
In this article at OpenGenus, we will learn about Compilation, Interpretation and Execution process in Java and the differences between the 3 stages and compare it with the process for other mainstream programming languages like C and C++.
Table of Contents
- Introduction
- Compilation and Execution Processes
- Flowchart of the Compilation Process
- Interpretation Phase in Java Compilation Process
- Java Compilation Commands
- Comparison with C/C++
- Conclusion
Introduction
In the world of software development, Java stands as a titan—a versatile and powerful language that has driven countless applications, from web services to mobile apps. But what makes Java truly remarkable is not just its capabilities; it's the intricate process that transforms human-readable Java code into machine-executable instructions. This process is known as Java compilation, and it's the secret sauce behind Java's versatility and cross-platform compatibility.
The Java programming language is renowned for its "write once, run anywhere" capability, achieved through its unique compilation process. Understanding the compilation process is essential for Java developers as it forms the foundation of the language's portability and execution. This article provides a comprehensive overview of the compilation process in Java, delving into its various steps and offering insights into the underlying mechanics.
Throughout this journey, we'll unravel the complexities of Java compilation. We'll dissect the steps involved, from crafting the Java source code, akin to creating a culinary recipe, to the final transformation into bytecode, which can be executed anywhere there's a Java Virtual Machine (JVM).
Compilation and Execution Process
The compilation process in Java can be broken down into several distinct steps, each serving a specific purpose in transforming human-readable code into machine-executable bytecode. Here are the key stages involved:
The Java Source Code
The foundation of any culinary masterpiece is the recipe—a carefully written set of instructions that guide the chef's hand. In the world of programming, Java source code serves this exact purpose. It is the inception point for every Java program, where human-readable commands are transformed into machine-executable actions.
Consider the following Java source code snippet:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
This seemingly simple code is a Java program that accomplishes the task of printing "Hello, World!" on your screen. Just as a chef meticulously pens down the ingredients and steps to create a dish, Java source code encapsulates the instructions for a computer to perform a specific task.
It's the starting point of our culinary journey through Java's compilation process, where we'll witness the gradual transformation of these human-readable instructions into something a computer can digest and execute.
Lexical Analysis (Tokenization)
Now that we possess our culinary recipe—the Java source code—it's time to examine it closely. This is where lexical analysis, often referred to as tokenization, enters the scene. Think of it as the process of disassembling a sentence into individual words.
In our Java program, every component, whether it's a keyword like public or class, an identifier such as HelloWorld, an operator represented by =, or a literal exemplified by "Hello, World!", serves as a token.
The output of lexical analysis is a sequence of tokens, which represent the fundamental building blocks of the code. For example:
- Keyword:
public,class,public,static,void,String - Identifier:
HelloWorld,main,args,System,out,println - String Literal:
"Hello, World!"
Much like a skilled linguist identifies words within a sentence, the lexer, the aptly named initial phase of compilation, meticulously scrutinizes each character of the code. Its mission is to discern these tokens and establish the initial bridge between your human-readable code and the machine's capacity to interpret it.
As we journey deeper into the compilation process, we'll witness how these tokens are organized, validated, and eventually transmuted into a form that computers can readily understand and execute.
Syntax Analysis (Parsing)
With our Java source code broken down into tokens, it's time to piece them together in a meaningful way. This is where syntax analysis, also known as parsing, comes into play. Think of it as assembling those words into well-structured sentences.
In the world of Java compilation, parsing involves constructing a parse tree that adheres to the grammatical rules of the Java language. This parse tree is akin to a blueprint that captures the hierarchical relationships and structures within the code. Parsing ensures that the code follows the language's grammar, just as an editor ensures that a sentence is grammatically correct.
The output is a parse tree or abstract syntax tree (AST) that represents the hierarchical structure of the code. It verifies that the code adheres to the grammar rules of the Java language.
Throughout this phase, the compiler meticulously validates the code's syntactical accuracy, making sure it aligns with the rules of the Java language. Think of this step as proofreading your sentences to ensure they make sense and follow the language's rules.
Semantic Analysis
As we delve deeper into the compilation process, it's time to explore the meaning behind the code. This is the realm of semantic analysis, where we uncover the relationships and implications hidden within various constructs.
Imagine you're editing a document, not just for grammar but also for context and coherence. Similarly, during semantic analysis, the compiler identifies and rectifies any semantic errors that might compromise the logic of the code. It ensures that operations are correctly defined and compatible, maintaining the integrity of the code's functionality.
The output is an analysis of the code's meaning and relationships between different elements. It checks for semantic errors, such as type mismatches or undeclared variables.
