
In this article, we have explored the System Design of YouTube which is a video hosting and sharing platform with over 1 Billion active users. It is the second most used web application just after Google Search.
Table of contents:
- Introduction to YouTube
- Have you ever wondered how YouTube actually works?
- Requirements of the System
- The system's capacity
- APIs of YouTube
- Design at the highest level
- Database of YouTube
- Sharding
- Caching
- Load Balancing
- Content Delivery Network (CDN)
- Tolerance for Faults
Pre-requisites:
Introduction to YouTube
YouTube is a Google-owned online video sharing and social media network based in the United States. Steve Chen, Chad Hurley, and Jawed Karim founded it on February 14, 2005. It is the second-most-visited website in the world, immediately behind Google.
YouTube has over one billion monthly users who watch over one billion hours of video each day. As of May 2019, more than 500 hours of video content were being uploaded per minute. For many businesses, it is one of the best advertising-based platforms. YouTube allows users to create, watch, and search videos, as well as use features such as disliking and commenting on videos.
Have you ever wondered how YouTube actually works?
Designing YouTube is a difficult and time-consuming task. We'll go over the core principles that you'll need to create such Video Sharing service.
Requirements of the System
Functional Requirements:
- Videos should be able to be uploaded by users.
- Video sharing and viewing should be possible for users.
- Users can conduct searches based on the titles of videos.
- Our services should be able to track video statistics such as likes/dislikes, total views, and so on.
- Video comments should be able to be added and seen by users.
Non-functional Requirements:
- The system should be extremely dependable; any video submitted should not be lost; and it should be extremely accessible. If a user doesn't view a video for a time, consistency may suffer (in the interest of availability), but it should be alright.
- Users should be able to watch videos in real time without experiencing any lag.
The system's capacity
A single server cannot accommodate the volume of data because the system is intended to handle considerable traffic on a daily basis. A cluster of servers will provide service to the system. Even if one server fails, the client should not experience any performance concerns.
Assume we have 1.5 billion overall users, with 800 million of them active on a daily basis. If a consumer watches five videos each day on average, the total video views per second is:
800M 5 / 86400 sec => 46K videos/sec
Assume that our upload:view ratio is 1:200, which means that for every video upload, 200 videos are seen, resulting in 230 videos posted each second.
500 hours 60 min 50MB => 1500 GB/min (25 GB/sec)
Estimates for storage:
Assume that 500 hours of videos are added to Youtube every minute. If one minute of video requires 50MB of storage on average (videos must be stored in different codecs), the total storage required for videos uploaded in a minute is:
500 hours 60 min 50MB => 1500 GB/min (25 GB/sec)
These figures are estimations that do not account for video compression or replication, which would alter our calculations.
Estimated bandwidth:
We'd be getting 300GB of uploads every minute if there were 500 hours of video uploads every minute and each video upload took 10MB of bandwidth.
500 hours 60 mins 10MB => 300GB/min (5GB/sec)
We'd require 1TB/s of outbound bandwidth if the upload:view ratio was 1:200.
APIs of YouTube
Because YouTube is a very loaded service, it uses a variety of APIs to keep things running smoothly. Video sharing services can be built using a variety of APIs, including video, addComment, search, recommendation, and many others. We have three high-level functioning APIs for this service, and we can develop it using either SOAP or REST architecture.
The following are possible API specifications for uploading and searching videos:
uploadVideo(api_dev_key, video_title, vide_description, tags[], category_id, default_language, recording_details, video_contents)
Parameters:
api_dev_key (string): A registered account's API developer key. This will be used to throttle users based on their quota allocation, among other things.
video_title (string): The video's title.
Video_description (string): An optional video description.
tags (string[]): Tags for the video that are optional.
category_id (string): The video's category, such as Film, Song, People, and so on.
default_language (string): English, Mandarin, Hindi, and so forth.
recording_details (string): The video's recording location.
video_contents (stream): This is the video that will be uploaded.
