
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Key Takeaways:
- Quantum and Thermal Limits: As transistors shrink, quantum effects and thermal constraints pose challenges to CPU and GPU efficiency.
- Transistor Scaling Issues: Transistors under 5 nm face increased leakage and unpredictable behavior, which limits reliability.
- Thermal Management: Increasing power and heat generation requires advanced cooling systems as traditional methods are no longer sufficient.
- Heat Dissipation Limits: Materials like copper and carbon nanotubes have limits, and exceeding 125°C risks device failure.
- Emerging Technologies: Chiplet designs, TPUs, and advanced memory are among the innovations shaping future architectures.
- Heterogeneous Computing: Combining CPUs and GPUs boosts performance but needs specialized optimization.
- Future Innovations: Quantum and neuromorphic computing offer new possibilities but remain experimental.
Table of Contents
- Introduction
- Overview of CPU and GPU
- Fundamental Physical Limits
- Quantum Mechanics
- Thermal Dynamics
- Speed of Light
- Transistor Scaling and Moore's Law
- Architectural Limits
- Parallelism
- Memory and Data Transfer Limits
- Von Neumann Bottleneck
- Power and Energy Efficiency Limits
- Computational Limits
- Algorithmic Complexity
- Floating-Point Precision
- Emerging Technologies and Future
- Conclusion
Introduction
Central processing units (CPUs) and graphics processing units (GPUs) are fundamental components of modern computer systems, each fulfilling different but complementary roles. Their different architectures and functionalities meet different computing needs and reflect the evolution of computing technology from simple processing tasks to the complex calculations required in today's data-driven society.
The CPU, often referred to as the "brain" of a computer, performs arithmetic, logic, control, and input/output operations to execute program instructions. The introduction of the Electronic Numerical Integrator and Computer (ENIAC) in the 1940s laid the groundwork for the concept of a central processing unit.
In 1971, Intel revolutionized computing with the first microprocessor, the Intel 4004, which combined all CPU functions on a single chip. This innovation had a significant impact on the development of smaller, more efficient computers. Over the decades, advances in semiconductor technology have led to the development of increasingly powerful CPUs with higher clock speeds and multi-core designs. In the late 1990s and early 2000s, companies such as Intel and AMD began producing multi-core processors that could handle multiple threads simultaneously, significantly increasing the performance of personal computers and servers.
Originally designed for graphics rendering, GPUs have also seen significant development. IBM introduced the first dedicated graphics card in 1981, but the GPU market expanded in the late 1990s with NVIDIA's RIVA series, initially focused on accelerating 2D graphics tasks. The early 2000s saw the introduction of programmable shaders, allowing developers to create complex visual effects, further enhancing the gaming experience. As gaming technology evolved, so did the capabilities of GPUs, which became essential for parallel processing due to their ability to manage thousands of threads simultaneously.
Today, GPUs are utilized beyond graphics and gaming, proving invaluable in fields such as big data analytics, artificial intelligence (AI), machine learning (ML), and scientific computing, where they excel at performing large-scale computations.
This article examines some of the known limitations of CPUs and GPUs to provide a balanced understanding of the issues faced by these architectures. This article examines the fundamental and practical limitations of modern central processing units (CPUs) and graphics processing units (GPUs), focusing on key areas such as quantum mechanics, transistor scaling, data transfer, parallelism, and energy efficiency. Given the broad and complex nature of these topics, the writer recognizes that while there are limitations, the capabilities of CPUs and GPUs often outweigh these challenges in practical applications. Due to the inherent complexity of the topic, this article will highlight key known architectural, physical and theoretical limitations while recognizing that new innovations continue to push the boundaries of what is possible. The scope is intentionally broad, covering established limitations. However, it is limited by the time and scope of this study and provides a general overview rather than comprehensive technical details. This article is intended as a general exploration of the topic rather than a comprehensive or groundbreaking analysis. It should serve as a useful resource for those interested in learning more about the trade-offs between CPUs and GPUs.
Overview of CPU and GPU
Central Processing Units (CPUs)
A CPU's design determines how it processes instructions, manages data, and communicates with other parts of the computer system. The main components of a CPU include:
Control Unit (CU)
The CU coordinates data movement within the CPU and between the CPU and other system components. It retrieves instructions from memory using the program counter (PC), translates these instructions into signals for other CPU components, and processes timing signals to synchronize operations throughout the system.
