
Key Takeaways
- Gradient Checkpointing is a memory optimization technique used in deep learning to reduce memory consumption during backpropagation.
- It introduces checkpoint layers at specific points in the network, storing intermediate activations only at these checkpoints, reducing memory requirements.
- Gradient Checkpointing enables the training of extremely deep neural networks that would be limited by memory constraints without this technique.
- It is particularly valuable in real-world applications like training deep neural networks, transformer models, and segmented backpropagation.
- While Gradient Checkpointing reduces memory usage, it introduces computational overhead, so its usage should be considered based on specific requirements.
- Gradient Accumulation simulates larger batch sizes without high memory requirements, while Gradient Clipping prevents exploding gradients for numerical stability, but they serve different purposes than Gradient Checkpointing.
Table of Contents
- Introduction
- Understanding Gradient Checkpointing
- Comparison with Related Techniques
- Advantages of Gradient Checkpointing
- Real-World Applications
- Implementation
- Potential Pitfalls
- Conclusion
Deep learning has witnessed phenomenal growth in recent years, enabling remarkable breakthroughs in various fields, from image recognition to natural language processing. However, the rapid advancement of deep neural networks has also posed significant challenges, one of which is memory efficiency during training. This is where Gradient Checkpointing comes into play. In this comprehensive exploration in this OpenGenus.org article, we will delve into the depths of Gradient Checkpointing, understanding its mathematical foundations, real-world applications, advantages, and potential pitfalls. Gradient checkpointing is also known as activation checkpointing.
1. Introduction
Deep learning has witnessed phenomenal growth in recent years, enabling remarkable breakthroughs in various fields, from image recognition to natural language processing. This transformative technology has empowered machines to learn from data, opening the doors to unprecedented possibilities in understanding and making predictions from complex information.
However, with the rapid advancement of deep neural networks, a pressing challenge has emerged – memory efficiency during the training process. Deep neural networks, often characterized by numerous layers and millions of learnable parameters, impose substantial memory requirements for both the forward and backward passes during training.
1.A. The Memory Challenge in Deep Learning
Before we embark on our journey into the intricacies of Gradient Checkpointing, it's essential to grasp the memory challenge that plagues deep learning. Deep neural networks, often consisting of numerous layers with millions of parameters, require substantial memory resources for both forward and backward passes during training.
The backpropagation algorithm, which calculates gradients for weight updates, is memory-intensive, particularly in very deep networks. As models grow in complexity and depth, they demand ever-increasing memory capacity. This can become a significant bottleneck, limiting the size and complexity of models that can be trained on available hardware.
2. Understanding Gradient Checkpointing
Gradient Checkpointing is a memory optimization technique designed to address the memory challenges associated with training deep neural networks. It is particularly valuable when dealing with extremely deep networks or models with large memory footprints.
2.A. The Checkpointing Mechanism
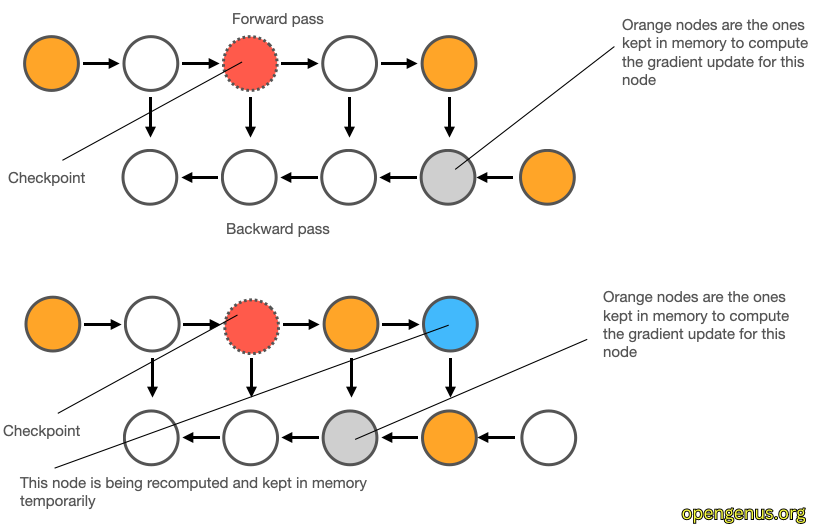
At its core, Gradient Checkpointing introduces checkpoint layers at specific points within the network architecture. These checkpoint layers serve as memory-saving waypoints during forward propagation.