For example, if you're writing code to calculate the volume of a cube, semantic analysis ensures you're using the correct formula and not, say, the formula for the area of a circle. It's all about making sure the code makes sense and accomplishes its intended purpose.
Intermediate Code Generation
As our compilation journey progresses, we reach a critical juncture: intermediate code generation. Think of this phase as the bridge between the high-level source code and the final bytecode, which can be executed on a Java Virtual Machine (JVM).
Intermediate code is closer to machine code, but it's abstracted from the intricacies of the target platform. Imagine you're translating a complex document into simpler, universally understandable language to facilitate global communication. That's precisely what intermediate code does.
The output is an intermediate representation of the code that is closer to machine code but remains abstracted from the target platform. This intermediate code captures the essence of the original code's logic.
This intermediary representation allows for optimizations and code transformations that can improve the efficiency and performance of the resulting bytecode. Techniques like dead code elimination, constant folding, and loop unrolling are employed to fine-tune the code's behavior. Think of it as polishing your writing to make it more concise and efficient.
Optimization
Our journey through the Java compilation process has reached an exciting phase: optimization. Picture this as enhancing the flavor and presentation of a gourmet dish. In this case, our dish is the Java code, and optimization aims to make it more efficient.
During optimization, the intermediate code undergoes a series of transformations aimed at enhancing execution speed and conserving memory. It's all about achieving the perfect balance between minimizing execution time and resource usage.
The output is an optimized version of the intermediate code. Optimization techniques are applied to enhance performance by minimizing execution time and conserving memory.
Just as a chef might trim excess fat from a steak to make it leaner, the compiler identifies and eliminates redundant code (dead code elimination). It also simplifies expressions by folding constants (constant folding) and unrolls loops to reduce iteration overhead (loop unrolling).
Code Generation
The culmination of our journey through the Java compilation process is code generation—the moment when Java source code transforms into bytecode that can be executed on a Java Virtual Machine (JVM).
Think of it as taking your perfected recipe and preparing the final dish. The compiler maps the optimized intermediate code to bytecode instructions, encapsulating the essence of the original source code. However, it does so in a way that accommodates the idiosyncrasies of the JVM, which serves as the culinary stage where our dish will be presented.
The final output is bytecode, which is a low-level representation of the code that can be executed on any platform with a compatible Java Virtual Machine (JVM). The bytecode is stored in class files, ready for execution.
Just as a chef presents a dish on a plate suited to the occasion, the compiler generates bytecode tailored to the JVM. This bytecode is platform-independent, meaning it can be executed on any device or operating system equipped with a compatible JVM.
Our Java compilation journey culminates here, with bytecode ready to be served to the Java Virtual Machine, where it will be transformed into actions and results.
Execution
Once the optimization phase is complete, the compilation process culminates with the generation of bytecode. Bytecode is a low-level representation of the code that can be executed on any platform equipped with a compatible Java Virtual Machine (JVM). This step maps the optimized intermediate code to bytecode instructions, encapsulating the essence of the original source code while accommodating the idiosyncrasies of the JVM.
The execution phase takes place when you run your Java program. At this point, the Java bytecode is interpreted and executed by the Java Virtual Machine (JVM). This enables your Java code to run on various systems, including Windows, macOS, Linux, and more, without modification. The JVM ensures that your program performs consistently and reliably across different platforms.
One of the key strengths of Java is its cross-platform compatibility. The bytecode produced during compilation is platform-independent, allowing Java applications to run seamlessly on different operating systems. This feature makes Java a popular choice for developing applications that need to work across diverse environments.
These stages collectively transform human-readable Java source code into platform-independent bytecode, enabling Java applications to run seamlessly across different environments.