Arithmetic Logic Unit (ALU)
The ALU performs all mathematical operations (addition, subtraction, multiplication, division) and logical operations (AND, OR, NOT, XOR). It processes input from registers or memory and returns results for further use.
Registers
Registers are small, fast memory locations within the CPU that temporarily store data and instructions currently being processed. General-purpose registers perform various functions during execution, while special-purpose registers like the program counter (PC) and instruction register (IR) manage specific tasks.
Instruction Set Architecture (ISA)
The ISA defines the instructions that a CPU can execute and serves as an interface between software and hardware. It can be broadly divided into Complex Instruction Set Computing (CISC), which provides a large set of instructions for complex tasks, and Reduced Instruction Set Computing (RISC), which focuses on a smaller set of simpler instructions designed for faster execution are.
Microarchitecture
Microarchitecture describes how a processor implements its ISA and influences how efficiently a CPU can process data and execute instructions.
Pipelining
Pipelining enhances CPU instruction throughput by overlapping the execution of multiple instructions, breaking down the execution process into stages (fetching, decoding, execution, memory access, and writing back). A deeper pipeline allows for more simultaneous instruction processing but introduces potential issues like data and control hazards.
Superscalar Architecture
Superscalar processors leverage instruction level parallelism (ILP) by dynamically scheduling instructions based on dependencies and execution unit availability. This architecture allows multiple instructions to be issued and executed simultaneously in one clock cycle.
Cache Memory
Cache memory provides the processor with quick access to frequently used information and instructions. It consists of:
- L1 Cache: The smallest and fastest, located closest to the CPU cores, often split into separate caches for data (L1d) and instructions (L1i).
- L2 Cache: Larger and slower than L1, serving as a secondary cache for both data and instructions.
- L3 Cache: Even larger and slower, shared among all cores in multi-core processors, with higher latency compared to L1 and L2.
Bus Architecture
The bus architecture defines how data is transferred between components by connecting the CPU to memory and input/output devices. Modern CPUs often have multiple cores, allowing instructions to be executed in parallel. Technologies like Intel's Hyper-Threading allow each core to process two threads simultaneously.
Performance Metrics
Clock speed (measured in hertz, Hz) indicates the number of cycles a CPU can execute per second, typically expressed in gigahertz (GHz). IPC (Instructions Per Cycle) measures how many instructions a CPU can process in one clock cycle, while CPI (Cycles Per Instruction), the inverse of IPC, indicates the average number of clock cycles needed to execute a single instruction.
Graphics Processing Units (GPUs)
Graphics Processing Units (GPUs) are specialized hardware components designed to enhance the rendering of images and videos. Unlike CPUs, which are optimized for sequential task handling, GPUs are built for parallel processing, enabling them to perform many operations simultaneously.
Originally based on fixed-function graphics pipelines, GPUs have evolved into programmable parallel processors capable of handling complex 3D graphics. Modern GPUs, such as those from NVIDIA, can contain over 200 billion transistors, with ample room for further advancements. Today, GPUs are not limited to graphics; they also support general-purpose computing through NVIDIA’s CUDA programming model.
Execution Model
GPUs utilize a Single Instruction Multiple Threads (SIMT) execution model, allowing multiple threads to execute the same instruction across different data sets. This architecture features hundreds or thousands of smaller cores designed for simultaneous operations, enabling efficient parallel processing.
Memory Architecture
The memory architecture of GPUs differs significantly from that of CPUs and includes several layers:
- Global Memory: The largest but slowest memory available on a GPU.
- Shared Memory: A faster, smaller memory shared by threads within a block.
- Registers: The fastest memory, used by individual threads.
Thread Management
GPUs manage thousands of threads simultaneously using structures called “warps” or “wavefronts,” depending on the architecture. Warps consist of groups of threads that execute synchronously, reducing latency caused by memory access delays. Streaming multiprocessors (SMs) process multiple warps, allowing continued processing even if a warp is delayed by a long-latency operation.
Performance Innovations
Modern GPUs use a pipeline structure optimized for graphics tasks. Each SM contains multiple CUDA cores (in NVIDIA GPUs) or stream processors (in AMD GPUs), along with shared memory and registers. The number of CUDA cores per SM varies by architecture, such as Turing or Ampere.