- During the forward pass: Intermediate activations are stored only at the checkpoint layers.
- During the backward pass (backpropagation): Gradients are computed only for the checkpointed layers.
This strategy reduces the memory requirements for storing all intermediate activations, as only a subset of activations is retained.
2.B. Mathematical Representation
The fundamental idea behind Gradient Checkpointing is to break down the computation of gradients (∇L/∇θ) into smaller segments. Suppose we have a deep neural network with N layers, and we insert checkpoint layers at specified intervals. Then, we can compute gradients as follows:
∇L/∇θ = ∇L/∇θ₁ + ∇L/∇θ₂ + ... + ∇L/∇θₖ
Here, ∇L/∇θ represents the gradient of the loss with respect to the model's parameters, and θ₁, θ₂, ..., θₖ are the parameters associated with checkpointed layers.
3. Comparison with Related Techniques
3.A. Gradient Accumulation
Gradient Accumulation involves accumulating gradients over multiple mini-batches before updating the model's weights. This technique is primarily used to simulate training on larger batch sizes without the memory requirements of a truly large batch.
3.B. Gradient Clipping
Gradient Clipping is a technique used to prevent exploding gradients during training. It involves scaling gradients to a certain threshold if they exceed that threshold, effectively limiting the size of gradients to a manageable range.
3.C. Checkpointing vs. Accumulation vs. Clipping
While Gradient Checkpointing, Gradient Accumulation, and Gradient Clipping are all techniques used in deep learning, they serve different purposes:
-
Gradient Checkpointing: Focuses on reducing memory consumption during the backpropagation phase of training by storing intermediate activations at checkpoint layers. This allows for training very deep networks without running into memory limitations.
-
Gradient Accumulation: Addresses memory limitations during the forward pass by accumulating gradients over several mini-batches before performing weight updates. This helps maintain a large effective batch size without requiring large memory capacity.
-
Gradient Clipping: Primarily deals with numerical stability during training by preventing gradients from becoming too large. It is not a memory optimization technique but rather a stability measure.
Each of these techniques plays a crucial role in ensuring stable and efficient deep learning training. The choice of which technique(s) to use depends on the specific requirements and limitations of the problem at hand.
4. Advantages of Gradient Checkpointing
Gradient Checkpointing offers several advantages, making it a valuable technique in deep learning:
-
Memory Efficiency: The primary advantage of Gradient Checkpointing is its ability to significantly reduce memory consumption during backpropagation. By storing intermediate activations only at checkpoint layers, it allows for the training of much deeper networks without exhausting available memory resources.
-
Increased Model Depth: Deep neural networks have shown superior performance in various tasks, but their memory demands often limit their practicality. Gradient Checkpointing enables the training of extremely deep networks that would be infeasible due to memory constraints without this technique.
-
Flexibility: Researchers and practitioners have the flexibility to strategically place checkpoint layers within the network architecture. This enables a balance between memory efficiency and computational time, allowing for fine-tuning based on specific hardware and memory constraints.
5. Real-World Applications
Gradient Checkpointing finds practical applications in various scenarios where memory efficiency is crucial. Below, we explore some of the real-world applications where Gradient Checkpointing plays a vital role:
5.A. Deep Neural Networks
Deep neural networks, characterized by their depth and complexity, have become a cornerstone of modern machine learning. They excel in tasks ranging from image classification to natural language understanding. However, their depth often leads to significant memory requirements during training.
In this context, Gradient Checkpointing offers a valuable solution. Training very deep networks, such as deep residual networks (ResNets), can benefit significantly from this technique. By introducing checkpoint layers strategically, memory consumption is reduced, allowing for the training of exceptionally deep networks that would otherwise be limited by memory constraints.
5.B. Transformer Models
Transformer models have reshaped the landscape of natural language processing (NLP) and other sequence-to-sequence tasks. Notable examples include BERT and GPT-3, which have achieved state-of-the-art results. However, these models are infamous for their large memory footprints.
Gradient Checkpointing comes to the rescue in the context of transformer models. These large-scale models can leverage Gradient Checkpointing to effectively manage memory constraints. By judiciously placing checkpoints within the architecture, researchers can strike a balance between memory efficiency and computational performance, allowing for the training of colossal transformer models.
5.C. Segmented Backpropagation
In certain applications, particularly those involving reinforcement learning with long trajectories or extended sequences, Gradient Checkpointing proves invaluable. Managing memory usage over extended sequences is a challenge, as it can quickly lead to memory exhaustion.
