
A compiler is responsible for translating high-level source code into low-level code. In this article, we go over a brief overview of the compiler design domain, a very successful field of computer science.
Table of contents.
- Introduction.
- Reasons for studying compiler design.
- From source code to an executable.
- Phases in compiler design.
- Compiler architectures.
- Properties of a good compiler.
- Compiling a simple program.
- Summary.
- References.
Introduction.
A compiler is a program that takes input which is a program written in a high level programming language such as java and produces output which is the target language, while preserving its meaning.
In most cases we will find that different high level programming languages such as Java, C++, C# will have their own specific compilers.
Compilers exists to enable programmers to write working bug free code at compile time so that a user will not encounter them later while using the program.
Not only do they eliminate bugs but code from a compiler is highly optimized.
As opposed to a compiler which compiles code and produces target code ready to be executed, an interpreter reads a program written in a high level language and executes it without producing its translation.
Just In Time compiling demonstrates relationship between compilers and interpreters whereby a program is compiled during its execution, for example, some implementations of Java Virtual Machine(JVM) work by translating bytecode which was previously compiled by a java compiler into machine specific code which then gets executed directly.
Reasons for studying compiler construction.
There are many reasons why we may want to study compilers aside from the interesting problems we get to solve, some are;
- We get to learn very useful algorithms and data structures e.g hashing, precomputed tables, stacks, garbage collection algorithms, dynamic programming, graph algorithms etc, which have applications in other domains.
- Compiler design is a very successful branch of computer science some reasons being there is a proper structuring of the problem, judicious use of formalisms, applicable tools wherever possible just to name a few.
- Designing compilers is similar to file conversion for example TEX typesetting program translates a manuscript into a postscript using the same techniques used in constructing a compiler, same as how browser translates HTML code into a web page and therefore knowledge acquired here can be applied to other domains involving file conversions.
- By understanding the workings of a compiler it makes us better programmers as we can then write more optimal code and debug it with ease since issues will become easier to spot.
- By learning compiler design, one can create programming languages while avoiding pitfalls involved in language design.
- One can also contribute to existing C compilers by coming up with ways to optimize compiled programs or incorporating new programming language features to name just a few. Micro processors and new operating systems are being created and knowing how to utilize them requires continuous improvements in compilers. It is also possible to create better ones than the currently existing ones.
The best way to learn is to do and therefore the best way to learn about compilers is to build one from beginning to end. A great programming language to use would be C since it is currently the most widely used and X86 assembly language which is also the most widely used computer architecture for desktops, servers etc.
Even though this is a daunting task, it can be broken down into small manageable parts which can be easily handled individually.
From source code to an executable.
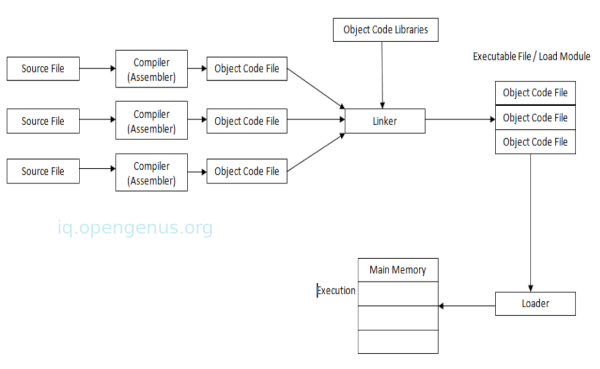
A compiler is just a single program in a tool chain involving other programs essential in the process from when source code is written to when it is running.
These include;
Prepreprocessor: It prepares source code for the compiler, It performs actions such as macro preprocessing where it allows a user to define macros which are short hands for longer constructs, file inclusion, for example in C/C++ where we have header files, these are included into the program text by a preprocessor, other preprocessor functions include rational preprocessing and language extensions.
Assembler: It takes assembly code for example x86 or ARM and produces object code which contains instructions which can be executed by a processor. At this stage the code doesn't know where it will be loaded in memory which lead us to the next program.
A Linker takes one or more object files and library files and combines them into a complete executable program which can be executed.
A Loader usually comes with the operating system, it loads an executable into memory for execution.
Cross compiler: these are used to generate code that can be directly executed as opposed to code that requires further modifications.
Source-to-source compiler: These take source code in one language and transforms them into source code in another programming language.
Others compiler construction tools include;
Scanner generators: which take regular expressions as input and produce a lexical analyzer.
Syntax directed translation engines which given the parse tree, will generate intermediate code by associating one or more translations with the nodes from the parse tree.
Parser generators that take a grammar as input and generate source code which is used to parse the streams of text with the help of a grammar.
Automatic code generators generate machine code for a target machine where each intermediate language operation is translated using a well defined rule and passed into a code generator as input.
Data flow engines optimize code through a process known as data flow analysis where we present information to this engine and intermediate code is compared to find relationships.
Phases in compiler design.
In this and coming articles we will keep our focus on compilers since there the most complex and interesting compared to the other tools in the tool chain.
Phases within a compiler consist of:
- Lexical Analysis: The source code is read and analyzed after which it is divided into tokens which correspond to a symbol as defined in a programming language, e.g variable, number, keyword.
- Syntax Analysis(Parsing): The tokens are arranged in a tree-like structure called a syntax tree which visually reflects the program structure.
- Type checking: The syntax tree is checked to see if it is in violation of consistency requirements, for example, checking if a boolean is used as an integer or if a used variable has been declared and if it is of the right type etc.
- Intermediate code generation: At this stage, the program is translated into a machine independent intermediate language.
- Register allocation: Symbolic variable names which were used in the previous stage are translated into numerical values each corresponding to a register in the target machine code.