NVIDIA introduced Tensor Cores with its Volta architecture, designed for accelerating matrix operations. Additionally, Ray Tracing Cores were introduced in the Turing architecture, enabling realistic lighting effects through ray tracing. The Turing architecture revolutionized GPU capabilities by integrating RT (Ray Tracing) and Tensor cores, while the Ampere architecture has further improved these cores and GDDR6 memory, significantly enhancing the performance of both rasterization and ray tracing techniques. The Ada architecture has seen performance increases of 2x to 4x compared to Ampere, with up to 4x gains through DLSS 3 technology. The AD102 is the flagship GPU in this lineup, powering the RTX 6000 Ada generation, which is the first professional GPU to utilize this advanced architecture.
While CPUs and GPUs excel in their respective fields due to these architectural designs, they also introduce certain limitations that may affect efficiency and performance. This overview provides a foundation for understanding the complex landscape of GPU technology and sets the stage for discussing their limitations in the following sections.
Fundamental Physical Limits
Quantum Mechanics
The scaling of transistors in modern CPUs and GPUs is greatly influenced by the concepts of quantum mechanics, specifically quantum tunneling and Heisenberg's uncertainty principle. These quantum effects become more significant as the semiconductor industry moves toward smaller transistor sizes, usually below 5 nm, presenting both opportunities and inherent challenges for improving the efficiency and performance of devices.
Quantum tunneling, in which particles bypass potential barriers that classical physics would consider insurmountable, plays a complex role in transistor technology. In traditional metal-oxide-semiconductor field-effect transistors (MOSFETs) and fin field-effect transistors (FinFETs), quantum tunneling results in leakage currents that fundamentally affect device performance and yield. As transistors become smaller, the probability of tunneling increases, leading to higher OFF-state currents and reduced operating efficiency (Donnelly et al., 2023; Barla et al., 2021).
Transistor scaling is also subject to fundamental limitations imposed by the Heisenberg uncertainty principle. As transistor dimensions approach atomic scales, the uncertainty in the position and momentum of electrons becomes more pronounced, leading to unpredictable behavior that complicates device design (Haug, 2018; Morello et al., 2010). This principle indicates that precisely controlling electron states at extremely small scales is increasingly difficult, which impacts the reliable operation of transistors.
Thermal Dynamics
CPUs and GPUs rely on semiconductor technology to convert electrical energy into computing power, a process that inherently generates heat due to resistance losses in the materials used. The heat generated can be calculated using the formula:
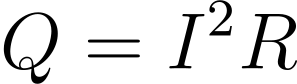
Where Q is the heat generated, I is the current flowing through the device and R is the resistance. As clock speeds increase and transistors shrink in line with Moore’s Law, both power consumption and heat generation rise.
One of the main inherent challenges in heat management is the unequal distribution of thermal energy in multicore processors. As performance demands increase, chips are expected to emit more than 300W of power, while localized hot spots generate more than 150W/cm² of heat flux (Wu et al., 2013).
A key limiting factor arises from the thermal properties of the materials used in CPU and GPU manufacturing. Thermal conductivity directly affects the efficiency of heat dissipation. While materials such as copper and aluminum have traditionally been used, advanced materials such as carbon nanotubes (CNTs) offer significantly higher thermal conductivity, reaching around 2000 W/mK (Grablander et al., 2022). However, even with these materials, the heat generated by high-performance processors often exceeds the capabilities of current cooling systems.
Although more advanced methods have been proposed, traditional heat dissipation mechanisms share common characteristics. Heat dissipation is the process of efficiently dissipating excess thermal energy from system components. Several mechanisms contribute to this: conduction, in which heat is transferred through solid materials such as metal heatsinks that absorb heat from the CPU or GPU; convection, which involves heat transfer through the movement of air or liquid around components, enhanced by fans or liquid cooling systems; and radiation, which plays a smaller but notable role at high temperatures.
The efficiency with which CPUs and GPUs maintain ideal operating temperatures is directly impacted by the efficacy of these mechanisms. While traditional air cooling methods have served well for years, they are often insufficient in high-density computing environments. To improve heat dissipation, advanced solutions like liquid cooling and phase change materials (PCMs) are being explored (Khlaifin et al., 2023; Shang et al., 2020).
