
Introduction to Caching
What is cache?
There's a OpenGenus logo at the top-left corner of this page and this page also has the favicon of OpenGenus. If you open another article in OpenGenus, the same logo and favicon will still be there, meaning it is common for any page on OpenGenus.
In normal cases, your browser will need to re-download the logo every single time you visit a different page on this site, but that would be a waste of resources and time. So, instead, your browser stores the logo, and other data which are common for multiple pages, on your local machine (computer) in the cache.
In simple words, cache is a place where the browser stores multimedia files and other files of a website like logo, fonts, etc. to avoid re-downloading them repeatedly. Your browser would run a lot slower without this feature, because every site you opened would require re-downloading tons of files. Thus, cache memory saves the bandwidth and speeds up the browsing.
HTTP Caching:
The basic purpose of HTTP caching is to provide a mechanism for applications to perform faster and scale better. But HTTP caching is applicable only to requests where the database is not updated. This is because, once the database is updated, the cache should also be cleared and the data must be fetched to cache again from the database so that the data in cache is up to date with the data in database. This means that GET requests can be cached but POST requests cannot be cached.
Why does clearing cache sometimes fixes the bugs in the website:
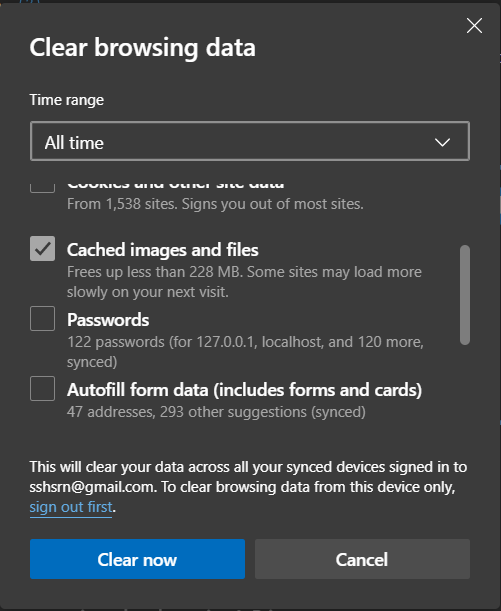
Many times, there is a difference between the version of a website cached (saved) on your local machine (computer) and the version that you are loading from the web. This conflict can lead to some errors or glitches, and clearing the cache can help when nothing else seems to. Clearing the cache deletes the locally saved data and again fetches the updated data from the database thus, making the website working good.
Cache vs. Cookies:
In most browsers, the options for clearing the cache and clearing cookies are in the same place, but they are not the same thing.
-
Cache stores files downloaded directly from the websites a user visits, like multimedia files, fonts,etc. The cached files are usually the same for any user visiting a website.
-
On the other hand. cookies store information about the user and the user's online activities. Cookies also keep track of the sites a user is logged in.
What is Cache Stampede?
Cache stampede problem is a situation that occurs when a cache item expires or is deleted, leading to multiple requests seeing a cache miss(cache miss happens when the required data is not available in the cache memory) and regenerating that same item at the same time. Cache stampede creates too much load on the database.
Cache stampede is also called cache choking, cache
miss storm, or dog-piling.
Let us take a particular case where a user makes a GET request to the server and the response is obtained from the stored cache memory and returns to the user. Now, let us say that there are N users and one of the user POSTs to the database which updates the database and clears the cache. Assuming that the other N-1 users are just browsing the site and try to GET details from the database. Now that the cache is cleared, they will have to read from the database directly and all the N-1 users post the same request to the database as a query. Due to this overcrowding, a query which takes just a few milliseconds to execute might take a lot more time and in some cases, the response might not even be received.
How to prevent cache stampede
Here is a video by facebook about cache stampede!. Click here
In general, there are three approaches to avoid cache stampede:
- External recomputation,
- Probabilistic early expiration,
- Locking.
External recomputation
As the name says, in this method, an external process will re-compute the values and update cache either on predefined regular intervals or whenever a cache miss happens.
Probabilistic early expiration
When an expiration of cache nears, one of the processes in the system will volunteer to re-calculate the cache value and to re-populate cache with a new values.
Locking
This one is the simplest but also the most versatile out of the three. As soon as a process encounters a cache miss, it will set a global lock on re-computing the requested value. This will prevent other processes from attempting the same recompute. This is very much similar to the concept of Mutual Exclusion and Locks in Operating Systems where the shared memory(critical section) is locked and all the other processes are prevented from accessing the shared memory when one process is writing or updating the shared memory. Once the first request computes and caches this value, it will write to the cache, and release the lock.
# A simple implementation of lock and key with JavaScript
function lock(secret) {
const key = Symbol('key')
return {
key, unlock(keyUsed) {
if (keyUsed === key) {
return secret
}
else {
// do something else
}
}
}
}
const { key, unlock } = lock('JavaScript is Awesome!')
unlock(key)