
From the topic itself, one would have got the idea that in this article we will be discussing Google Search. We have explored the System Design of Google Search and the hardware infrastructure, technologies and strategies that makes Google Search return results from Millions of webpages in a fraction of a second.
Table of contents
- What is Google search?
- System Requirements
- What are its major components
- Cache used by google
- How is ML techniques used with queries? (BERT)
- Technologies used in buiding google search.
- How it handle failures?
- Why it is a good choice over other alternatives.
- Conclusion
WHAT IS GOOGLE SEARCH?
It is a search engine which is built to search for the query among more than billions of web pages available on internet and out of them presenting the most relevant answers to the search that the user has typed into the search bar.
SYSTEM REQUIREMENTS
We do need to know the number of people using the website and the total number of websites available in total. Currently, there are around 1.2 Billion websites in the World and out of which 200 million of these websites are active. And an interesting fact to note is that around 0.2M new websites are created everyday with 3.5 billion google searches everyday, more precisely 40,000 queries every second.
Google Search keeps track of data in each page so that it can serve information from the page for user queries. This data is stored in Google's index.
We can make a reasonable assumption that each page results in 10MB of data. Note this is considering Images as well. If we consider only text, 1MB is a good estimate.
On average, each active website will have 120 pages in total on average. An inactive website will have 1.5 page on average. As 0.2M websites are created everyday, 0.2M pages are added. Consider there are 200M active websites and this number increases by 20M each year (as many websites become inactive), the current memory requirements are:
200M * 120 * 10MB + 1.2B * 1.5 * 10MB
= (2,34.375M + 17.578M) GB
= (2,51.953M) GB
= 0.25B GB = 0.25M TB = 250 PB
So, the memory requirement is 250 PB (petabyte). As a general practice 20% memory is kept in reserve, so the total available memory should be 300 PB.
On average, 0.2M new pages need to be indexed (write task) so the crawler has 0.2M tasks everyday.
On average, there are 3.5B searches (read tasks) everyday which the search engine needs to handle.
So, on average, Google Search should have the capacity to handle atleast 3.6B events/ processes everyday. Note, the write tasks are significantly less compared to read tasks.
So:
- Memory requirements: 300 PB
- Read tasks: 0.2M
- Write tasks: 2.6B
WHAT ARE ITS MAJOR COMPONENTS?
- One can say that we do need a UI to be presented to our users. Though specifically talking about google search bar it's just the text box for searching the query.
- Now what next after typing a query in the search bar , we do need to respond to the query . so, a search backend would be needed to look upto its search index, and responds to the UI.
- Now , one thing to note is that there can be multiple webpages which fetch the answers to the query so how to get a most optimal page.
Let's discuss in brief about all the points mentioned above
Talking about the first one i.e UI
A simple UI which is easy to understand and use is the beauty of google search.
All one needs to do is write a query and than click on the search button where sending is triggered by the user clicking a search button or one can also say that's how a UI sends the search query to the search backend.
