
In this article, we will design an algorithm to Find word with maximum frequency using Trie Data Structure.
Table of contents:
- Problem Statement
- Key Idea of using Trie
- The Fundamentals of Trie
- What operations can be performed on a Trie
- Implementing the Node
- Solution: Implement the insert method
- Time and Space complexity for insertion
- How to implement the startsWith method
- How to implement the searchWord method
Problem Statement
We are given N words and we need to find the word that occurs the maximum number of times in the given set. The challenge is to use Trie Data Structure to find the word with maximum frequency.
Assume there are N strings and the average length of each string is O(M).
Other common ways to find the word with maximum frequency are:
- Sort the set of N words, traverse the sorted list and keep track of the longest sequence of same word. This takes O(N2 logN) time as comparing strings take O(N) time.
- Building on the previous approach if strings are hashed to an integer, then the Time Complexity reduces to O(N logN + N * M) time as each string takes O(M) time to hash.
- Use Hash Map and Hashing to keep track of word with maximum frequency. This will take O(N * M) time complexity and O(N * M) space complexity.
It is not easy to understand how to apply Trie in this problem but once you get the idea, you can use Trie in innovative ways.
Key Idea of using Trie
The key idea of using Trie to find the word with maximum frequency is:
- Add a new attribute count for each Trie Node. This will keep track of the frequency.
- When a new word is inserted, the count is incremented.
- When we want to find the word with maximum frequency, we traverse the Trie to find the node with maximum frequency.
The number of nodes in the Trie at max will be O(N * M). In reality, it will be less than this as the prefix will be common for multiple words. Moreover, a word with T frequency is stored only once so it is space efficient.
If we assume there are P nodes in the Trie, then traversal with take O(P) time.
P <= N * M
To implement this feature, we first need to know how to implement the Trie data structure we first need to know what it is, how it works and why it is used.
The Fundamentals of Trie
A Trie is a tree data structure that is used to efficiently retreive keys within a set, preferrebaly strings.
NOTE: It is also known as digital tree or preffix tree. And one more thing, its pronounced as "Try".
Here is a visual representation of a Trie.
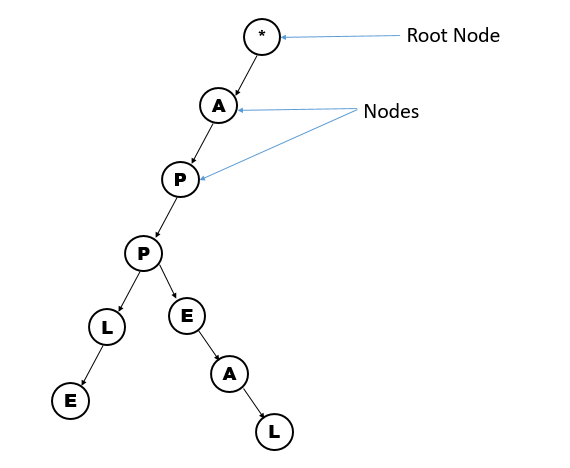
From the image you can see that we have a root node. That is where all the other nodes attach to. So, A Trie is made up of Nodes, each node connects to another node.
Here is a question, How many words can you see from the Trie?
A --> P --> P --> L --> E
--> E --> A --> L
We have 2 words, apple and appeal. Both these words share a common preffix, that is, "APP". As software engineers, data storage and retrieval should be efficient. For 2 words, of course, doesn't seem like it matters, but think of google's autocomplete feature, millions and millions of words. The Trie enables us to re-use preffixes, if words share a common preffix, why do we need to repeat the whole thing by storing both "APPLE" and "APPEAL" while we could store "APP" and build all the words that share that preffix by just connecting the letters are nodes to them.
What operations can be performed on a Trie
There are many operations depending on what features you want your implementation to have. But there are others which are essential and common. These include:
- insert. To insert a word.
- searchWord. Returns True if the word exists in the Trie.