Returns: (string)
A successful upload will result in an HTTP 202 (request acknowledged) response, and the user will be alerted via email with a link to the video after it has been encoded. We can also make a queryable API available to inform users about the status of their uploaded videos.
searchVideo(api_dev_key, search_query, user_location, maximum_videos_to_return, page_token)
Parameters:
api_dev_key (string): A registered account of our service's API developer key.
search_query (string): The search terms in a string.
user_location (string): The user's location when conducting the search.
maximum_videos_to_return (number): The maximum number of videos that can be returned in a single request.
page_token (string): This token will be used to designate which page from the result set should be returned.
Returns: (JSON)
A JSON object holding data about a list of video resources that match the search query.
Each video resource will include a title, a thumbnail, a date of production, and the number of views it has received.
Design at the highest level
Various components are necessary for this system to function in a well-coordinated way and accomplish all of its objectives. To keep the service up and running regardless of traffic, all of the components must be available and functioning in an acceptable number.
Processing Queue:
• Each video will be added to a processing queue and then de-queued for encoding, thumbnail creation, and storage later.
• Encoder: This program converts each submitted video into a variety of formats.
• Thumbnail generator: For each video, we'll need a few thumbnails.
• Video and thumbnail file storage: We'll need to store video and thumbnail data in a distributed file system.
• User Database: We'd need a database to hold user data, such as name, email, and address.
• Metadata database for video storage: The metadata database will hold all information about videos, including title, file path in the system, uploading user, total views, likes, dislikes, and so on. It will also be utilized to save all of the video comments.
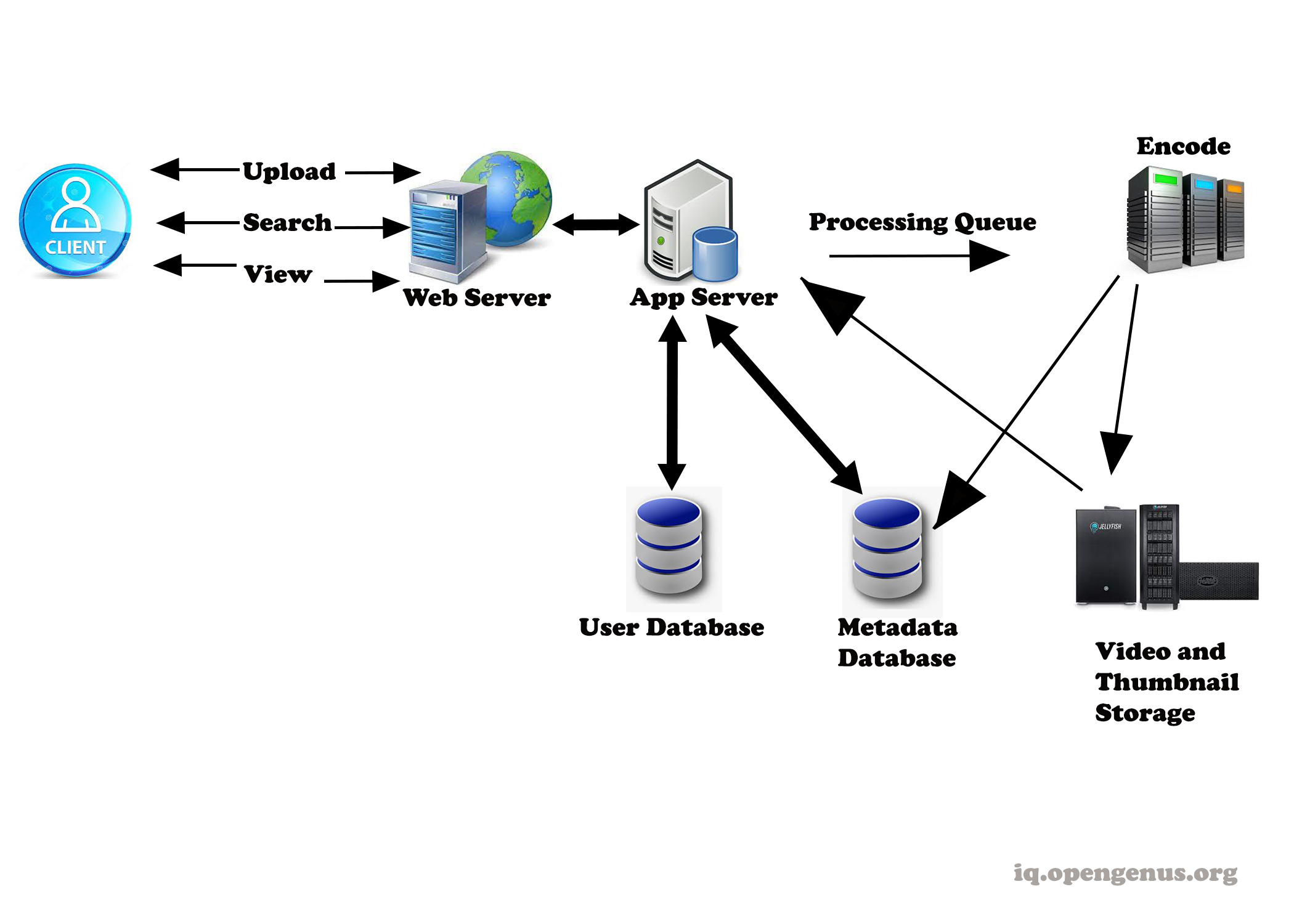
We'll focus on designing a system that can fetch videos rapidly because the service will be read-heavy. We may expect a read:write ratio of 200:1, which equals 200 video views for every video uploaded.
What kind of storage would there be for videos?
A distributed file storage system such as HDFS or GlusterFS can be used to store videos.
What is the most effective way to manage read traffic?
We should separate our read and write traffic. We can split our read traffic over numerous servers since each video will have multiple copies. We may use master-slave arrangements for metadata, with writes going to the master first and then being replayed on all slaves. Such configurations might result in data staleness, for example, when a new video is added, its metadata is placed in the master first, and our slaves will not be able to access it until it is replayed at the slave, delivering stale results to the user. This staleness may be acceptable in our system because it is just temporary and the viewer can watch new videos within a few milliseconds.
