
Introduction:
Reinforcement Learning (RL) has witnessed remarkable advancements in recent years, enabling machines to learn and excel in complex environments. One fascinating application of RL is training an AI agent to conquer the iconic Mario game. In this article, we will delve into the process of training a RL model to beat Mario, step by step.
Understanding Reinforcement Learning:
Reinforcement Learning is a branch of machine learning that deals with training an agent to make sequential decisions in an environment to maximize a reward signal. The agent learns through trial and error, taking actions and receiving feedback from the environment. The goal is to find the optimal policy that maximizes the cumulative reward over time.
Reinforcement learning (RL) is an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
Reinforcement learning differs from supervised learning in not needing labelled input/output pairs to be presented, and in not needing sub-optimal actions to be explicitly corrected. Instead the focus is on finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).
Required Dependencies:
To train the models and run the code in the tutorial at OpenGenus, we will be requiring the below packages. Please install those packages before continuing in this tutorial.
- gym 0.21.0
- gym-super-marios 7.3.0
- nes-py 8.2.1
- pyglet 1.5.21
- stable-baseline3 1.5.0
- torch 1.11.0
You can run those environments easily with pip
For example, to install gym version 0.21.0, you can run
pip install gym==0.21.0
After running this, you will see the gym package installed successfully. Install other packages with the corresponding versions.
Environment Setup:
To train a RL model to play Mario, we need to set up an environment that emulates the game. OpenAI Gym provides an interface to interact with classic video games. Using the Retro-Gym library, we can create a Python environment that emulates the original NES version of Mario.
# Import the game
import gym_super_mario_bros
# Import the Joypad wrapper
from nes_py.wrappers import JoypadSpace
# Import the SIMPLIFIED controls
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
env = gym_super_mario_bros.make('SuperMarioBros-v0')
env = JoypadSpace(env, SIMPLE_MOVEMENT)
done = True
for step in range(100000):
# Start the game to begin with
if done:
# Start the gamee
env.reset()
# Do random actions
state, reward, done, info = env.step(env.action_space.sample())
# Show the game on the screen
env.render()
# Close the game
env.close()

Here, we can see that a Mario game is started and running. Mario is given random inputs from the simple action_space we have. Mario can move right, jump, not move or do a combination of the keys. However, the mario is stuck at pipe if we just give it random commands. It will have a hard time jumping over the second pipe.
Preprocess Environment:
In RL, the agent observes the environment through states. For the Mario game, the state could include the game screen pixels, current score, Mario's position, and other relevant information. To handle the high-dimensional nature of raw pixel data, techniques like convolutional neural networks (CNNs) are commonly used for feature extraction.
Before Training our model, we need to process our environment in order for the model to be fit in our training algorithm
# Import Frame Stacker Wrapper and GrayScaling Wrapper
from gym.wrappers import GrayScaleObservation
# Import Vectorization Wrappers
# Import Matplotlib to show the impact of frame stacking
from matplotlib import pyplot as plt
# Import the game
import gym_super_mario_bros
# Import the Joypad wrapper
from nes_py.wrappers import JoypadSpace
# Import the SIMPLIFIED controls
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
from stable_baselines3.common.vec_env import VecFrameStack, DummyVecEnv
# 1. Create the base environment
env = gym_super_mario_bros.make('SuperMarioBros-v0')
# 2. Simplify the controls
env = JoypadSpace(env, SIMPLE_MOVEMENT)
# 3. Grayscale
env = GrayScaleObservation(env, keep_dim=True)
# 4. Wrap inside the Dummy Environment
env = DummyVecEnv([lambda: env])
