
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we have explored the idea of Distributed File System in depth along with the techniques and features of a Distributed File System. We have covered different examples of Distributed File System like Google File System.
Table of contents:
- Introduction to Distributed File System
- Features of Distributed File System
- Characteristics of a Distributed File System
- How does a Distributed File System work?
- Backup in Distributed File System
- Applications of Distributed File System
- Andrew File System
- Sun's Network File System (NFS)
- Google File System
- Hadoop Distributed File System (HDFS)
- Coda
- Advantages of Distributed File System
- Disadvantages of Distributed File System
Introduction to Distributed File System
A distributed file system (DFS) allows users of physically separated systems to exchange data and storage resources through the application of a shared file system. There are various benefits to adopting a well-designed DFS, such as increased file availability since multiple workstations can utilize the servers, and sharing data from a single site is easier than sending copies of files to each clients. Backups and information security are simplified because just the servers must be backed up.
A DFS is often structured as a group of workstations and mainframes linked by a local area network (LAN). A DFS is built into the operating systems of each of the machines that are linked.
A distributed file system (DFS) is distinctive from traditional file systems because it provides direct host accessibility to the same file data from many places. The data underpinning a DFS can, in fact, be in a different place than all of the hosts that consume it.
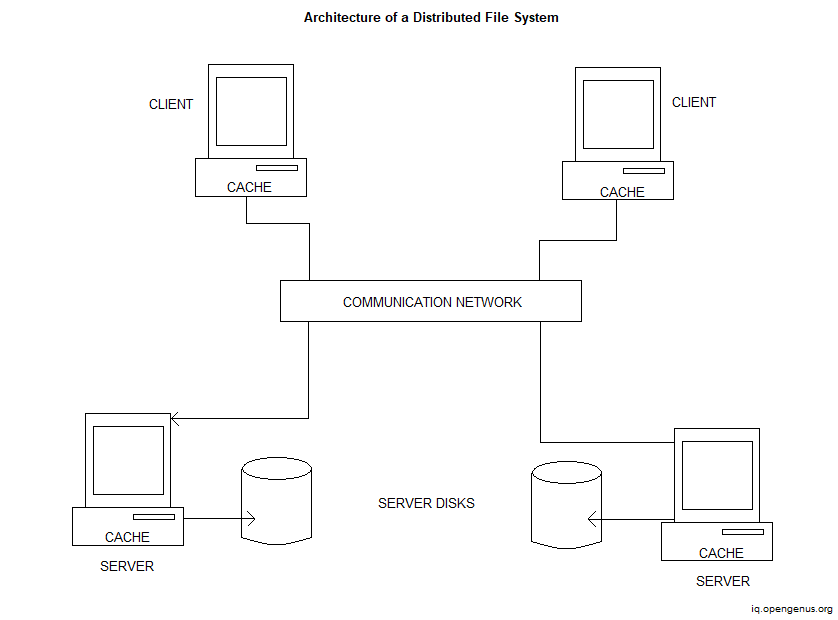
Features of Distributed File System
The Features of Distributed File System are:
- Hosts may not be aware of the physical location of file data. The DFS manages data location, not the host that accesses it.
- From the perspective of the host, the data is accessible as if it were native to the host that is retrieving it.
- Distributed File Systems first appeared to provide maximum performance for HPC applications, and the majority of them still do.
- DFS file data is maintained in such a way that it seems to the host(s) as if it is all contained inside a single file system, despite the fact that its data may be scattered over several memory devices/servers and locations.
- Encrypting data and information in transit is supported by the majority of DFS systems.
- File locking between or within locations is often supported by DFS, ensuring that no two hosts may edit the same file at the exact time.
- All protocols supported by the DFS solution can access the same file.
- While most DFS systems have extremely precise metadata server requirements, their data or file storage can typically sit on almost any storage accessible, including the public cloud.
- DFS systems may necessitate certain server and storage resources at each site where file data is accessed. Local gateways frequently cache information and data that hosts reference. This type of gateway may often be scaled up or down to meet performance needs. Gateways are not required in some circumstances where access and data are co-located.