What would be the storage location for thumbnails?
The number of thumbnails will far outnumber the number of videos. If we estimate that each movie will have five thumbnails, we'll need a storage system that can handle a large amount of read traffic. Before settling on a thumbnail storage method, there will be two factors to consider:
Thumbnails are little files with a maximum size of 5KB.
When compared to videos, read traffic for thumbnails will be massive. Users will watch a single video at a time, although they may be seeing a page with 20 thumbnails of other films.
Let's look at the pros and cons of saving all of the thumbnails on disk. Given the large number of files, reading them requires a large number of seeks to various regions on the disk. This is inefficient, and increased latencies will occur.
Bigtable is a good option since it merges numerous files into a single block for storage on the disk and reads a modest quantity of data quickly. These are the two most important prerequisites for our service. Keeping hot thumbnails in the cache can also assist to reduce latencies, and because thumbnail files are tiny, we can easily cache a large number of them in memory.
Video Uploads: Because videos might be large, we should enable resuming from the same place if the connection stops while uploading.
Video Encoding: Newly uploaded movies are saved on the server, and a new job to encode the video into several formats is added to the processing queue. The uploader is alerted when all of the encoding is complete, and the video is made accessible for viewing and sharing.
Database of YouTube
We need to keep track of a lot of data that's being submitted to the service. The material, as well as information about the people who use the service, must be stored. MySQL may be used to store information about users, videos, and their metadata. The videos, on the other hand, may be saved in AWS S3 No-SQL databases.
The following information should be included in each video:
- VideoID
- Title
- Description
- Size
- Thumbnail
- Uploader/User
- Total number of likes
- Total number of dislikes
- Total number of views
We need to keep the following information for each video comment:
- CommentID
- VideoID
- UserID
- Comment
- TimeOfCreation
- User data storage - MySql
- UserID, Name, email, address, age, registration details etc.
Because the YouTube service must be read-heavy, the system must be built to properly manage all requests. We may use the cache to provide users with frequent material with little delay. To handle requests effectively, the video material should be mirrored on many servers. The system should store duplicates of metadata and user databases in addition to content. Load balancers should be used to spread traffic. A load balancer can be deployed at any level of the system, including between the application server and the metadata database. When a user requests a piece of content, the system searches the database for it and returns it to the user.