- startsWith. Returns True if there is a word that contains that preffix.
NOTE: It does not matter what you call the above methods. Although it is good practice to use understandable names.
Implementing the Node
Remember a Trie is made up of nodes, and each node has connects to another node (feels like a linked list). The top most node, is the root node, any other node that connects directly to it is a child of the root node or a descendant. so the nodes have a parent-child relationship. The last node has no children and it denotes the end of the word, we can either leave it like that or mark it. How? by setting an attribute, say we call it isEndOfWord to True. By default this is False. The other attribute is children. We'll talk about it, after we look at the code.
class TrieNode:
def __init__(self):
self.children = {}
self.isEndOfWord = False
self.count = 0
if self.isEndOfWord:
self.count = 1
def increment_count(self):
self.count += 1
The children attribute will hold store the Node's children in key-value pairs, we'll see why when we get to imeplementing the insert method. Our TrieNode has 2 other attributes essential to what we want to achieve, the isEndOfWord attribute which marks if the node is the node (or letter) that marks the end of a word and also a count attribute whose is 0 for all nodes except for the end node where it becomes 1. This is because the end node signifies a complete word, and since we are trying to keep track of the frequency (count), then the first complete word to be inserted, will have a count of 1. The increment_count() method simply increments count by 1 (also essential to our main focus).
Now we have a TrieNode, but this is just a simple node, elements that make up the actually Trie Data Structure. Now lets implement the actually thing.
I'll write the code out first, then we can discuss it.
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
pass
def startsWith(self, preffix):
pass
def searchWord(self, word):
pass
This is the skeleton of the structure.
When we first create an instance of a Trie, it should only contain the root node. Thus we create an instance of a node in the initializer and assign it to self.root.
With this, we can create a new Trie like so...
trie = Trie()
Okay, so now we can create a node, but its empty and we need a way to store strings (words).
Solution: Implement the insert method
I'll write out the code first then explain.
def insert(self, word):
currentNode = self.root
for char in word:
if char not in currentNode.children:
currentNode.children[char] = TrieNode()
currentNode = currentNode.children[char]
currentNode.isEndOfWord = True
if currentNode.isEndOfWord:
currentNode.increment_count()
return currentNode.count
the insert() method takes in word as an argument, this is the word that we want to add to our Trie. As we said and saw, In a Trie, each letter is a Node. And that each letter in a word is a child node of the previous letter in the word, up to the point we have the root.
What does this mean? It means for us to insert a word, we have to loop through each character of the word, starting from the root node, if the character exists as a child of the currentNode, we don't create it (avoid repition, efficient), if it does not exists, we create it and set it as the currentNode, and now we repeat the same process with the currentNode.
Let's do it manually for clarity:
We have an empty Trie and we want to insert the word "apple".
- We set the root node as the currentNode.
- We loop through each letter of the word "apple"
- so, we start at the letter "a"
- we check if the letter "a" exists as a child of the currentNode, which is the root node. Remember when I said I'd explain why we use a dictionary for children attribute. Here it is. When we loop through a dictionary using something like this
d = {'a': 'Node1', 'b': 'Node2', 'c': 'Node3'}
for key in d:
print(key)
This will retreive the keys of the dictionary, thus we get "a, b, c".
So now, by checking if char not in currentNode.children, we are checking if there is any node with the key, in our case, "a".
- We find that a node with the key "a" does not exist...
- we create a new entry for the currentNode's children attribute. To add an item to a dictionary, we just create a key in the dictionary object and assign it a value and thats it. Therefore,
currentNode.children[char] = TrieNode() - Now the rest of the loop just goes on with the same processes for each character
- At the end of the loop, the currentNode will be the last node created, thus, that will be our ending character and we update its
isEndOfWordattribute toTrue.
Now you understand how it works, let's get to the main focus of the article. At this point, you can see that only a single instance of a word can exist in a Trie. Meaning we can't have two same words e.g "apple" on the same Trie. That would be ineficient.