Now what next we triggered our request
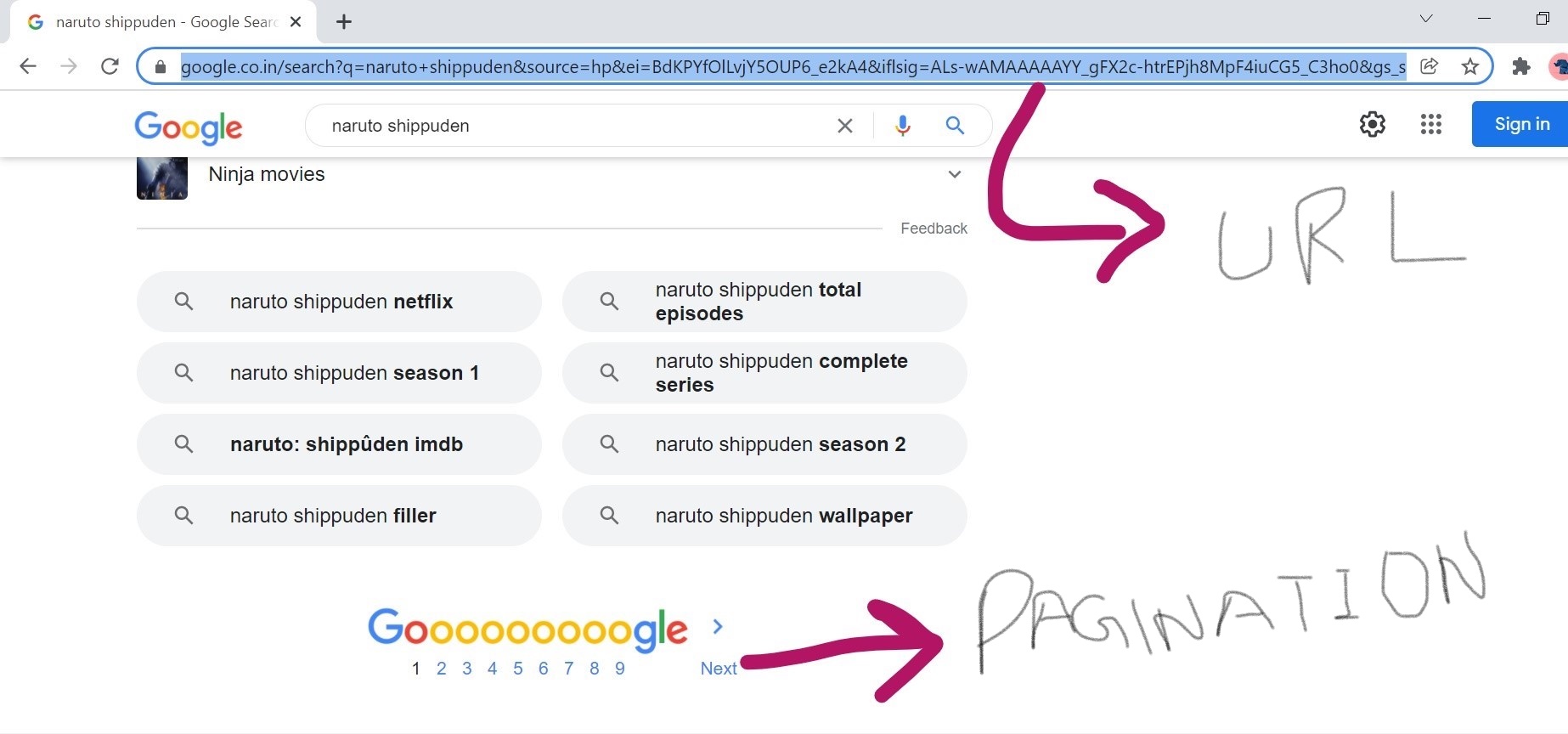
Technically one can also say the search query is sent as a parameter in an HTTP Get request, which allows for sharing the queries as a URL that directly pulls up the results when pasted in a browser. where out of multiple results the most optimal ones appear (i.e sorted by relevance) in a form of a list paginated(i.e some fixed number of webpages occuring on the first page and rest on other pages) to improve the search experience.
Have a look at the image below for clear view of the above statements.
Now, let's talk about the backend part where the real logic implementation is there
Our backend sees our input as collection of word where there is no logic between the words altogether so after receiving the query as string it's first step is to tokenize the string (i.e a process where the string is broken into several parts) Now a search index is maintained and for each word it goes to the search index where the search index is the word to URL index like have a look at the url in the above image it has "naruto+shippuden" in it.
Index-google indexes webpages by building a data structure known as inverted index. Such an index obtains a list of webpages by a query word.
After this it points to a list of all the relevant URLs, where each of which has related metadata(a tittle which is independent of the word) attached to it.
Now, how can one say among all the possible urls this particular URL is the most optimal url , that's where relevance score or page rank comes into picture. A page rank is basically how optimal or relevant a page is in comparison with other pages having almost similar content.
Hey wait!?
You can’t win without showing up for the race in the first place.
I mean before discussing about page rank let's know how new webpages are added / index updated?
Google discovers new web pages by crawling (process of following hyperlinks on the web to discover new content.) the web, and then they add those pages to their index. They do this using a web spider called Googlebot.