- While all DFSs offer Ethernet access to file system data, some additionally offer InfiniBand and other high-speed networking options.
- Most DFS systems provide scale-out file systems, which allow the speed and capacity of file data and metadata services to be expanded by adding more information or file data server resources-including gateways.
- Given the foregoing, the vast majority of DFS systems are software defined technologies. Some DFS systems are also available as appliance solutions, however this is more for the convenience of purchase and deployment than a need of the DFS solution.
Characteristics of a Distributed File System
- For enhanced small file performance, certain DFS systems support very high IOPS.
- Several DFS systems can be used in a public cloud. That is, they use a public cloud provider for file storage, metadata services, and any monitor and control services. File data access can thus occur inside the same cloud AZ, between cloud regions, or even on-premises with access to cloud data.
- Some DFS systems enable one protocol to lock a file while another protocol modifies it. This feature prevents a file from being damaged by multi-host access, even when various protocols are used to access the file.
- Various DFS systems offer extremely high availability by dividing and duplicating their control, metadata, and file data storage systems over many locations, AZs, or servers.
- DFS systems allow you to combine many file systems/shares into one name space that you may use to access any file directory offered.
- Some DFS systems include data compression or deduplication, which reduces the amount of physical data storage space required for file data storage.
- DFS systems provide at-rest encryption of file data and metadata.
- Certain DFS systems include the ability to limit or restrict the physical places where data may be stored and retrieved. This functionality may be necessary to comply with GDPR and other data-flow limits imposed by law.
How does a Distributed File System work?
Client/server-based applications have revolutionized the process of developing distributed file systems, thanks to the rapid expansion of network-based computing. In both LANs and WANs, sharing storage resources and information is a critical component (WANs). As networks advance, new technologies such as DFS have been created to make sharing resources and information over a network more convenient and efficient.
Offering access control and storage management controls to the client machine in a centralized manner is one of the processes involved in establishing the DFS. The servers involved must be capable of distributing data with adequate dexterity.
In DFS, one of the essential processes is transparency. Files should be read, saved, and controlled on local client workstations, but the process itself should be held on servers. On a client machine, transparency provides ease to the end-user, while the network file system effectively handles all tasks. A DFS is often utilized in a LAN, but it may also be used in a WAN or over the Internet, as well as in new SD-WAN configurations and other creative networking styles and approaches.
In comparison to other solutions, a DFS enables for more efficient and well-managed data and storage sharing over a network. A shared disc file system is another option for users in network-based computing. When a shared disc file system is used, the access control is placed on the client's computers, making the data unavailable when the client is offline. DFS, on the other hand, is fault-tolerant, so data can be accessed even if some network nodes are down.
Backup in Distributed File System
Despite the fact that a DFS server is praised for serving as a single point of access, another server may be involved. That does not rule out the possibility of a single central access point. The backup server will be the second server. Because corporations invest in a single central DFS server, they are concerned that the server may be hacked. Backing up all of the data to a second place guarantees that the system is totally fault-tolerant, even if the primary server is brought down by anything like a DDoS assault or something else.
DFS systems, like all others, are always evolving. Modern DFS will frequently take use of logical partitioning or other developments in hardware and software, thanks to improved networking controls and virtualization technologies.
Applications of Distributed File System
The distributed file system may be used in a variety of ways. The following are a few of them.
- Network File System (NFS) - It is a network-based file storage system. It is a distributed file system that lets users to access files and directories on remote machines and treat them as if they were local files and directories.
- Hadoop - Hadoop is an open-source system for storing and processing large amounts of data in a distributed setting using basic programming concepts across clusters of machines. It's built to expand from a single server to thousands of devices, each with its own computing and storage capabilities.
- NetWare - Novel NetWare was a strong network/file sharing operating system that was released in the early 1990s. It was initially distinctive as it shared individual files rather than full disc volumes, and it supported DOS and CP/M clients. It made advantage of a cooperative tasking server environment and had several sophisticated capabilities that were previously only available in mainframe systems. In May 2009, the last version, 6.5SP8, was published.
