
In this article we will talk about a very popular model that was a revolution in the natural language processing sector that provide more fast and more accurate results than anything provide before, we will take you to a journey with Distilled-GPT2 model.
In short: Distilled GPT-2 is a light version of GPT-2 and has 6 layers and 82 million parameters. The word embedding size for distilGPT2 is 768.
Table of contents :
1. Generative pre-trained language model.
2. Transformers "attention is all you need".
3. GPT-1 for gradual understanding.
4. GPT-2 and removal of fine tunning.
5. Distillation
6. Some general uses
1. Generative pre-trained language model :
First of all we should know the meaning of our model name. So, what is distilled GPT2 stand for?, and what is this meaning.
distilled, we will talk on it latter but GPT2 is Generative
Pre-Training language model version 2.
The language model is simply the model that predict the next token from given tokens like the prediction that appear to us when using google search or even youtube search. this is language model, what about generative.
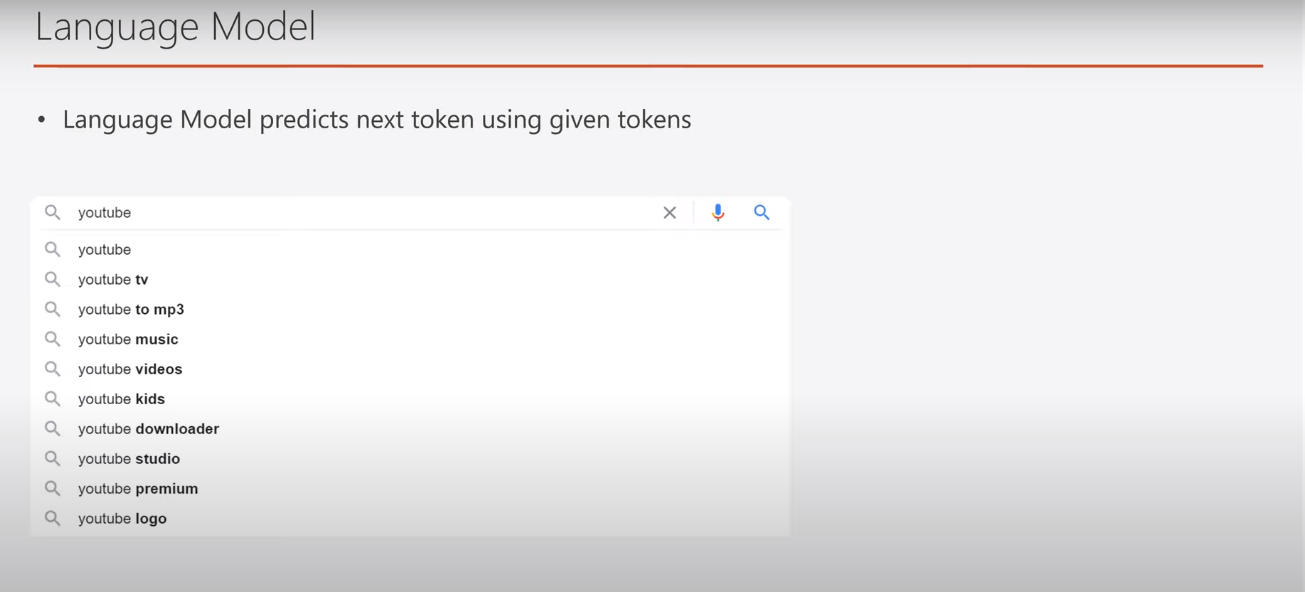
Generative models are the model that don't need human labeling that is expensive and time consuming, generative language model just predicting tokens from previous ones so it can easily labeling without human intervention ( in contrast to discriminative model which need human labeling ). and there are 3 versions of this model till now and we will talk about version 2 .

2. Transformers "attention is all you need" :
In order to understand transformers, we should revise quickly on how was the traditional way in dealing with NPL tasks.