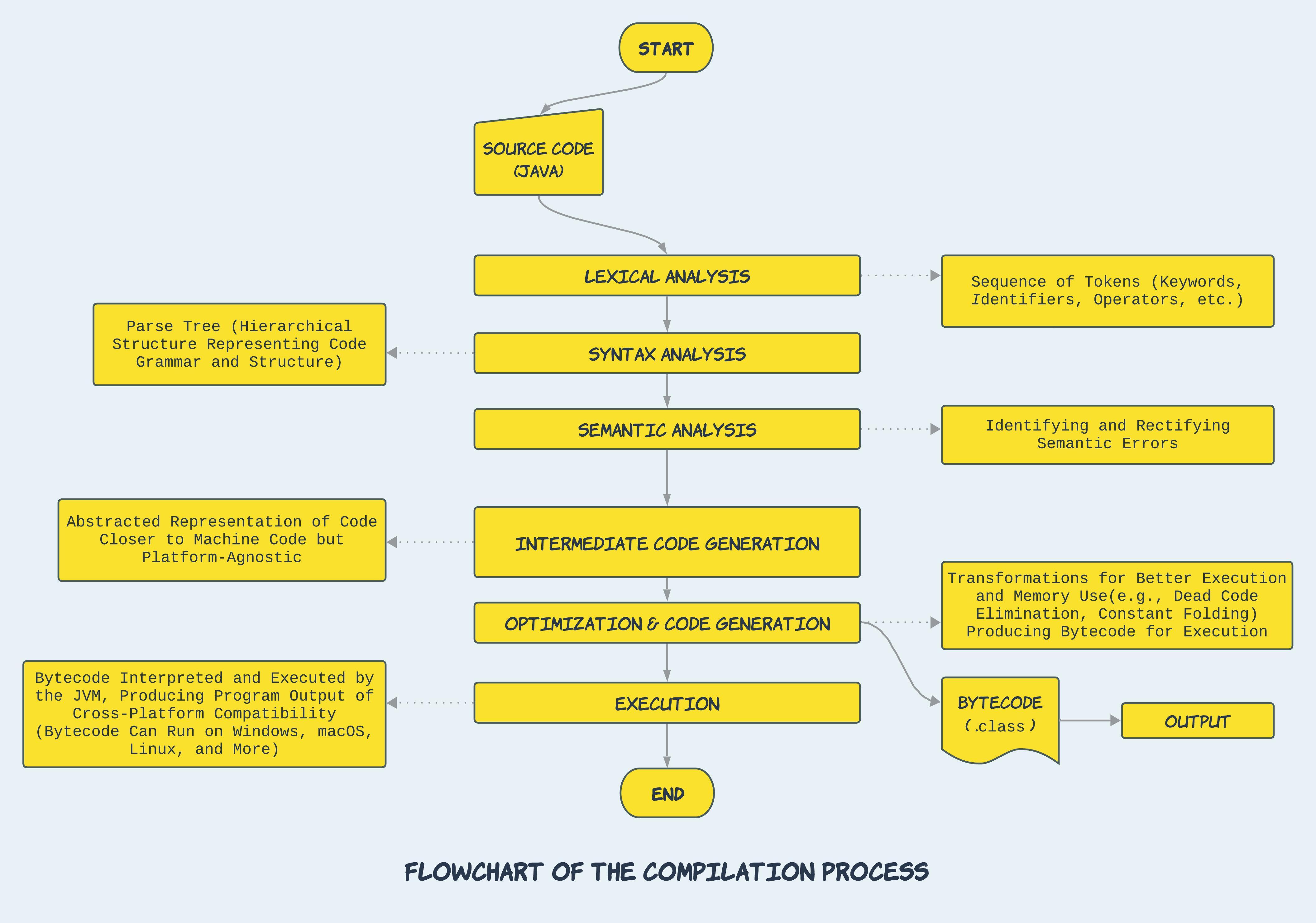
Flowchart of the Compilation Process
To provide a clear visual representation of the intricate dance between the various phases of Java compilation, we present a flowchart.
This flowchart encapsulates the harmonious progression from lexical analysis, through parsing, semantic analysis, intermediate code generation, optimization, and finally, code generation. Each step in the process seamlessly builds upon its predecessor, orchestrating the transformation from human-readable code to platform-independent bytecode.
Interpretation Phase in Java Compilation Process
The interpretation phase in Java is closely tied to the execution of Java programs through the Java Virtual Machine (JVM). Here's a detailed breakdown of this phase:
-
JVM Loading:
- The JVM loads the compiled bytecode files (.class) into memory when a Java program is executed.
-
Bytecode Verification:
- Before interpretation begins, the JVM performs bytecode verification. This step ensures that the bytecode adheres to Java's safety and security requirements, preventing potentially harmful code from executing.
-
Interpreter:
- Once verified, the JVM acts as an interpreter, reading and executing the bytecode instructions line by line.
- It translates these bytecode instructions into native machine code for the specific host system on-the-fly.
-
Just-In-Time (JIT) Compilation:
- To improve execution speed, the JVM employs a Just-In-Time (JIT) compiler.
- The JIT compiler identifies frequently executed bytecode and translates it into native machine code.
- This native code is stored in memory, reducing interpretation overhead for subsequent executions.
-
Dynamic Adaptation:
- The interpretation process is highly dynamic, adapting to the host system's architecture and capabilities.
- This dynamic adaptation ensures that Java programs can run on various platforms without modification.