- Common Internet File System (CIFS) - The Common Internet File System (CIFS) is a network file system protocol that allows workstations on a network to share files and printers. It is an SMB variant.
- Server Message Block (SMB) - It is a client/server protocol that controls access to files, folders, and other network resources such as printers, routers, and network interfaces. The SMB protocol can manage information sharing between a system's many processes.
Large challenges exist when it comes to developing a suitable distributed file system, such as the fact that sending many files over the internet can easily result in poor performance and delay, network bottlenecks, and server overload. Another major worry is data security. Then there are the issues that arise as a result of failures. Client computers are frequently more dependable than the network that connects them, and network disruptions can render a client inoperable. Likewise, a server failure may be extremely inconvenient since it prevents all clients from obtaining critical data.
We have several robust DFS systems with various architectures and designs as the latest rising technology. They each have their own advantages and disadvantages. In this article, we'll look at the following.
- Andrew File System
- Sun NFS
- Google File System
- Hadoop
- Coda
Although there are numerous factors to consider when evaluating DFS, we will look at it from the following angles. Transparency, user/client mobility, performance, simplicity & ease of use, scalability, availability, dependability, data integrity, security, and heterogeneity are all important characteristics to consider.
Andrew File System
Andrew File System presents a homogenous, location-independent file namespace to all client workstations via a group of trustworthy servers. This was created at Carnegie Mellon University (CMU) as a computer and information system for the university. There are two variants of AFS. The earliest version of AFSv1 (although the original system was named the ITC distributed file system) had part of the core concept in place but didn't scale well, resulting in a re-design and the final version AFSv2, or just AFS.
The basic goal of the AFS is to facilitate large-scale information sharing by reducing client-server communication. It is accomplished by moving complete files across server and client devices and caching them until the servers get a more recent version. It is made up of two software components that run as UNIX processes.
- Vice: The name given to the server software that runs on each server machine as a user-level UNIX process.
- Venus: A user-level process that runs on each client machine and corresponds to our abstract model's client module.
The distribution of processes in AFS is depicted in the diagram below.
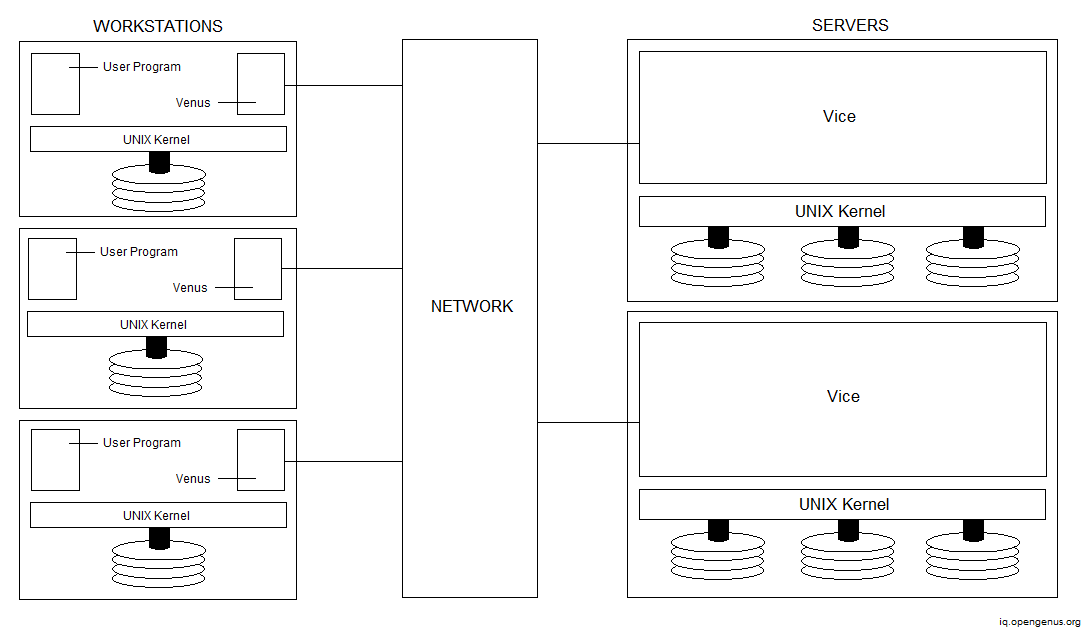
Users can access either local or shared files. Local files are placed on the hard drive of a workstation and are only accessible by local user programs. Shared files are kept on servers, with copies cached on workstations' local discs.