Crawlers renders the content of the page, just as a browser does. But keeping note of key signals — from keywords to website freshness — while maintaining track of it all in the Search index. so when it says indexing/adding a webpage, we add it to the entries for all of the words it contains.
PAGE RANK?
To mainatin a page rank we have a index builder where it only processes a webpage for the first visit,and after which each revisit only increments the visit count.
Wait But let's discuss how to.
So , intitally an index builder starts with an empty global URL list and a counter variable which increments everytime after a revisit.
The main factor is obviously how relevant a search word is to the webpage. Here a very common approach for information retrieval is used (i.e: TF-IDF) — term frequency inverse document frequency. Its formula has many variations. The core idea is that how much a webpage is relevant to a word which eventually depends on the frequancy of the word in webpage, but we about the words such as "The , is ,we" which happen to be used in large amount but has no relevance to the search.
So, for the final score of a URL to a word should also cosider the importance of URL itself.So after the index builder finishes crawling the web , we should go back and update all the relevance scores in the search index to a weighted sum of the word relevance and the URL importance.
The last step is to sort URLs for every word in the search index.Now the search index is optimized for read because the backend can just merge-sort the URL lists for search words into the final response.It also helps alleviate the memory concern because the backend only needs to read a small part of the URL lists now that the URLs for every word in the search index are all in the desired order.
Cache used by Google Search
Cache- It is smaller and faster memory that stores copies of the data from frequently used main memory locations which helps us to asscess data very quickly.
There are two kinds of caches:
- Browser cache (Firefox, Chrome, etc.)
- Proxy cache.
Google uses the cached version to judge its relevance to a query. Google's servers are generally much faster than many web servers, so it is often faster to access the cached version of a page than the page itself.
one more intresting thing apart from fast query is that if a website has been deleted by its owner, Google Cache provides a backup of the most recent version with all its content. In addition, the Google cache is a clue to the last time the GoogleBotcrawled the page.
But there is a problem with it too sometimes Google does not create a new version during the reindexing of a web page. An older version can therefore be displayed in the cache and the SERPs even if the content has been updated several times. For SEO(search Engine Optimization) purposes, this can be a problem. Users may not find the most recent content on a website if Google's cache is updated less frequently than the site itself. If you find that this is a recurring problem, you can use the following meta tag in the header of your source code:
<meta name= »robots » content= »noarchive » />
How is ML techniques used with queries? (BERT)
Many times it might have happened to you , you don't know actually what you are searching but randomly type some words you remember to search without even spellcheck but still google searches try thier best to give you the best possible result for the query or the other way round sometimes you just type sandwiches there might be chance it will show you the recipe or maybe the places near by but How?
A neural network-based technique for natural language processing (NLP) pre-training called Bidirectional Encoder Representations from Transformers(BERT).
This technology enables anyone to train their own state-of-the-art question answering system.Particularly for longer or more conversational queries, or searches where prepositions like “for” and “to” matter a lot to the meaning, Search will be able to understand the context of the words in your query(i.e one can search in a way that feels natural). BERT models instead of focusing on the word focuses on the intent behind search queries.Some of the models built with BERT are so complex that they push the limits that traditional hardware can't do so for the first time they are using the latest Cloud TPUs to serve search results and get you more relevant information quickly.
Technologies used in building Google Search
Talking about the techstack used by google how about we compare it with it's alternatives also to get a clear idea google preferrences.
1.Products: google search , google maps , google meet, gmail etc.
2. Distributed Systems Infrastructure: GFS, MapReduce, and BigTable
GFS - Google file system is a large distributed log structured file system in which they store in a lot of data.
Why do we need to build a file system ? like we do have other options such as
Amazon elastic file system, Azure Files etc which eventually are strong compititors of GFS as well currently.
A GFS cluster consists of multiple nodes. where the nodes are further divided into two types:-
- one Master node
- multiple Chunkservers
Each file is divided into fixed-size chunks stored in Chunkservers. where Each chunk is assigned a globally unique 64-bit label by the master node at the time of creation, and logical mappings of files to constituent chunks are maintained.
where each chunk is replicated several times throughout the network. At default, it is replicated three times, but this is configurable. Files which are in high demand may have a higher replication factor, while files for which the application client uses strict storage optimizations may be replicated less than three times - in order to cope with quick garbage cleaning policies.