Innovative approaches such as microchannel heat sinks and liquid cooling systems are also proposed to enhance thermal management in multi-core architectures (Jang et al., 2012; Zhang et al., 2013). Despite these advances, there are fundamental limitations imposed by thermodynamics and materials science. The maximum operating temperature for silicon-based semiconductors is generally around 125°C; exceeding this threshold can lead to material degradation and ultimately failure (Khlaifin et al., 2023).
Speed of Light
The speed of light, approximately 299,792 kilometers per second (3.0 × 10^8 m/s), or about 186,282 miles per second in a vacuum, is a fundamental constant that imposes significant constraints on signal transmission in Central Processing Units (CPUs) and Graphics Processing Units (GPUs).
In CPUs and GPUs, signals travel through metal traces (wires) that interconnect different parts of the chip. However, the speed at which these signals move is significantly slower than the speed of light in a vacuum. This delay introduces a fundamental limitation on how quickly data can move within the chip and directly impacting clock frequencies and overall processing speed.
CPUs and GPUs typically operate at gigahertz clock frequencies, which define the number of cycles per second they can execute. These frequencies are inherently limited by signal propagation delays, the time it takes for a signal to traverse the chip. Other factors that contribute to latency include processing delays (the time required for the CPU or GPU to execute an instruction) and queuing delays (the time data waits before being processed).
Although light travels at its maximum speed in a vacuum, it slows down when passing through other media, such as glass or metal. For instance, in fiber optic cables, light moves at about two-thirds of its vacuum speed, approximately 206,856,796 m/s. While this remains extremely fast, the finite speed of signal transmission within chips introduces an unavoidable limit to the speed at which can be processed.
The speed of light, denoted as c, represents the ultimate speed limit for transmitting information and matter. This concept, central to Einstein’s theory of special relativity, asserts that no object with mass can reach or exceed the speed of light in a vacuum (Annamalai, 2023). Photons, having no mass, move at this maximum speed, while all other particles must travel slower.
Although engineers cannot surpass this limit, they continually optimize chip designs to reduce delays in signal propagation and improve overall performance. Innovations such as shortening the distances between components or improving materials are key strategies in minimizing the effects of these inherent delays.
Physicists Lev Levitin and Tommaso Toffoli from Boston University have further demonstrated that a speed limit exists for all computers, confirming that such barriers, much like the speed of light, are absolute and cannot be overcome (Ho, 2023). This natural law, alongside other unchanging principles of the universe, ensures that the speed of light remains an unbreakable constraint for all physical systems, including modern computing devices.
Transistor Scaling and Moore's Law
The semiconductor industry has long been driven by Moore's Law, a prediction made by Gordon Moore in 1965 that the number of transistors on a chip would double approximately every two years, leading to exponential improvements in performance and reductions in cost. For decades, this trend held true, with CPUs and GPUs benefiting from continuous transistor scaling that enhanced performance and energy efficiency.
However, Moore's Law is now facing fundamental physical limits. As transistor sizes shrink to atomic scales, quantum mechanical effects such as quantum tunneling and increased leakage currents pose significant challenges to further scaling. These effects are direct consequences of the small sizes involved; as transistors approach sizes smaller than 5 nanometers, electrons can bypass barriers they would not overcome in larger-scale transistors, leading to unwanted power consumption and heat generation even when the transistor is in an off state. This undermines both performance and energy efficiency.
Additionally, the theoretical lower bound for silicon-based transistors is defined by the atomic size of silicon itself approximately 0.2 nanometers. Transistor sizes smaller than this are not possible with conventional materials due to the inability to reliably control electron behavior at such small scales, imposing an absolute limit on how much smaller silicon transistors can get.
Another limitation arises from thermal dynamics as transistors shrink, the ability to effectively manage heat becomes more challenging. Dark silicon, where large portions of a chip must remain unpowered due to thermal constraints, illustrates that not all transistors can be used simultaneously, further limiting the benefits of higher transistor density.
Given these physical constraints, the semiconductor industry is increasingly turning toward new architectural solutions such as 3D integration and heterogeneous computing to maintain performance gains. These innovations do not bypass the fundamental limits of transistor scaling but aim to extend the usefulness of existing technologies in creative ways.