So if we can't have the same word twice in the same Trie, how do we find the frequency of its occurence? Thats where the TrieNode's self.count and self.increment_count() come in. A word is signified by its end character or Node. If we try to insert a word that already exists, then the last Node's count attribute is incremented by 1. It answers the question, how many times how this word been searched for?. Lets test it.
I have this code below
trie = Trie()
words = ['apple', 'mango', 'banana', 'apple', 'apple', 'buns', 'mango', 'banana', 'mango']
for word in words:
print(f'the word {word} appears {trie.insert(word)} times')
Summary
- Set the root node as the current node.
- Traverse through each character in the word to be inserted.
- If the character exists as a child node of the current node, then set that node as the current node.
- If the character does not exist as a child node of the current node, then create a new child node (of the current node) using the character.
- Set the current node as the newly created child node.
- Repeat the process until the end of the last character in the word.
- After the loop, set the current node's
isEndOfWordattribute to True, to signify it as the end of a word. - Call the current node's
increment_count()method to increment it's search frequency by 1.
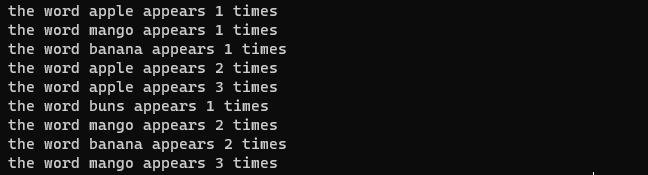
From the output, you can see that for the first time "apple" (and every other word) appears once, but when you try to insert it again, the count increments.
That's it for our frequency feature.
Time and Space complexity for insertion
As for insertion, we have to traverse through each character in the word we are inserting, thus traversing through each node from the root node. Since the word to be inserted is the input, then its time complexity is denoted by O(n), where n = the size of the input (in this case, size of the word).
Space complexity for insertion is also O(n) where n = length of the word (since n new nodes are added).
Now we are already done with our main objective for this article, but feel free to read on to understand more about Trie.
How to implement the startsWith method
def startsWith(self, preffix):
currentNode = self.root
for char in preffix:
if char not in currentNode.children:
return False
currentNode = currentNode.children[char]
return True
For this method, we have similar steps to the insert method except that we are not inserting anything in the Trie.
We are simply looping over each character in the preffix and if the character is a child of the currentNode (starting from root node), we set its node to the current node and move to the check the next one, If its not a child of the currentNode, we return False, since if one letter of the preffix isn't there, we return False.
Summary
- Like the insert method, we start by traversing the preffix passed as a parameter
- As we traverse each character, we start at the root node and check if the character exists as a child node of the current node.
- if not, then we return False as it means the whole preffix does not exist (thus no word with that preffix also exists).
- if the character exists as a child node of the current node, then we set that child node as the current node and we continue to traverse.
- If we traverse the whole preffix without returning False, we return True
Time Complexity for startsWith method
Just as before, we have to traverse through every node (as we are traversing through each character), thus its time complexity is denoted by O(n).
How to implement the searchWord method
def searchWord(self, word):
currentNode = self.root
for char in word:
if char not in currentNode.children:
return False
currentNode = currentNode.children[char]
return currentNode.isEndOfWord
What's the difference between a preffix and a word?
A word has an ending character while a preffix does not. That is, the attribute isEndOfWord of the last character in a word is set to True, while for a preffix its not.
In this method, we simply repeat what we did for startsWith method, except at the end of the loop (where the currentNode will be the last character in the word) we return the currentNode.isEndOfWord where if its True, the word exists in the Trie and if False, the word doesn't exists.
Time complexity of the searchWord method
Its time complexity is denoted as O(n) as we have to traverse through each node (by traversing through the whole word).
Thank you for making it to the end, hope you enjoyed this article. In case you did not understand Time and Space complexity, i'd advice to read more about BigO notation.