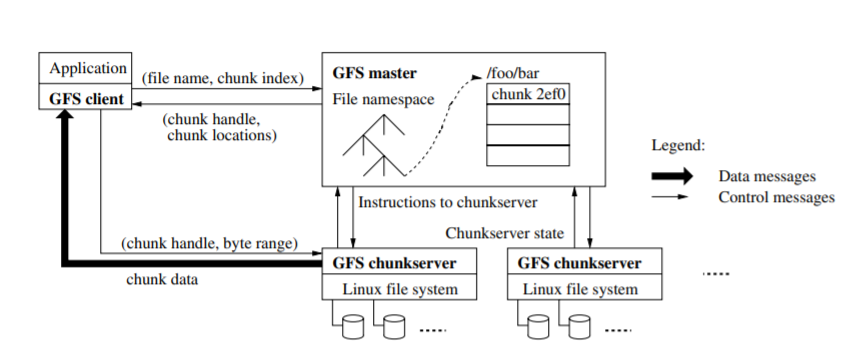
Because they control everything .
Some advantages of the above system design are:-
- Simple design: Clearly the focus was on simplistic design while they were making few important decisions. This is in accordance with the Google's ideologies remember the simple UI.
- high reliability across data centers
- scalability to thousands of network nodes
- reliable storage where Corrupted data can be detected and re-replicated.
- support for large blocks of data which are gigabytes in size.
- efficient distribution of operations across nodes to reduce bottlenecks.
MapReduce- you have a good storage system(GFS) now what next we need a programming model and an associated implementation for processing and generating large data sets.
A MapReduce provides a nice way to partition tasks across lots of machines,Handle machine failure which Works across different application types, like search and ads. Almost every application has map reduce type operations. You can precompute useful data, find word counts, sort TBs of data, etc.
Bigdata- It is a distributed hash mechanism built on top of GFS. which provides lookup mechanism to access structured data by key. GFS stores opaque data and many applications needs has data with structure. By controlling their own low level storage system Google gets more control and leverage to improve their system.
- Computing Platforms: a bunch of machines in a bunch of different data centers
in simple words deploying or hoting our application at low cost.
Let us talk about the Hardware (Google data centers)
Google data centers are the large data center facilities Google uses to provide their services, which combine large drives, computer nodes organized in aisles of racks, internal and external networking, environmental controls (mainly cooling and humidification control), and operations software (especially as concerns load balancing and fault tolerance).
The original hardware (circa 1998) that was used by Google when it was located at Stanford University. As of 2014, Google has used a heavily customized version of Debian (Linux) which they migrated from a Red Hat-based system incrementally in 2013.
HOW IT HANDLE FAILURES?
when traffic is high enough that even degraded responses are too expensive for all queries then it practice graceful load shedding, using well-behaved queuing and dynamic timeouts. Other techniques include answering requests after a significant delay known as “tarpitting” and choosing a consistent subset of clients to receive errors, preserving a good user experience for the remainder.
Why it is a good choice over other alternatives?
1.Google is generally quicker than the other search engines at bringing back results. It is able to deliver millions of results in 0.19 of a second.
2.Google has a lot more sites in its index. It picks up new sites faster than any other engine, so you are able to search the latest news, latest sites and just loads more sites in general.
3.Google’s algorithm is much more sophisticated than the other engines. They should be better at determining which sites are the most relevant and which ones aren’t – especially with continous updates to their algorithm to keep up with ever-evolving digital behaviours.
CONCLUSION
Google is a fully-automated search engine that uses software known as web crawlers that explore the web on a regular basis to find sites stored and updated in Google fIle system to add to our index using mapreducer and providing users to search queires really faster using the cache and also improving the quality of the searches based on the indent of search rather than just the word matching algorithms, the software and hardware are as simple as the UI but the depth of it is like a pacific ocean (FUN -FACT The press revealed the existence of Google's floating data centers along the coasts of the states of California (Treasure Island's Building 3) and Maine. The development project was maintained under tight secrecy. where the data centers were 250 feet long, 72 feet wide, 16 feet deep.)
With this article at OpenGenus, you must have the complete idea of System Design of Google Search.