AFS achieves excellent scalability through its designs, allowing it to accommodate nodes in the range of 5000 to 10000. It also includes robust security authentication techniques and a tight access list system for protection. Clients may access any file in the shared namespace from any workstation, giving them a high level of mobility. When accessing files from a workstation different than the normal one, a client may notice some initial speed decrease owing to file caching. However, in the long run, this improves performance.
Another feature worth considering is AFS's operability. A small staff and administrator team may easily manage the AFS system.
Sun’s Network File System
This is one of the most well-known and widely used DFS nowadays. Sun Microsystems was in charge of the project's development. The need to expand a Unix file system to a distributed environment was the driving force behind this project. However, it was later expanded to other operating systems. It features a transparent architecture that allows any computer to operate as both a server and a client, accessing data on other computers.
The protocol architecture of NFS ensures maximum portability. The NFS protocol offers an RPC interface that allows a server to remotely access local files. The protocol makes no recommendations for how the server should enforce this protocol, nor does it require how the client should utilize it.
The Procedure Call (RPC) paradigm for communication in NFS is shown below.
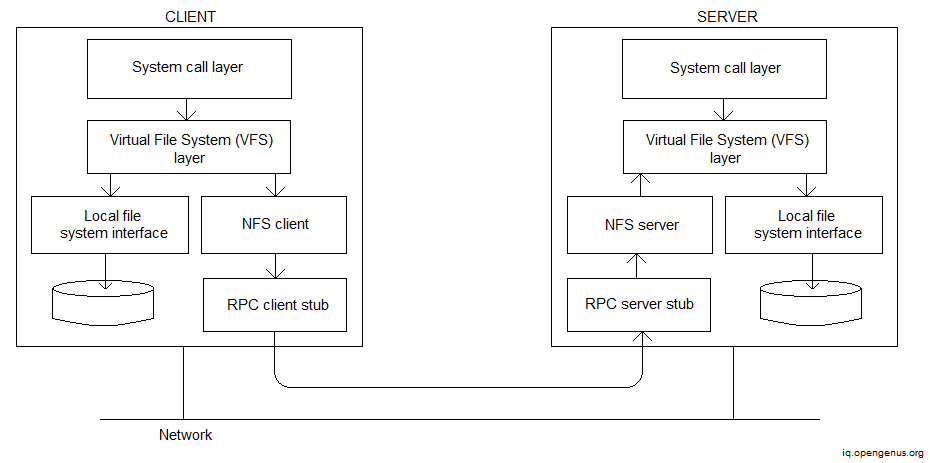
The distributed implementation of the old Unix file system is the NFS's underlying architectural structure. It includes a virtual file system that acts as a middle layer. This allows customers to operate with a variety of file systems with ease. Between calls and file system calls, the operating system is an interfaced call. We can transmit several commands from an RPC in the current versions of the NFS.
NFS offers a high level of transparency since users can't see the difference between local and network files. The fault tolerance of NFS is very high. It is kept track of the status of files. The server gets alerted in the event of a client-generated error. On NFS, there is no file replication. The whole system, however, is duplicated. Files are cached, and the cached copy is compared to the server copy. The file is modified and the cache is deleted if the times are different. NFS is stateless at the same time, and every client requests must be self-contained, which contributes to the quick crash recovery.
Because the files are not duplicated, NFS does not employ a synchronization technique. Validation tests are used to preserve consistency. When a file is accessed or the server is contacted to resolve a cache miss, a validation check is always conducted. Cached blocks are presumed to be valid for a finite period of time after a check, as defined by the client when a remote file system is mounted. After this period, the first reference to any block in the file requires a validity check.