Sharding
We need to disperse our data over numerous machines so that we can do read/write operations effectively because we have a large number of new videos every day and our read load is also incredibly high. We may partition our data in a variety of ways. Let's take a look at each of the possible sharding techniques one by one:
Sharding based on UserID: We can attempt storing all of a user's data on a single server. We can send the UserID to our hash function while saving, and it will map the user to a database server where all of the information for that user's films will be stored. While searching for a user's movies, we can utilize our hash function to locate the server containing the user's data and read it from there. We'll have to ask all servers to find videos by title, and each server will return a collection of videos. Before sending the results to the user, a centralized server would aggregate and rank them.
There are a few drawbacks to this strategy:
What happens if a user gets well-known? There might be a lot of queries on the server that are holding that user, causing a bottleneck in speed. This will have an impact on our service's overall performance
.
Some people, in comparison to others, may accumulate a large number of videos over time. It's tough to keep a consistent distribution of data from a rising number of users.
We must either repartition/redistribute our data or utilize consistent hashing to balance the load amongst servers to recover from these circumstances.
Sharding based on VideoID: Our hash function will map each VideoID to a random server where the Video's information will be stored. We will query all servers to discover a user's videos, and each server will return a collection of videos. Before sending these results to the user, a centralized server will compile and rank them. This solution solves our problem of popular users, but it moves the problem to popular videos.
We can increase performance even further by putting a cache in front of the database servers to store hot videos.
Caching
Our service requires a large-scale video distribution infrastructure to serve internationally scattered consumers. Using a huge number of geographically distributed video cache servers, our service should bring its material closer to the user. We need an approach that maximizes user speed while simultaneously distributing the load equitably among the cache servers.
To cache hot database rows, we can add a cache to metadata servers. Application servers can rapidly verify if the cache has the needed rows by using Memcache to cache the data before reaching the database. For our system, the Least Recently Used (LRU) policy may be an appropriate cache eviction strategy. The least recently seen row is discarded first under this policy.
Load Balancing
We should implement Consistent Hashing among our cache servers, which will aid in load balancing. Due to the varying popularity of each video, we will be adopting a static hash-based approach to map videos to hostnames, which may result in unequal demand on the logical replicas. If a video gets popular, for example, the logical replica corresponding to that video will see more traffic than other servers. These unbalanced loads for logical replicas might lead to unbalanced load distribution on physical servers. Any busy server in one area can send a client to a less busy server in the same cache location to alleviate this problem. For this circumstance, we may employ dynamic HTTP redirections.
However, there are several disadvantages to using redirections. First, because our service tries to load balance locally, several redirections are possible if the server receiving the redirection is unable to provide the video. Furthermore, each redirection necessitates an extra HTTP request from the client, resulting in longer delays before the video begins to play. Furthermore, because higher tier caches are only available at a limited number of sites, inter-tier (or cross data-center) redirections send a client to a distant cache location.
Content Delivery Network (CDN)
A content delivery network (CDN) is a network of dispersed computers that provide web content to users based on their geographic location, the origin of the web page, and the presence of a content delivery server.
Most popular videos may be moved to CDNs, which reproduce material in various locations. Videos are more likely to be closer to the user, and videos will stream from a friendlier network with fewer hops.
CDN computers make extensive use of caching and may deliver videos almost entirely from memory.
Our servers in multiple data centers can provide less popular videos (1-20 views per day) that are not cached by CDNs.
Tolerance for Faults
For database server distribution, Consistent Hashing should be used. Consistent hashing will not only assist in the replacement of a dead server, but also in the load distribution across servers.
Recommended video: YouTube System Design
Video on YouTube System Design by Renaissance Engineer channel.
Important ideas such as how to quickly estimate capacity needs based on provided data, high-level system architecture, and general interview recommendations for system design will be covered.
With this article at OpenGenus, you must have the complete idea of System Design of YouTube.