RNN with attention in encoder and decoder architecture was the trend before transformers as shown here in this translation task. 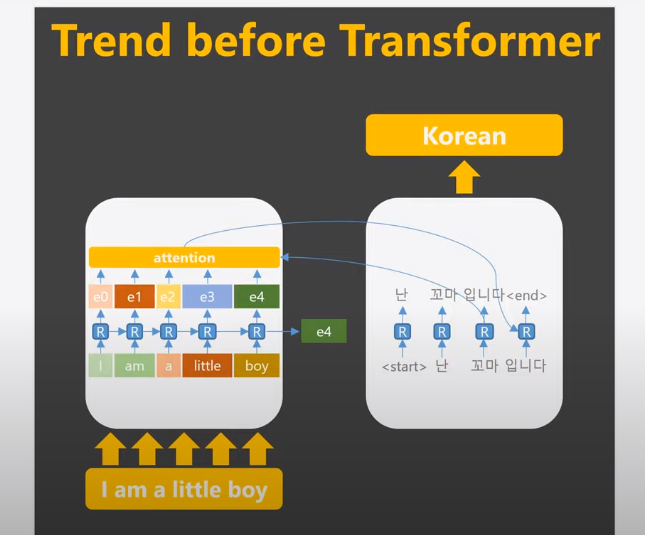
it is clear that every English word enter the encoder in sequence and then the outputs of each RNN cells and the last output of the decoder enter an attention layer which give each word a weight then the output will be the input of RNN cell in the decoder to output the translation.
Here is another example.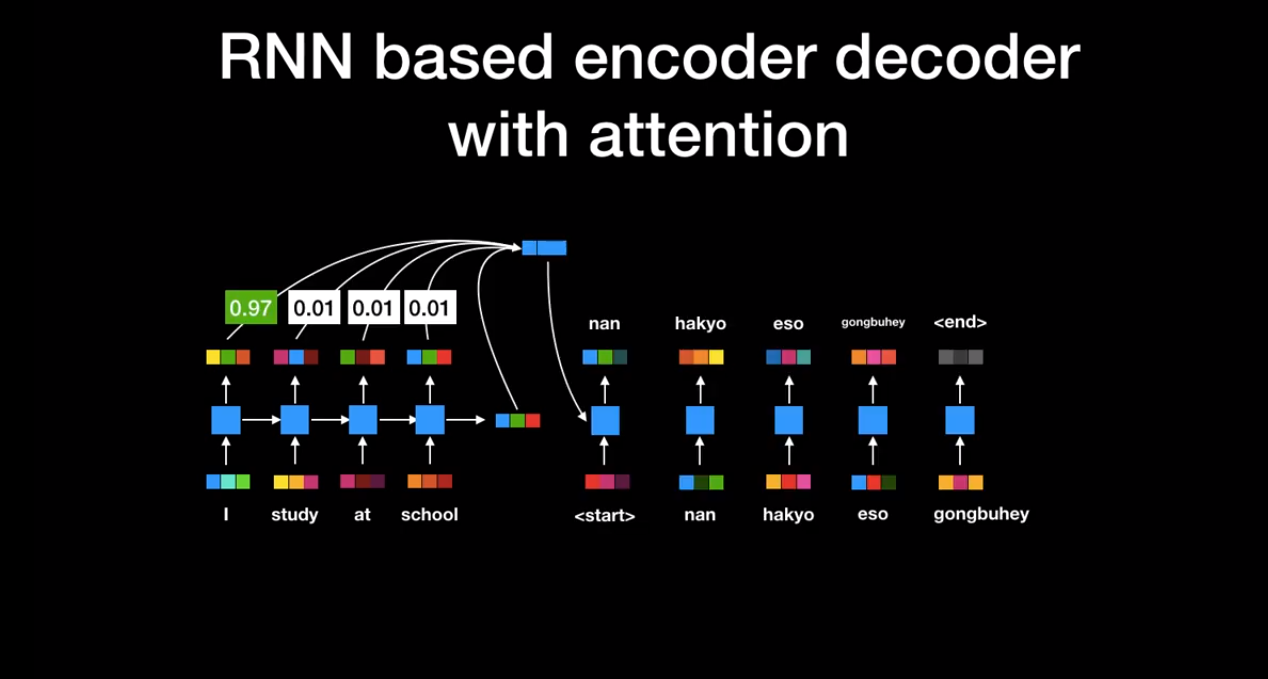
Then a paper called "Attention is all you need" come to make a revolution in this field, the paper said that we really don't need this time and computation consuming RNN layers "we only need attention" So, we can delete that layer but remain the same encoder and decoder architecture.