In terms of security, NFS verifies access using the core Unix file safety mechanism on servers. Each RPC call from a client includes the identification of the person who is making the request. It is made up of Individual files and directories are protected using the normal Unix protection method, which includes user, group, and world mode bits. Users cannot achieve great mobility since file relocation is not feasible; nevertheless, file system relocation is possible but needs client configuration adjustments.
Google File System
For big distributed data-intensive applications, Google File System is a scalable distributed file system. It's a Google-developed DFS that's exclusive for Google's usage. It's meant to give fast, dependable data access utilizing massive clusters of commodity technology. Because it's designed to function on computing clusters with nodes made up of low-cost, "commodity" machines, it's important to take measures against individual node failures and data loss.
The GFS design is as follows.
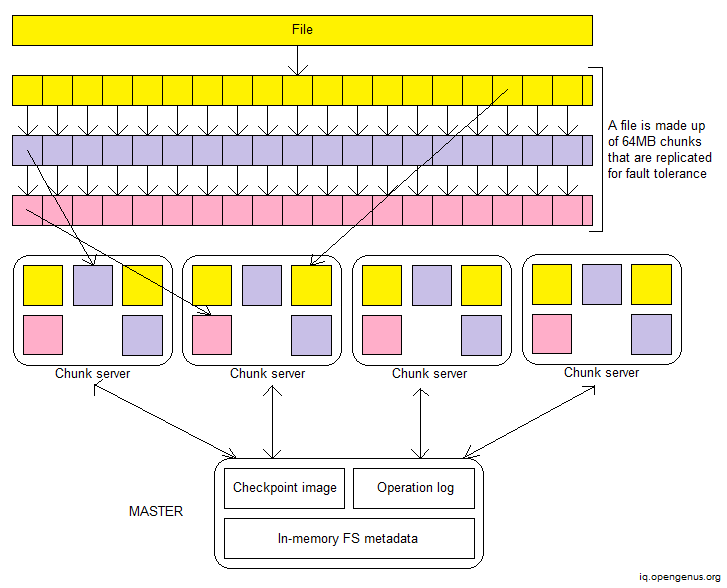
GFS files are large by typical standards, and they are broken into 64-megabyte pieces. Rather of overwriting old data, most files are altered by adding new data. The files are only read after they've been written, and they're usually read in order.
As previously stated, the system must cope with component failures on a regular basis. File metadata, such as directory contents or access control information, determines the quality and staleness of data within brief intervals. A shadow master keeps itself updated by reading a copy of the increasing operation log and applying the same sequence of changes to its data structures as the main. It polls chunk servers at launch (and seldom thereafter) to discover chunk replicas and sends periodic handshake messages to monitor their status, much like the primary. It solely relies on the primary master for replica location changes as a result of the primary's replica creation and deletion choices.
In terms of data integrity, GFS utilizes checksums, and each chunk server uses checksumming to identify data corruption. Because a GFS cluster might include thousands of discs on hundreds of servers, disc failures are common, resulting in data distortion or loss on both the read and write channels.
GFS has a high availability because it employs two successful strategies: quick recovery and replication. Regardless of how they terminate, both the master and the chunk server are engineered to re-store their information and relaunch in seconds. Each chunk is duplicated on numerous chunk servers distributed across many racks. For consistency, the master state is copied. Its checkpoints and operation log are copied across numerous devices.
In terms of security, GFS relies on trust between all nodes and clients and does not use any specialized security mechanisms in its design. However, we may be used in conjunction with other identity providers to offer authentication.
Hadoop Distributed File System (HDFS)
Hadoop is a well-known distributed file system (DFS) with great fault tolerance. It's based on Google's File System and is intended to store very big files consistently across several machines in a huge cluster. Hadoop employs the MapReduce architecture and the high-level Java programming language. HDFS is also built to deliver high-bandwidth data cluster streaming to clients. It's frequently employed in Big data analytics such as Hadoop Mapreduce and Spark because of its dependability and effectiveness. Many significant businesses now use Hadoop. In the industrial and academic worlds, it is commonly used. Twitter, LinkedIn, eBay, AOL, Alibaba, Yahoo, Facebook, Adobe, and IBM are just a few examples of corporations that use Hadoop.
