deep learning models. It ensures that the predicted probabilities are well-calibrated and reflect the actual probabilities as closely as possible. Firstly the model is trained as usual to make predictions on a given task. After training, the model's predicted probabilities are compared to the actual probabilities observed in the validation or test data. A calibration function is then applied to adjust the predicted probabilities based on the observed discrepancies between the model's predictions and the true probabilities.
Knowledge Distillation
Knowledge distillation is a technique used for model compression and transfer learning. It involves transferring the knowledge from a large, complex model (often referred to as the 'teacher' model) to a smaller, more efficient model (the 'student' model). The teacher model is trained on the target task using the standard training process. The student model is initialized and trained to mimic the behavior of the teacher model. Instead of using the true labels during training, the student model is trained with the soft targets produced by the teacher model. Soft targets are the teacher model's predicted probabilities for each class instead of the hard labels (0 or 1). This enables the student model to learn from the rich knowledge and insights of the teacher model. It allows the student model to achieve comparable performance to the teacher model while being more computationally efficient and having a smaller memory footprint.
Conclusion
The training process of deep learning models is crucial in enabling machines to learn and make decisions like the human brain. Through proper data collection and preprocessing, we ensure the model's ability to generalize and perform well on new data. Optimization techniques like Adam optimizer play an important role in fine-tuning the model's parameters for better accuracy and faster convergence. The future of deep learning holds great promise. With ongoing research and advancements, we can expect even more significant breakthroughs in various fields such as image recognition, natural language processing, and medical diagnosis. As computing power and data availability continue to grow, deep learning models will become more powerful and pave the way for new applications and help solve complex problems in ways we couldn't have imagined before.