Comparison: Compilation Phase vs. Interpretation Phase in Java
| Aspect | Compilation Phase | Interpretation Phase |
|---|---|---|
| Primary Purpose | Translating source code into bytecode. | Executing bytecode on the JVM. |
| Process | Occurs before execution. | Happens at runtime during execution. |
| Output | Bytecode files (.class). | Native machine code (when JIT is used). |
| Speed | Generally faster execution since code is pre-translated. | Dynamic execution speed, with potential JIT optimizations. |
| Platform Independence | Platform-independent bytecode. | Platform-independent due to dynamic adaptation. |
| Safety Checks | Static checks (syntax, type) by the compiler. | Bytecode verification by the JVM. |
| Execution Control | Compiler doesn't control execution. | JVM controls execution line by line. |
Java Compilation Process
-
javac fileName.java:- This command is used to compile a Java source code file named "fileName.java."
- javac stands for "Java Compiler," and it's the Java compiler provided by Oracle's Java Development Kit (JDK).
- When you run this command, the Java compiler reads the source code in "fileName.java," performs lexical analysis, syntax analysis, and semantic analysis to check for errors and validate the code.
- If there are no errors, the compiler generates bytecode instructions for the Java Virtual Machine (JVM) to execute.
- If there are errors, the compiler provides error messages to help you identify and fix them.
-
java fileName:- After successfully compiling a Java source file with javac, you can run the compiled bytecode with the java command.
- In this case, "fileName" should be replaced with the name of the class containing the public static void main(String[] args) method. This is the entry point of your Java program.
- The java command loads the bytecode from the ".class" file (generated by javac) and executes it on the Java Virtual Machine (JVM).

Content of .class File:
Inside the ".class" file, you'll find the compiled bytecode instructions that the JVM understands.The contents of a .class file are in binary format and are not meant to be human-readable directly. However, you can use various tools to inspect the bytecode in a human-readable format. Here's how you can view the contents of a .class file:
javap command
The javap command is a built-in tool that comes with the Java Development Kit (JDK). It allows you to disassemble and view the bytecode of a compiled Java class. Open your command prompt or terminal and use the following syntax :javap -c YourClassName
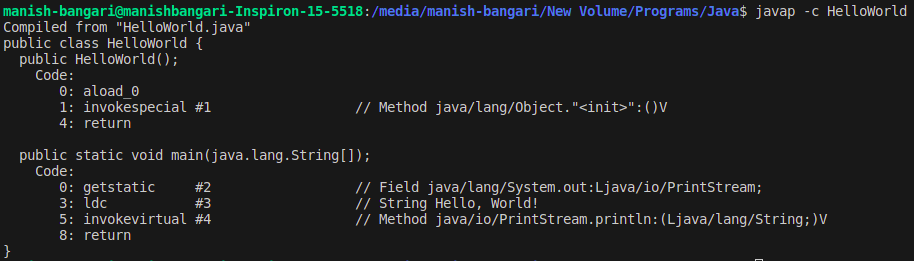
This is a very simplified example. Real bytecode is more complex and includes instructions for a wide range of operations that the JVM can perform.
Remember that understanding bytecode is not typically necessary for everyday Java development. It's mostly used for debugging, performance analysis, or advanced scenarios where you need to understand the low-level details of Java execution.
-
Bytecode Viewer Tools
There are various bytecode viewer tools available that provide a more user-friendly and comprehensive view of the bytecode. Some popular options includes Bytecode Viewer (BCV) and JD-GUI. -
IDE Plugins
Comparison with C/C++
The compilation process in Java has some key differences when compared to C/C++. Here's a brief comparison:
Comparison: Compilation in Java vs. C/C++
| Aspect | Java | C/C++ |
|---|---|---|
| Compilation Language | Java source code (.java files) | C/C++ source code (.c/.cpp files) |
| Compilation Command | javac code.java | gcc code.c -o code (C) g++ code.cpp -o code (C++) |
| Intermediate Output | .class bytecode files | .o (object) files |
| Execution | java code | ./code |
| Platform Independence | Compiled bytecode is platform-independent | Compiled object code is platform-specific |
| Linking | Java bytecode doesn't require linking | C/C++ object files need linking to create an executable |
Conclusion
The compilation process in Java is a meticulous sequence of steps that transforms human-readable code into bytecode, which is executable across diverse platforms. This process encapsulates lexical analysis, syntactic analysis, semantic analysis, intermediate code generation, optimization, and final bytecode generation. By adhering to this process, Java ensures its hallmark portability and platform independence, enabling developers to write applications that transcend hardware and operating systems.
In the realm of Java programming, a profound understanding of the compilation process is indispensable. This knowledge empowers developers to write robust and efficient code while appreciating the intricate mechanisms that underlie Java's remarkable cross-platform compatibility. As technology continues to evolve, a solid grasp of the compilation process remains a foundational skill for every Java technologist.
With this article at OpenGenus, you must have the complete idea of Compilation process in Java.