- Machine code generation: The code from the previous stage is translated into machine code which is specific to a processor architecture e.g x86, ARM.
- Assembly and Linking: The assembly code is translated into bits for a specific processor architecture which are instructions which can be executed by a processor directly.
At each stage of checking and transformation, stronger invariants of data are passed onto subsequent stages for example, a type checker assumes that there are no syntactic errors and a code generators will assume there are not type errors and thus writing code for following stages becomes easier.
Assembly, Linking and Loading stages are performed by programs that come packaged with the operating system.
Compiler architectures.
Internal architectures of different compilers differ in numerous ways however two universal questions will always define all compilers, these are;
- The width of the compiler
A compiler can be narrow, meaning it reads a small part of a program e.g a few tokens then processes them, produces bytes of object code after which it discards these tokens and repeats this process again and again until the program is completed.
A compiler can also be broad where by it reads the entire program and applies the discussed transformations which results in object code which is written to a file.
Broad compilers need memory proportional to program size while narrow compilers need memory linear to program's length.
With this you can see why narrow compilers are preferred in practice however they can compromise their definition and incorporate a broad component.
Broad compilers are preferred for teaching purposes since they represent a simpler model that agrees with the functional programming paradigm.
- Flow of control:
The question is, among the modules involved in a compiler which has control? In a broad compiler this is a non-issue since each module will have full control over the processor and data during its time however when it comes to narrow compilers the level of complexity increases since when data is moving from module to module control will have to be shifted from time to time.
Properties of a good compiler.
- A compiler should be able to generate correct executable code while preserving the meaning of the source code.
- The compiled code from a compiled should be optimized and run fast.
- A compiler should also be fast in compiling source code, in that compilation time should be proportional to size of the source code.
- A good compiler should be able to spot errors in the source code and report them.
- It should work well with debuggers.
Just to name a few.
Compiling a simple program.
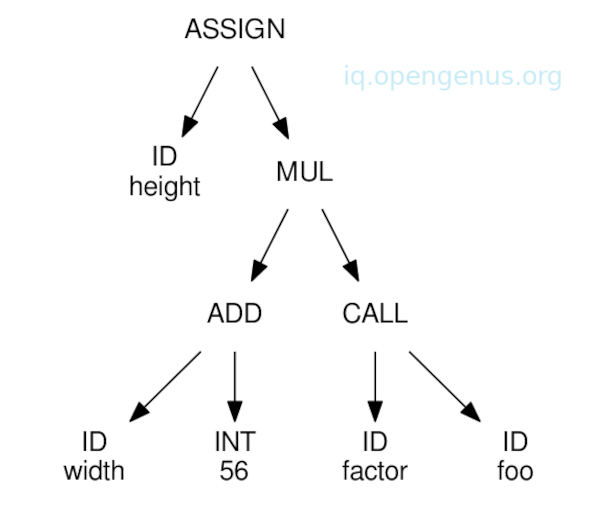
Given the code,
height = (width + 56) * factor(foo);
The scanner reads the source code character by character and identifies boundaries between symbols then produces the following tokens.
id:height
=
(
id:width
+
int:56
)
*
id:factor
(
id:foo
)
;
The purpose of each token is not yet clear for example a + sign could mean integer addition, string concatenation or floating point addition.
Next we determine if the tokens combined form a valid program. The parser confirms with the grammar of a language.
For example we have the following grammar:
1. expr → expr + expr
2. expr → expr * expr
3. expr → expr = expr
4. expr → id (expr)
5. expr → (expr)
6. expr → id
7. expr → int
Each numbered line is a rule which explains how parts of a programming language are constructed.
Rules, 1, 2, 3 describe how an expression can be formed by joining two expressions with operators.
Rule 4 describes a function call
Rule 5 describes how a parenthesis is supposed to be used.
Rules 6, 7 define identifiers and integers as atomic expressions.
The parser will look for tokens that can be replaced with characters on the left part of a rule in the grammar.
A node in a tree is created every time a rule is applied.
The nodes connect to form an AST(Abstract Syntax Tree) which displays the structural relationship between symbols.
Now we want to know the meaning of the program, using semantic routines we traverse the above tree to derive additional meaning by relating parts of a program with each other.
Type checking is also performed here where expression types are checked for consistency.
In this case we assume all four variables are integers.
A post-order graph traversal algorithm is implemented to generate an intermediate representation(IR) instruction for each tree node which resembles an abstract assembly language with load/store instructions, arithmetic operations and registers.
LOAD $56 -> r1
LOAD width -> r2
IADD r1, r2 -> r3
ARG foo
CALL factor -> r4
IMUL r3, r4 -> r5
STOR r5 -> height
At this stage we optimize using various optimization techniques for example we remove dead code and combine common operations.
Generally we do this to reduce the amount of resources the code consumes e.g memory and processing power.
The last step is to convert the intermediate code into assembly code, here we convert it to x86 assembly code.
MOVQ width, %rax # load width into rax
ADDQ $56, %rax # add 56 to rax
MOVQ %rax, -8(%rbp) # save sum in temporary
MOVQ foo, %edi # load foo into arg 0 register
CALL factor # invoke factor, result in rax
MOVQ -8(%rbp), %rbx # load sum into rbx
IMULQ %rbx # multiply rbx by rax
MOVQ %rax, height # store result into height
This code is then passes through an assembler to produce instructions which are directly executed by a x86 processor.

Summary.
A compiler transforms source code which is written in a high level language to low level target code.
Code produced by the compiler is still further from being able to be executed.
A compiler should uphold correctness and it should be fast while preserving the original meaning of the source code.
A very important use for compilers apart from translation and optimization is to report errors so that code produced does not present bugs while being used by a user.