
Reading time: 15 minutes
If you ever worked on Open Source projects at OpenGenus and others or even have an idea about what it is, you would know that majority of them uses Git. What is Git? Git is basically VCS (Version Control System) or more accurately DVCS (Distributed Version Control System) . Git is not to be confused with GitHub. Git is VCS and GitHub is a hosting service for files and projects that use Git. Apart from that, Version Control System is pretty self-explanatory term. It helps track the different versions created over time and provide an space efficient technique to record history and changes made to files and directories.
In this article we will just focus on how internal workings of Git rely on trees. But before we get to it, we need to get a general idea about other stuff that Git uses and need to be understood before we get to trees but beware....

Repositories
A Git repository is a database containing all the information needed to retain and manage the revisions and history of a project. In Git, a repository retains a complete copy of the entire project throughout its lifetime. However, unlike most other VCSs, the Git repository not only provides a complete working copy of all the files in the repository, but also a copy of the repository itself with which to work.
Within a repository, Git maintains two primary data structures:
- the object store
- the index
All of this repository data is stored at the root of your working directory in a hidden subdirectory named .git.
The object store is designed to be efficiently copied during a clone operation as part of the mechanism that supports a fully distributed VCS. The index is transitory information, is private to a repository, and can be created or modified on demand as needed.
Now that we know what repositories are, let us see what object store have for us. We don't need to know much about index to understand trees. But in short, the index is a temporary and dynamic binary file that describes the directory structure of the entire repository. More specifically, the index captures a version of the project’s overall structure at some moment in time. It plays an important role in commit and merging.
Git Object Types
At the heart of Git’s repository implementation is the object store. It contains:
- your original data files
- all the log messages
- author information
- dates
- other information required to rebuild any version or branch of the project
Git places only four types of objects in the object store:
- the blobs
- trees
- commits
- tags
These four atomic objects form the foundation of Git’s higher level data structures.
Blobs
- Blobs - Each version of a file is represented as a blob. It stands for: “binary large object”, is a term that’s commonly used in computing to refer to some variable or file that can contain any data and whose internal structure is ignored by the program. A blob holds a file’s data but does not contain any metadata about the file or even its name.
Trees
- Trees - A tree object represents one level of directory information. It records blob identifiers, path names, and a bit of metadata for all the files in one directory. It can also recursively reference other sub-tree objects and thus build a complete hierarchy of files and subdirectories.
Commit
- Commit - A commit object holds metadata for each change introduced into the repository, including the author, committer, commit date, and log message. Each commit points to a tree object that captures, in one complete snapshot, the state of the repository at the time the commit was performed. The initial commit, or root commit, has no parent.
Tags
- Tags - A tag object assigns an arbitrary yet presumably human readable name to a specific object, usually a commit. Although e25e93e02de231e17abc53aa9ec15d971e refers to an exact and well-defined commit. So, by now you've got that HASH is also an important part of Git
Over time, all the information in the object store changes and grows, tracking and modeling your project edits, additions, and deletions.
Now, we are ready to see how Git uses tree structure for its working. We are just gonna take a general example and will not go deep in details.
Version Control using trees
Now, let us see how Git actually uses tree structres for version control, directory structure management, history etc. Before we preoceed, it is to be noted that Git uses SHA1 hashing to point/refer objects: blobs, tress or sub-trees.
Every object in Git has its own HASH value. But obviously for humans its very tedious to refer to their files using HASH values, so TAGS are used to make whole referencing more readable. Now, suppose we made initial commit or initial version of our files and directories, we will get to commit later in this article. Every object in our git will either be a blob or a tree pointing to other trees or blobs. There is a main header/pointer to the root of this structure. The root of the whole tree is called a SNAPSHOT.
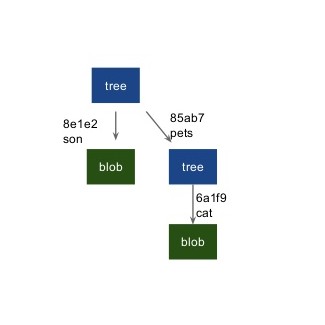
In the figure above, the root is the snapshot and you can notice that blob(son), blob(cat) and tree(pets) are pointed using their respective hashes i.e., 8e1e2, 6a1f9 and 85ab7 respectively. All these blobs and trees are made using git commands but we're not go there (we certainly don't want to complicate things right now). But if you still want to see this for yourself you can easily look up for them. Now, let us say this is Version 1. Now, after some time if we decided to change our blob(son) the structure will change:
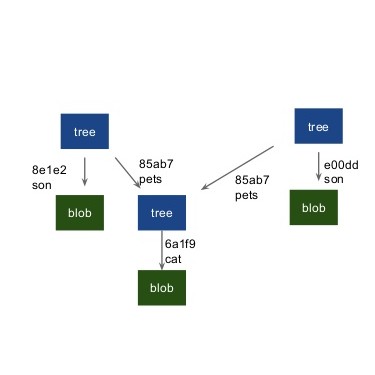
So, if we notice Git is smart and does not all add blobs and trees all over again. It recognizes that tree(pets) is unchanged. Here, like we discussed before, everything needs to be either a blob or a tree. So, we create another tree and this one now points to our new blob(son) and to our older tree(pets) using their respective hash values. Now you may be wondering what about the older blob. That is what used to record the changes made. Actually when changes are made, Git stores the new version like our new blob here and use a pack file to record the differences between this one and last one using the pointer which still sits in the structure. This is how version are monitored and recorded as the structure changes or new versions are made.
Commit Object
Above we saw how changes made are managed using trees but all changes are incomplete unless commit is done. Here, commit object comes into play. Like other obects/trees commit objects also point to trees but they contain essential information: who, when and why the changes made. These information along with the pointers make up the commit object. Commit objects also point to their parent or last commit. When a commit object is made it points to previous commit object or structure which is changed. This is how we can go back from latest commit to previous one and from their to its previous.
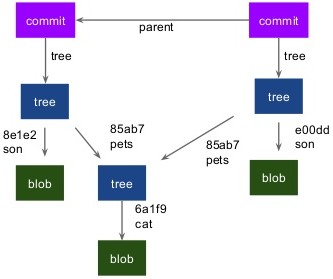
Above image give an idea about how commit object works. Our initial commit is pointed by the commit object when we changed and created new commit which points to our new tree.
There are lot of details we skipped or talked about in brief. But here our main motive was to see how Git uses tree data structure for its working. Actual working and structure is more complex but this should give you a general idea and maybe good enough to win you an argument with your friends :)