Gradient Checkpointing provides an elegant solution for segmented backpropagation. By introducing checkpoints at appropriate intervals, memory usage remains manageable throughout the training process. This ensures that models can effectively learn from lengthy sequences without running into memory constraints.
These real-world applications highlight the versatility of Gradient Checkpointing in addressing memory challenges across various domains, from image recognition to natural language processing and beyond.
6. Implementation
Implementing Gradient Checkpointing may vary depending on the deep learning framework being used. Popular deep learning libraries like PyTorch and TensorFlow offer tools and APIs to integrate Gradient Checkpointing into custom models.
Here's a simplified example of how Gradient Checkpointing can be implemented in PyTorch:
import torch
from torch.utils.checkpoint import checkpoint
# Define a custom model with checkpointed layers
class CustomModel(torch.nn.Module):
def __init__(self):
super(CustomModel, self).__init__()
self.layer1 = torch.nn.Linear(512, 256)
self.layer2 = torch.nn.Linear(256, 128)
def forward(self, x):
# Checkpoint the computation in layer1
x = checkpoint(self.layer1, x)
x = torch.relu(x)
x = self.layer2(x)
return x
# Instantiate and train the model
model = CustomModel()
# ...
In this code:
-
We begin by importing the necessary libraries, including PyTorch and the
checkpointfunction fromtorch.utils.checkpoint. -
Next, we define a custom model named
CustomModel. This model serves as a straightforward example and comprises two linear layers. -
In the
forwardmethod of the model, we employ thecheckpointfunction to implement Gradient Checkpointing. Specifically, we choose to checkpoint the computation occurring inself.layer1. This decision signifies that, during the forward pass, intermediate activations withinlayer1will be stored only at this checkpoint.
By applying Gradient Checkpointing in this manner, you can effectively reduce memory consumption during the subsequent backward pass. This optimization proves particularly valuable when dealing with deep neural networks or models featuring substantial memory footprints.
The provided example offers a clear illustration of how to incorporate Gradient Checkpointing into a PyTorch model. Similar principles can be adapted for use in other deep learning frameworks such as TensorFlow. This technique empowers you to manage memory efficiently and facilitates the training of deeper models without encountering memory limitations.
7. Potential Pitfalls
While Gradient Checkpointing offers compelling advantages, it's essential to be aware of potential pitfalls:
-
Computational Overhead: Checkpointing introduces additional computational overhead. Storing and retrieving intermediate activations at checkpoint layers can slow down training, particularly on hardware with limited parallelism.
-
Not Always Necessary: Gradient Checkpointing is not always required. In scenarios where memory is not a significant constraint, it may be more efficient to train deep models without the added computational complexity introduced by checkpointing.
-
Placement Challenges: Strategically placing checkpoint layers within the network requires careful consideration. Poor placement can result in suboptimal memory savings or even increased memory usage.
8. Conclusion
In summary, Gradient Checkpointing emerges as a powerful and indispensable tool in the arsenal of deep learning practitioners. It offers a robust solution to the memory challenges that often accompany the training of deep neural networks. By strategically managing memory resources, Gradient Checkpointing opens up new horizons in the development of complex models and fosters breakthroughs across various machine learning domains.
Key takeaways from the application of Gradient Checkpointing include:
-
Enabling Deeper Models: One of the primary advantages of Gradient Checkpointing is its capacity to enable the training of deeper neural networks. As the depth of models continues to be a critical factor in achieving state-of-the-art performance, this technique provides the means to explore more intricate architectures.
-
Memory Efficiency: Gradient Checkpointing excels in memory efficiency. It allows for the allocation of memory resources precisely where they are needed most, reducing unnecessary consumption and mitigating the risk of memory exhaustion.
-
Versatile Applications: From deep neural networks to transformer models and segmented backpropagation, Gradient Checkpointing proves its versatility across a spectrum of real-world scenarios. It adapts to the unique memory constraints of each application, ensuring optimal performance.
However, it's important to exercise caution in its implementation. Gradient Checkpointing introduces computational overhead, and its judicious use depends on the specific requirements and limitations of the problem at hand. Not every model or scenario necessitates Gradient Checkpointing, and its adoption should be guided by careful consideration.
As the field of deep learning advances, Gradient Checkpointing remains a valuable ally, offering solutions to memory constraints and facilitating the development of cutting-edge machine learning models.