# 5. Stack the frames
env = VecFrameStack(env, 4, channels_order='last')
state = env.reset()
state, reward, done, info = env.step([5])
plt.figure(figsize=(20,16))
for idx in range(state.shape[3]):
plt.subplot(1,4,idx+1)
plt.imshow(state[0][:,:,idx])
plt.show()
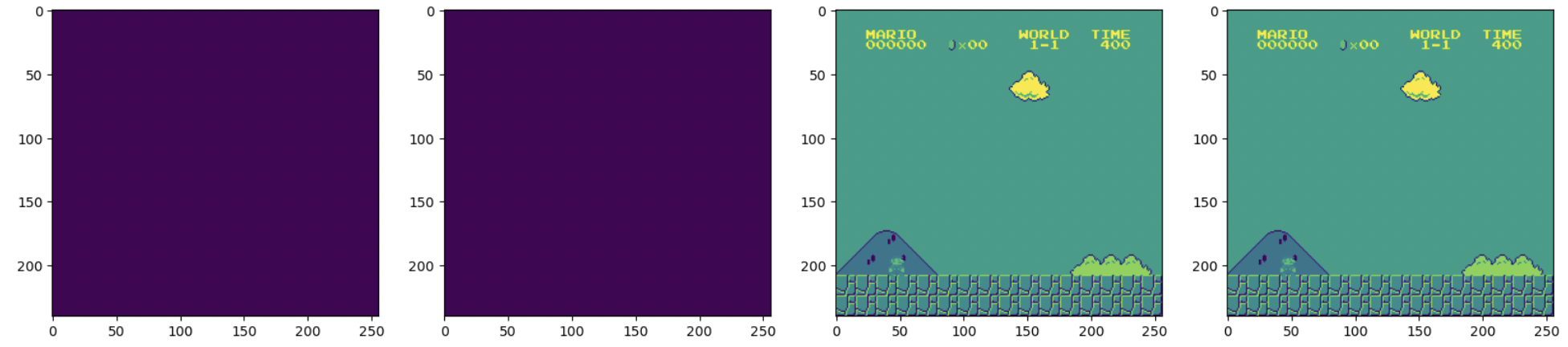
Now, we have chagned up the dataset by simplifying the controls, grayscale the frames, wrapping the environment inside of another dummy environment and also stacking the frames for the trainning. We can see the different states and the training frames through the plots.
Train and Save the model
In reinforcement learning, the hard part is usually just reshaping the data and fitting it to our training environment. We have a lot of great library out there that already implements the learning algorithm and we just need to reshape our data into the correct shape.
Here, we will use the CNN policy from baselines3 to train our model.
# Import os for file path management
import os
# Import PPO for algos
from stable_baselines3 import PPO
# Import Base Callback for saving models
from stable_baselines3.common.callbacks import BaseCallback
model = PPO('CnnPolicy', env, verbose=1, learning_rate=0.000001,
n_steps=512)
model.learn(total_timesteps=1000000, callback=callback)
model.save('model')
Testing our Model
After saving the model, we will see a file stored locally in the folder where we have the python script or the jupyter notebook. Now, we just need to set up the environment to run the model and check out how our model is performing.
model = PPO.load('model')
state = env.reset()
# Start the game
state = env.reset()
# Loop through the game
while True:
action, _ = model.predict(state)
state, reward, done, info = env.step(action)
env.render()
Sometimes, the model doesn't work out and gets stuck somewhere.
Sometimes, the model can beat the level after the training.
You can try different models and try different learning rate and different n_steps. By changing those parameters, the performance of the agent which is mario here will be changed dramatically.
Overview and Conclusion
Training a RL model to beat the Mario game is a fascinating challenge that demonstrates the power of reinforcement learning. By setting up the environment, defining the state representation, designing a reward function, and employing suitable RL algorithms, it's possible to train an AI agent that can master the game. Through continuous exploration, exploitation, and iterative training, the RL model gradually improves its gameplay and achieves impressive results. The techniques employed in training Mario can be generalized to various other RL applications, contributing to the advancement of artificial intelligence in gaming and beyond.
Exploration vs. Exploitation:
Balancing exploration and exploitation is crucial in RL training. The agent needs to explore the environment to discover new strategies while exploiting the already learned knowledge. Techniques like epsilon-greedy exploration or using exploration schedules can help control the agent's behavior during training.
Training Process:
The training process involves iteratively interacting with the environment, observing states, taking actions, and receiving rewards. The RL model learns from the experiences by updating its policy to maximize future rewards. The training process is often time-consuming and may require substantial computational resources.
Hyperparameter Tuning:
RL models involve tuning various hyperparameters, such as learning rate, discount factor, exploration rate, and network architecture. Hyperparameter tuning is crucial to achieving optimal performance. Techniques like grid search or Bayesian optimization can help find suitable hyperparameter combinations.
Evaluation and Testing:
Once the RL model has been trained, it's essential to evaluate its performance. The model can be tested on unseen levels or difficult game scenarios to assess its generalization and robustness. Evaluation metrics could include the average score achieved, the number of levels completed, or the time taken to finish a level.