BUT what about the positions the RNN preserve ?! it's easy, we can add positional encoding in both the encoder and the decoder. the new architecture called Transformers we also can benefit from skip connection to avoid gradient vanishing.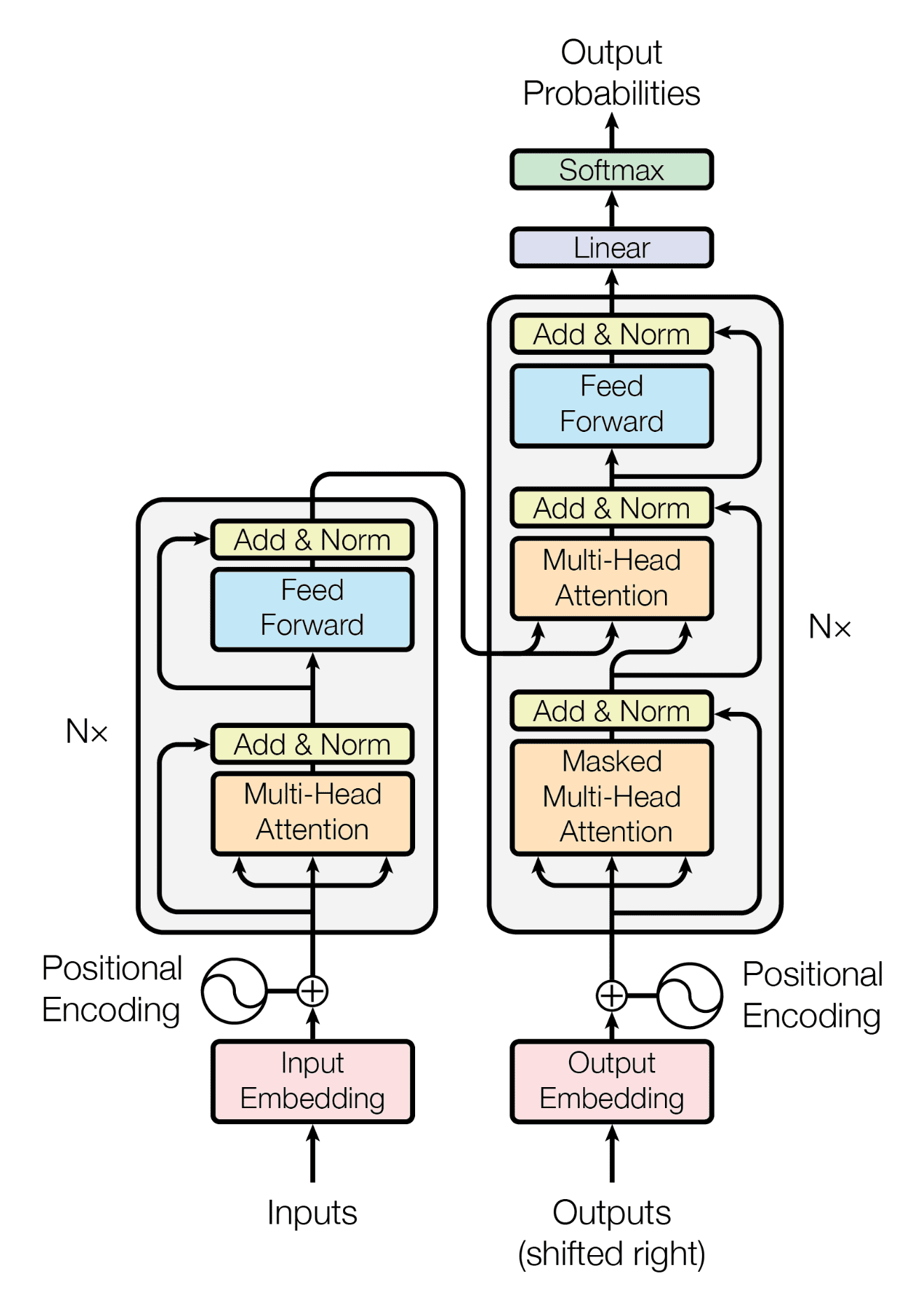
The image shown that we can use multiple encoder blocks and multiple decoder blocks.

