
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Generative AI (GenAI) is highly effective at producing text responses using Large Language Model (LLM), which are trained on vast amounts of data. The advantage is that the generated text is usually easy to understand and provides detailed, widely applicable answers to the input, or generally known as "prompts". However, the drawback is that AI's responses are limited to the data it was trained on, which may be outdated. In a company-specific AI chatbot, this can result in answers that don't reflect the company's current products or services, leading to mistakes that can undermine trust in the technology for both customers and employees.
This is where Retrieval Augmented Generation (RAG) comes in handy.
The RAG concept was first introduced in the paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" by Patrick Lewis and team at Facebook AI Research, which caught the attention of AI developers and industrial scientists.
This is special case of chatbot architecture (figure 1). RAG provides a means of optimizing the output of an LLM with targeted information, without modifying the underlying model itself; this targeted information can be more recent than the LLM, as well as specific to a particular company and sector. This means that the GenAI system can provide contextually appropriate responses to prompts and base them on extremely recent data.
How does Retrieval-Augmented Generation work ?
Consider all the information a company holds: structured databases, unstructured PDFs and other documents, blogs news feeds and transcripts from past customer service interactions. In RAG, this vast amount of dynamic data is converted into a common format and stored in Knowledge Base (KB) that the GenAI system can access. The data in knowledge base is then processed into vector representations using embedding model. The representations are stored in a vector database, allowing for quick searches to retrieve the correct contextual information. Here's an illustration of the concept:
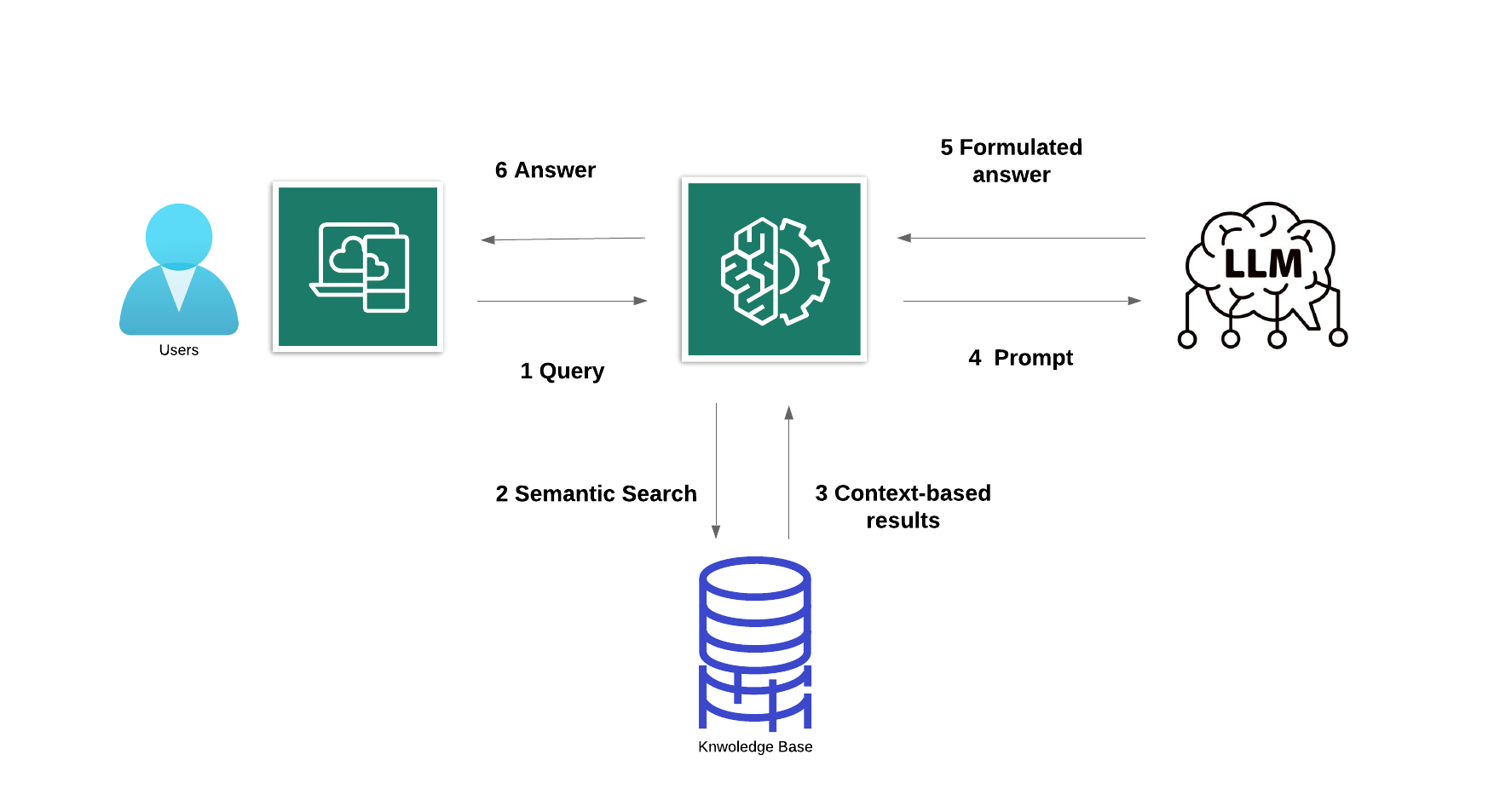
Suppose a user submit a specific prompt (query) to the generative AI system, such as:
"Where will tonight's match be played, who are starting players, and what journalists saying about game?"
The query (1) is converted into vector and used to query the vector database or knowledge base (2), which retrieves relevant contextual information for the question (3). This contextual data, along with the original prompt, is then fed into Large Language Model (LLM) (4), which generates a textuel response based on both its somewhat outdated generalized knowledge and the highly relevant, up-to-date contextual information (5) and (6).
Benefits of Retrieval-Augmented Generation
A key benefit is that while training a generalized LLM is time-consuming and expensive, updating a RAG model is quite the opposite. New data can be continuously and incrementally fed into the embedded language model and converted into vectors. The generative AI system's responses can be fed back into the RAG model, improving its performance and accuracy as it learns from how similar queries were previously handled.
Another advantage of RAG is its use of a vector database, allowing the generative AI to provide specific sources for the data cited in its responses—something LLMs can't do. This means that if the AI generates an inaccurate result, the document containing the incorrect information can be quickly identified and corrected, with the updated data then added to the vector database.
Conclusion
In summary, RAG enhances the capabilities of generative AI by providing faster, more contextually relevant, and evidence-based responses. Its ability to integrate fresh data and reference specific sources offers a level of accuracy and transparency that traditional LLMs cannot achieve on their own. This combination makes RAG a powerful tool for improving the reliability and relevance of AI-driven interactions.