In summary, while Moore's Law continues to inspire innovation, the physical limits of transistor scaling driven by quantum effects, atomic dimensions, and thermal constraints represent absolute barriers that cannot be overcome simply by increasing transistor density. Future progress will rely more on new materials, architectures, and integration techniques than on further shrinking of traditional silicon transistors.
Architectural Limits
CPUs are designed for general tasks and have high single-threaded performance. However, they encounter limitations in managing large data volumes and parallel processing, which can create bottlenecks in power consumption and data traffic, thereby impacting system efficiency (Ghosh et al., 2021). The typical CPU design with a limited number of powerful cores, struggles to scale effectively for parallel workloads, which is particularly evident in applications like deep learning, where GPUs excel due to their capacity for large-scale parallel computations (Li et al., 2023).
The reliance on a few powerful cores in CPU architecture can lead to inefficiencies in processing parallel workloads, often resulting in underutilization of resources. In contrast, GPUs are built for high-throughput parallel processing but face their own architectural challenges. The Single Instruction, Multiple Threads (SIMT) architecture can become less effective without sufficient data plane parallelism, potentially leaving GPU cores underutilized when workloads do not fully utilize them.
Branch prediction in CPUs aims to improve pipeline efficiency by forecasting the direction of branch instructions. While effective predictions can improve performance, inaccuracies may lead to pipeline stalls and wasted cycles, especially in unpredictable workloads that limit instruction-level parallelism (ILP). GPUs, focusing on throughput, typically operate with fewer branches, allowing for efficient execution of multiple threads in parallel (Luan & Chang, 2016).
Pipeline depth, or the number of stages an instruction traverses, can boost clock speeds but may also introduce latency due to increased complexity in handling hazards. GPUs utilize simpler pipeline structures that prioritize throughput over latency. This design can be less effective for tasks requiring frequent context switching or complex control flows, as GPUs are optimized for numerous lightweight threads rather than deep pipeline management.
Out-of-order execution enables CPUs to optimize performance by executing instructions as resources allow. However, GPUs generally do not leverage this technique to the same extent, instead depending on a high number of lightweight threads to mitigate latency. This approach can lead to resource underutilization for tasks misaligned with the GPU’s execution model (Liang et al., 2015).
While architectural innovations aim to enhance CPU and GPU performance, several fundamental limitations persist. For instance, cache hierarchies in GPUs were developed to address bandwidth constraints but can become bottlenecks during high memory traffic (Dublish et al., 2017). Ongoing advancements continue to explore ways to address these limitations and improve overall architecture.
Parallelism
Gene Amdahl proposed Amdahl's Law in 1967, which outlines the constraints on performance gains when only a portion of a system can be parallelized. It asserts that the non-parallelizable portion of a task limits the overall speedup of a system and applies to both CPUs and GPUs.
Equation:
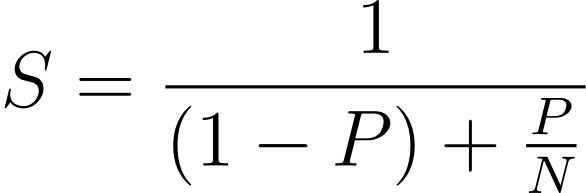
Where:
- S represents the theoretical speedup,
- P is the fraction of the program that can be parallelized,
- N is the number of processors.
The parallelizable part (P) represents the portion of a task that can be executed simultaneously on multiple processors, while the non-parallelizable part (1 – P) specifies the portion that must be executed sequentially, limiting potential speedup. For example, if 80% can be parallelized (P=0.8), even with infinitely fast processors, the maximum speedup would be limited to five times due to the remaining 20% that must be executed sequentially.
For traditional CPU architectures designed for general computing applications, Amdahl's Law indicates that performance improvements from parallelism are inherently limited. Many applications require some degree of serial execution, which prevents full utilization of all available cores or threads. For example, if 90% of a program is parallelizable (P=0.9), the maximum speedup, even with an infinite number of processors, is limited to:
Equation:
S = 1 / ((1 - 0.9) + (0.9 / ∞)) = 10
GPUs can achieve significant speedups in highly parallel tasks like mathematical computations and graphics rendering, for which they are optimized. However, overall performance gains are limited when parallelization is only possible for a small portion of the task, consistent with Amdahl's Law.