this new and revolutionary architecture provide faster and more promising results. but the transformers is just the beginning.
3. GPT-1 for gradual understanding :
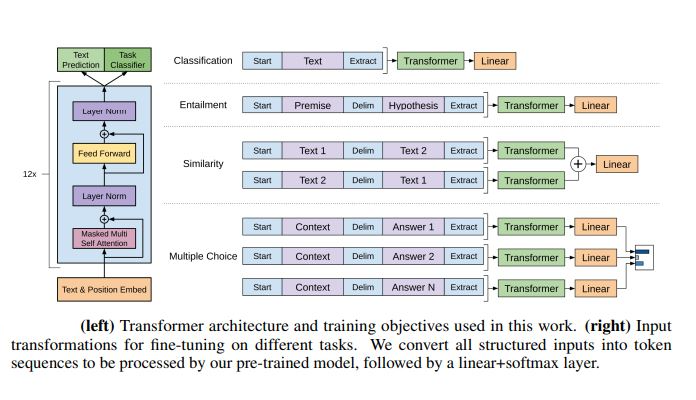
GPT-1 model is transformers based model that consists of only stacked decoder blocks from the standard transformer architecture where the context vector is zero-initialized for the first word embedding. And another difference from the standard transformers that GPT use masked self-attention instead, the decoder is only allowed (via obfuscation masking of the remaining word positions) to collect information from the prior words in the sentence and the word itself. and after training the model then we fine tunning it to the specific nlp task we need.
So, the GPT-1 model consist of 2 steps :
- The pre-training process
- then fine tunning to one of this tasks:
- Natural Language Inference
- Classification
- Question Answering
- Semantic Similarity
4. GPT-2 and removal of fine tunning :
The fine tunning process is time and effort consuming, So it will be great if we can git rid of it and build a model for multiple tasks. But how ? we know that gpt without fine tunning is just a language model.
just introducing the task name with the input and this need largely increase the training data for each task, this what GPT-2 doing 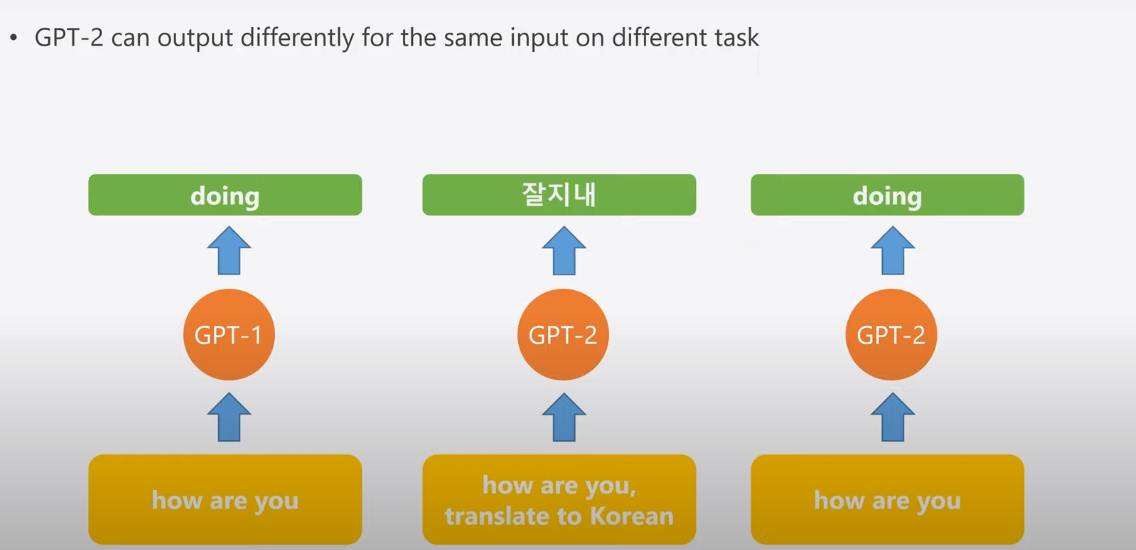
now we don't need the fine tunning process. leading to more effective nlp task solving.