The Hadoop Distributed File System architecture is shown below.
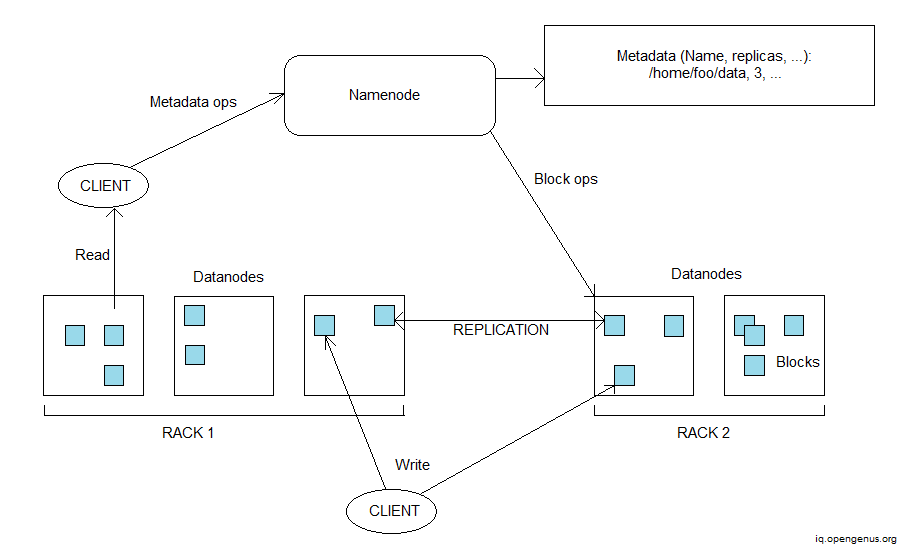
Each file is stored in Hadoop DFS as a series of blocks, with all blocks in a file, save the final, being the same size. A file's blocks are copied to ensure fault tolerance. Per file, the block size and replication factor may be customized. Files are "write once" and only one writer is active at any given moment. If a failure occurs, the copy on another node is replicated once more. This ensures the data's safety. This also contributes to the system's data integrity.
Hadoop may be configured in two modes: secure and non-secure. The key distinction is that safe mode necessitates user and service authentication. In Hadoop secure mode, Kerberos is used for authentication. As part of the verification procedure, data is encrypted. We may also configure file permissions for certain data types and files by individual, group, and role. Data masking can be used to limit the amount of data that can be accessed.
Hadoop can scale to hundreds of nodes in a group and handle petabyte-scale data. HDFS was created with the goal of being easily transferable from one environment to the next. This makes it easier for HDFS to become the platform of choice for a wide range of applications. Hadoop is more commonly utilized for batch processing than for direct user access. The replication factor of the system can be used to determine the system's performance. Although large replication factors increase system dependability, they have a positive impact on system performance.
It simplifies coherency and data integrity by using the "Write-once-read-many" technique. Checksums can also be used to ensure data integrity. When an user creates an HDFS file, it evaluates a checksum of each block of the file and stores these checksums in a distinct hidden file in the same HDFS namespace. When a client receives file contents, it ensures that the data it obtained from each DataNode matches the checksum recorded in the checksum file linked with that DataNode. If that is not the case, the client might choose to obtain the block from another DataNode that contains a copy of it.
Coda
Coda is developed by the systems group of M. Satyanarayanan in the SCS department at Carnegie Mellon University since 1987. It's based on the Andrew file system.
The following are some of the CODA's most prominent features.
- Client-side persistent caching provides high speed.
- Replication of servers.
- The authentication, encryption, and access control security paradigm.
- Continuation of operations in the event of a partial network failure in the server network
- Scalability is excellent.
- Even in the event of network failures, the semantics of sharing are well specified.
- Improved availability, because all servers may get updates, resulting in greater availability in the case of network partitions.