Gustafson's Law, on the other hand, offers a perspective that challenges Amdahl's Law by suggesting that, with the addition of more processors, the problem size can be extended to enable more parallel work and therefore better performance gains. Gustafson’s Law expresses speedup as:
Equation:
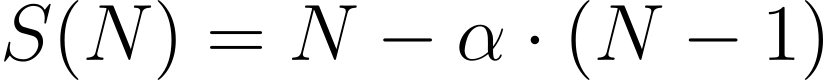
While Amdahl’s Law emphasizes the limitations of serial workloads, Gustafson’s Law presents a more flexible view that accommodates scalable workloads.
Both laws illustrate important aspects of parallelism. Amdahl’s Law stresses the impact of serial execution on limiting performance, while Gustafson’s Law highlights the potential for improved performance with larger problem sizes. Both of these restrictions must be taken into account when assessing the efficiency of parallel processing in modern computing environments. Researchers have observed that both laws are applicable under different conditions, depending on the ratio of problem size to available resources (Ristov et al., 2018).
Memory and Data Transfer Limits
CPUs rely on multi-level cache hierarchies to reduce memory access latency. For example, CPUs can use smaller, faster private caches such as 32 KB instruction and data caches, which provide low latency for cache hits (Koukos et al., 2016). This setup allows CPUs to access memory quickly, especially for workloads that can fit within the cache. In contrast, GPUs, optimized for throughput, tend to experience higher cache latencies but compensate by running many threads in parallel, effectively masking memory access delays (Fang, 2023). This design enables CPUs to perform well in tasks requiring frequent memory access while GPUs leverage parallelism to handle latency.
The underlying technology of memory systems imposes limits on their physical speed. For instance, emerging 3D-stacked memory architectures can achieve bandwidths of up to 431 GB/s, significantly exceeding the typical 115 GB/s of conventional CPUs (Oliveira et al., 2021).
As clock speeds rise, maintaining signal integrity becomes increasingly challenging. High-frequency signals may experience performance degradation due to factors like electromagnetic interference and crosstalk. Additionally, increased speeds generate more heat, which requires effective cooling solutions. The switching speeds of materials used in memory chips, like silicon, also present natural limits. Advancements in semiconductor technology aim to address these constraints, yet as component sizes shrink, challenges become more pronounced.
Both CPUs and GPUs face limitations from memory bandwidth and latency, with CPUs prioritizing latency and GPUs focusing on throughput.
High Bandwidth Memory (HBM) and its variants, such as the Hybrid Memory Cube (HMC), utilize 3D stacking technology to significantly increase memory bandwidth. For example, Intel's Knights Landing (KNL) processor incorporates HBM, specifically Multi-Channel DRAM (MCDRAM), achieving bandwidths of up to 450 GB/s, far exceeding traditional DDR memory configurations (Laghari et al., 2018; Leon et al., 2019). However, the capacity of 3D-stacked DRAM does not scale proportionally with bandwidth due to reliability considerations, which requires a hybrid approach that combines HBM and conventional off-chip DRAM to meet increasing capacity demands (Wang et al., 2015; Hadidi et al., 2017).
The maximum theoretical bandwidth for these memory technologies depends on the materials used and the architectural design. Traditional copper interconnects face limitations in signal integrity and resistance at higher frequencies. In contrast, emerging technologies such as photonic interconnects offer the potential to overcome these restrictions, enabling faster speeds with reduced latency and power consumption. If successfully integrated, photonic interconnections could facilitate bandwidths exceeding 1 TB/s, as demonstrated in certain FPGA implementations.
Von Neumann Bottleneck
The Von Neumann Bottleneck describes a fundamental constraint in computer architecture originating from John von Neumann's design in the 1940s. In this architecture, the CPU and memory are separated, connected solely by a single data bus. The finite bandwidth of this shared bus limits data transfer rates between the CPU and memory, constraining overall system performance.
In the Von Neumann architecture, program instructions and data share the same memory space. The CPU must fetch instructions, process them, and write results back to memory, all of which involve communication over the bus. This design inherently limits performance due to the finite bandwidth available for these operations.
To mitigate the impact of this bottleneck, modern processors implement multi-level cache hierarchies (L1, L2, L3) to store frequently accessed data closer to the CPU, thereby reducing latency. However, this introduces complexity in ensuring data consistency between cache levels and main memory.