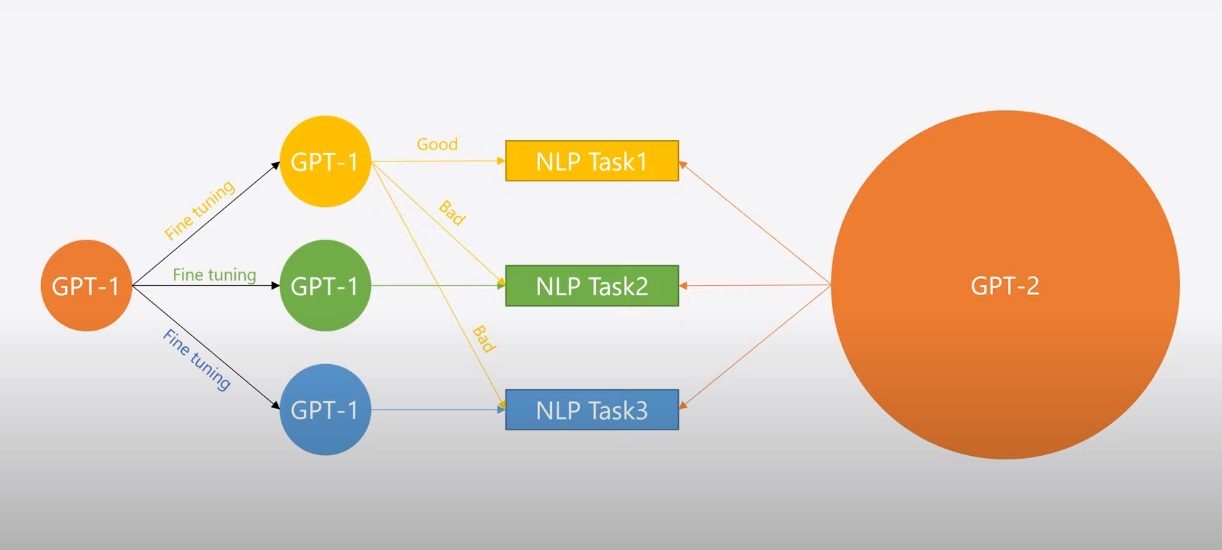
And these are some other differences between the two models.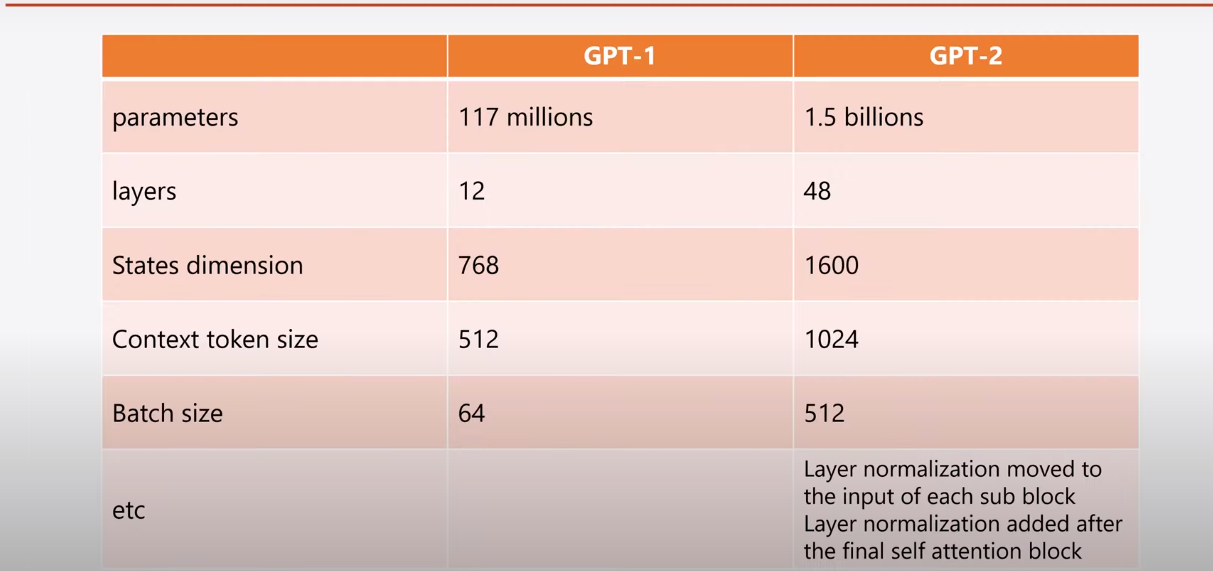
And the results are so promising :
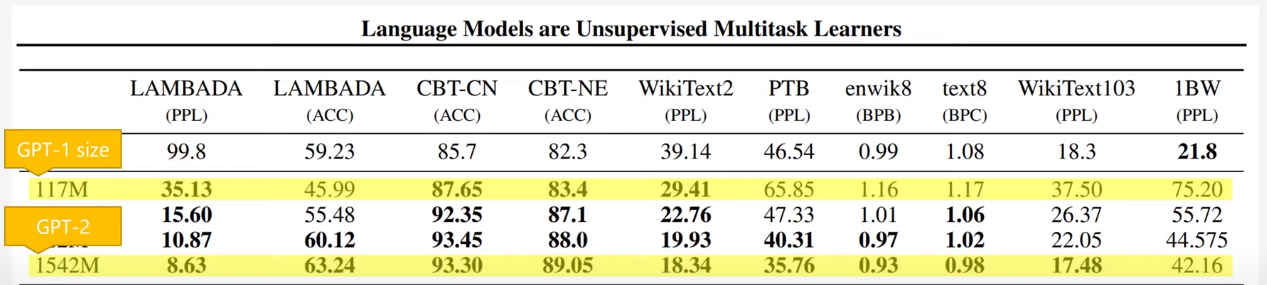
5. Distillation :
And now, what is the meaning of the word "distilled" in the beginning?. Distilled meaning a light version of the model like that we train the basic model to learn its weight then we distill the knowledge to the light version like a teacher and student and of course the base model is the teacher and the distilled version is the student. We would like the smaller network to copy the essential weights learned by the large network. While the base model training objective is to minimize the errors between its prediction and the true label, The distilled training objective is to minimize not only the error against the real label, but also the error against the base model prediction.
While GPT-2 has 1.5 billion parameters and 24 layers, the distilled GPT-2 has only 6 layers and 82 million parameters. The (word) embedding size for the smallest GPT-2 is 768, and distilGPT2 has the same embedding size of 768.
6. Some general uses :
Since Distilled GPT-2 is a light version of GPT-2, it is intended to be used for similar uses with the increased functionality of being smaller and easier to run than the base model. these are the most use cases:
- Text Generation.
- Chatbots which are very trendy nowadays.
- Machine Translation.
And for using it in tensorflow :
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
model = TFGPT2Model.from_pretrained('distilgpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
With this article at OpenGenus, you must have the complete idea of Distilled GPT-2.