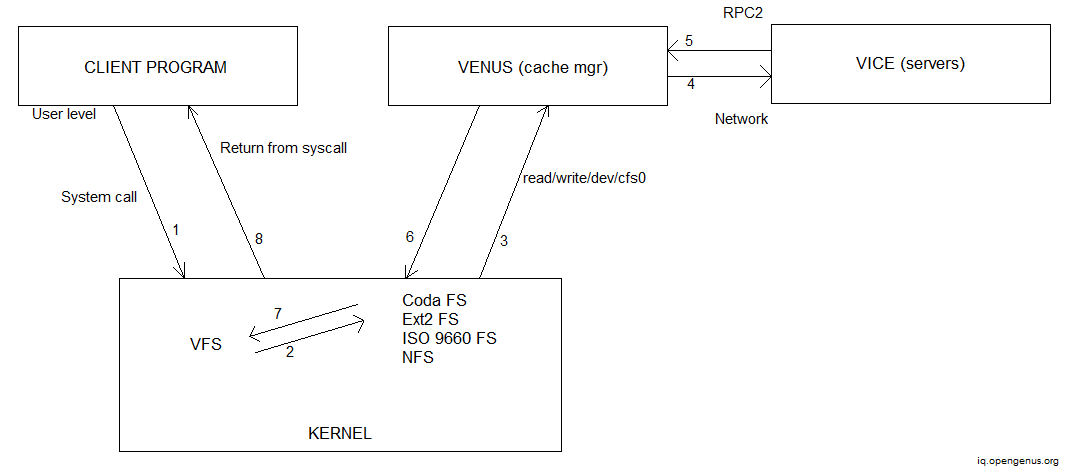
The figure below demonstrates the operation of the coda file system.
Advantages of Distributed File System
-
DFS has a significant benefit in terms of dependability and uptime due to data redundancy, which means that the same information is kept on many nodes. It improves access speed while while ensuring great fault tolerance. If anything goes down with one node, the identical data may be quickly accessed from the others. And the possibility of all nodes experiencing outage at the same moment is close to none.
-
Following on from the preceding point, distributed systems are ideal for server maintenance since you can ensure that all components are up to date and execute system updates without disrupting work. Even if a reboot is necessary to apply the changes, you can do it gradually by loading data from a separate node.
-
With DFS, your employees will be able to access business data from many places at the same time. Aside from access, your staff will be able to upload, download, and share files, allowing many individuals to work on the same project at the same time. Even if the entire team is working remotely, it reduces document handling time and increases productivity.
Disadvantages of Distributed File System
-
Because data is kept on several physical computers and locations, more expenditures are required for storage security, file transfer protocols, and storage connectivity, as a breach can occur at any of these steps. Otherwise, using system weaknesses, sensitive data leakage might occur, revealing information on the internet. That is why access must be restricted via an internal VPN connection, with multiple security layers added to ensure that the data stays unavailable outside the firm.
-
If the team is working with large amounts of data, the reading performance may be slower depending on the nature of the data and the physical system capacity, since connections, arriving and outgoing server requests take a lot of CPU and RAM resources. This is especially true for earlier generation SBM servers, which are still prevalent due to cost considerations. The solution is to use dependable infrastructure, both in terms of network and hardware.
-
Managing distributed system is a more difficult procedure than managing centralized system. As an example, consider database connection and administration in the context of problem resolution. When data is imported from several sources, it may be difficult to identify a defective node and perform effective system diagnostics. As a result, if you choose distributed systems, you must assemble a team of highly qualified engineers. Even if you have one, the time it takes to handle problems may be greater owing to the system's nature.
Conclusion
DFS systems provide worldwide access to the same data, which is extremely difficult to achieve successfully in any other method, especially when numerous locations are computing with and consuming the same information. Without breaking a sweat, DFS systems can make all of this appear effortless and smooth. So, if you have numerous sites that require access to the same data, a DFS system can be a lifesaver.
DFS has a greater reach, and we may analyse them from a variety of perspectives. Nowadays, we can find more advanced DFS, each with their own set of advantages and disadvantages. Rather than looking for the finest DFS, we should constantly strive to discover the best DFS for our requirements.
With this article at OpenGenus, you must have the complete idea of Distributed File System.