Architectural innovations, such as in-memory computing (IMC), aim to alleviate the Von Neumann Bottleneck by enabling computations to occur directly in memory, minimizing the need for data transfer between the CPU and memory.
To meet the demands of contemporary computing applications, more integrated architectures are necessary, as the separation of memory and processing continues to limit performance and scalability.
Power and Energy Efficiency Limits
The shrinking of transistors has indeed led to greater transistor density over time, but this advancement presents significant challenges. Power density refers to the amount of power dissipated per unit area within a semiconductor. As transistors become smaller, the supply voltage (Vdd) and threshold voltage (Vt) must be scaled down to maintain performance. However, Dennard's scaling law began to falter in the early 2000s, leading to higher power density in newer generations of transistors due to increasing leakage currents and other non-ideal effects associated with smaller geometries (Silva et al., 2021; Moraes et al., 2020). This trend makes it more difficult to manage the heat generated by denser devices.
As transistor dimensions approach atomic scales, physical limits arise, including challenges related to gate control and the spatial constraints of interconnects. These factors significantly restrict the ability to create functional transistors at extremely small sizes.
The energy efficiency comparison between CPUs and GPUs is well-documented. CPUs can be approximately 2.4 times more energy-efficient than systems with a single GPU and 1.8 times more efficient than those using two GPUs (Mittal & Vetter, 2014). This underscores the necessity of application-specific metrics when evaluating energy efficiency. The collaborative efficiency (CE) metric assesses performance losses stemming from inter-node communication and data transfer between CPUs and GPUs, revealing potential inefficiencies in hybrid systems (Xu et al., 2016). While GPUs may consume more power under certain conditions, their design allows for efficient execution of parallel tasks, which can lead to better overall energy efficiency when effectively managed.
Ultimately, the energy efficiency of a CPU or GPU is determined by the specific requirements of an application. Both architectures have inherent benefits depending on the context. This highlights the importance of assessing energy efficiency on a case-by-case basis rather than making blanket assumptions about one being superior.
Computational Limits
Algorithmic Complexity
Algorithmic complexity, or computational complexity, is a key concept in computer science that defines the resources an algorithm needs to solve a specific problem. The complexity of algorithms can greatly affect their execution time and resource usage, directly impacting the performance of the hardware that runs them. Complex algorithms can have exponential resource requirements that can exceed the effective computing power of CPUs or GPUs.
Memory bottlenecks can arise in algorithms requiring frequent access to large datasets that exceed cache capacity, affecting performance across all hardware. Additionally, certain algorithms have sequential dependencies that limit their ability to be effectively parallelized across multiple GPU cores. As a result, despite the raw processing power of GPUs, they may not always outperform CPUs for specific types of problems. To fully utilize GPU capabilities, algorithms designed for CPUs often need significant adaptation. The combination of CPU and GPU resources in a hybrid architecture can improve performance; for example, a hybrid CPU-GPU pattern matching algorithm has been proposed that leverages the strengths of both architectures to achieve faster processing speeds (Lee et al., 2019).
Floating-Point Precision
Floating-point representation is a method used in computing to approximate real numbers. Both CPUs and GPUs use the IEEE 754 standard for floating-point representation, which defines how numbers are stored and processed in binary form. This standard includes formats for single precision (32 bits) and double precision (64 bits). Due to finite representation, not all real numbers can be represented exactly.
CPUs typically support 64-bit double-precision floating-point arithmetic but can handle multiple floating-point formats. High precision is prioritized in CPU design, which may impact performance in applications requiring extensive numerical calculations. While CPUs can achieve high precision, they are often slower than GPUs for parallel tasks (Friedrichs et al., 2009; Myllykoski et al., 2018).
Conversely, GPUs are optimized for parallel processing, allowing them to execute numerous floating-point operations simultaneously. Most GPUs, such as the Tesla V100, use primarily 32-bit single-precision floating-point arithmetic, allowing significantly higher throughput in floating-point calculations. For example, the Tesla V100 can achieve up to 14 Tflop/s for single-precision calculations and 7 Tflop/s for double precision (Lai, 2024). While GPUs provide substantial performance gains in specific applications, they may prioritize single-precision to enhance speed, whereas some tasks, particularly in scientific computing, require double-precision for greater accuracy.
In summary, CPUs provide higher accuracy but may be limited by memory bandwidth and processing speed. In contrast, GPUs excel in parallel computation, although they may necessitate a mixed precision strategy to balance performance and precision (Buttari et al., 2008).
Emerging Technologies and Future
The transition from traditional single-core architectures to multi-core architectures, especially GPUs, has already made significant advances in computational performance. The recent development of CPU design is increasingly focusing on chiplets-based and heterogeneous architectures, which provide greater flexibility and efficiency.
Chiplet-based architectures mark a departure from traditional monolithic chip designs. In these systems, several smaller "chiplets" are combined into a single package, each optimized for specific tasks. This modular approach not only improves performance but also improves manufacturing yield and reduces costs associated with larger chips (Thompson & Spanuth, 2021).
Specialized hardware accelerators are important in artificial intelligence (AI) and machine learning (ML). Devices such as tensor processing units (TPUs) and application-specific integrated circuits (ASICs) outperform common CPUs in dealing with specialized tasks. For example, TPUs can train deep learning models up to 16.3 times faster than GPUs (Lopez-Montiel et al., 2021).
Multi-Chip Module (MCM) designs are next-generation GPU architectures that enhance performance and reduce latency by integrating multiple chips within a single package, making them ideal for high-throughput applications like deep learning and simulations (Choi & Seo, 2021).
New memory technologies such as DDR5, LPDDR5X, and HBM3 (High-Bandwidth Memory) have been developed to meet the growing bandwidth requirements of modern GPUs, bringing improved data transmission speeds and energy efficiency.
Software frameworks such as NVIDIA CUDA (Compute Unified Device Architecture) and AMD ROCm (Radeon Open Compute) have evolved to support GPU-based high-performance computing. CUDA is still a popular parallel programming platform for NVIDIA GPUs, and ROCM provides open-source frameworks for AMD hardware.
The rise of heterogeneous computing, where CPUs and GPUs work together, has also transformed computational efficiency. In this model, tasks are allocated based on the strengths of each processor type, GPUs excel in parallel processing, while CPUs handle sequential tasks and complex control operations. This cooperative approach enhance performance for a wide range of applications (Liu et al., 2022; Wu & Xie, 2019).
Due to differences in CPU and GPU architectures, specialized programming techniques and tools are needed to optimize task execution in a heterogeneous environment. Traditional optimization strategies are often insufficient for these mixed systems, but progress in task scheduling and workload partitioning has shown improved performance on heterogeneous platforms (Chen 2024; Yu et al. 2022).
Domain-specific architectures (DSAs) have gained traction for their ability to optimize specific applications. For example, DSAs like ScaleDeep can outperform GPUs by 6 to 28 times in tasks like deep neural network training and inference (Jouppi et al., 2018). Similarly, domain-specific systems-on-chip (DSSoCs) combine general-purpose cores with specialized processors to close the performance gap in general-purpose computing (Krishnakumar et al., 2020).
Field-programmable Gate Arrays (FPGAs) are another example of domain-specific architectures that provide significant energy efficiency. The FPGA is very adaptable and can be reconfigured to suit different workloads, while the ASIC is customized to specific tasks and optimizes performance for these applications.
Looking ahead, quantum computing and neuromorphic chips represent the latest advances in specialized architectures. Using the principle of quantum mechanics, quantum computing can solve problems exponentially faster than classical systems (Rothmann et al., 2022). Neuromorphic computing, inspired by the brain’s neural networks, excels in pattern recognition and sensory processing tasks (Dally et al., 2020). These technologies are still in their early stages, but hold promise to restructure computational approaches in specific areas.
Conclusion
As we explored the limits of CPU and GPU architectures, we discovered a landscape characterized by both fundamental and architectural limitations. From the physical limitations of transistor scaling and memory bandwidth to the complexities of algorithmic efficiency, it is evident that both CPUs and GPUs face unique challenges in their quest to optimize performance.
However, the horizon is not only determined by challenges. New technologies such as chiplet-based designs, specialized hardware accelerators, and advances in heterogeneous computing offer exciting opportunities to push the boundaries of computing capabilities. Moving forward, integration of innovative approaches, including domain-specific architectures and quantum computing, holds the potential to redefine the way we solve complex problems and improve computational efficiency. Ultimately, we can foster a more nuanced understanding of the ever-evolving computing landscape by acknowledging the limitations of existing technologies while embracing the promise of future advances.