
In this article, we will discuss scalar computing (and some of its drawbacks), the need for vector/parallel computing, the fundamental concepts behind single instruction, multiple data (or SIMD) architecture, as well as one of its implementations in modern CPUs, namely: Intel's Streaming SIMD Extensions, or SSE for short.
Scalar Computing (SISD Architecture)
Before parallelization was widely implemented in computers systems around the world, scalar processors were used to solve computational problems. Scalar processors could only process one data element at a time. Only after one instruction was completed could the next one be executed, and this meant that it took a substantial amount of time to process large amounts of data. Thus, even though scalar systems are simpler and some of its functions are often quicker, the fact that data elements are processed sequentially bogs down the overall speed and efficiency of the processor when we have to work on a large amount of data. This type of processor architecture is known as single instruction, single data (SISD) architecture.
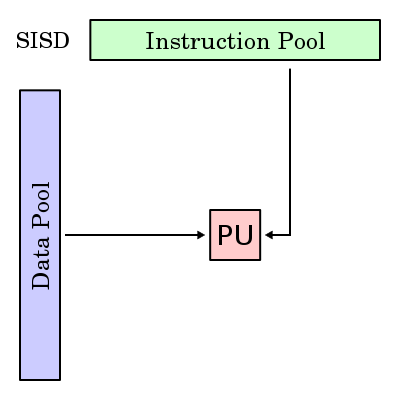
The Intel 486 (or i486) is an example of a scalar processor. It was introduced in 1989.
Vector Computing (SIMD Architecture)
In order to combat these drawbacks, Intel understood the need for parallelization and began integrating single instruction, multiple data (or SIMD) vector capabilities into their processors in the late 1990s, and most modern processors now work on this type of architecture. In this day and age, we are often required to perform identical operations across multiple data elements, and this is where SIMD instructions can substantially accelerate performance. This is because, instead of performing the same instruction on each data element one at a time, we can perform the instruction on a group of data elements all at once.
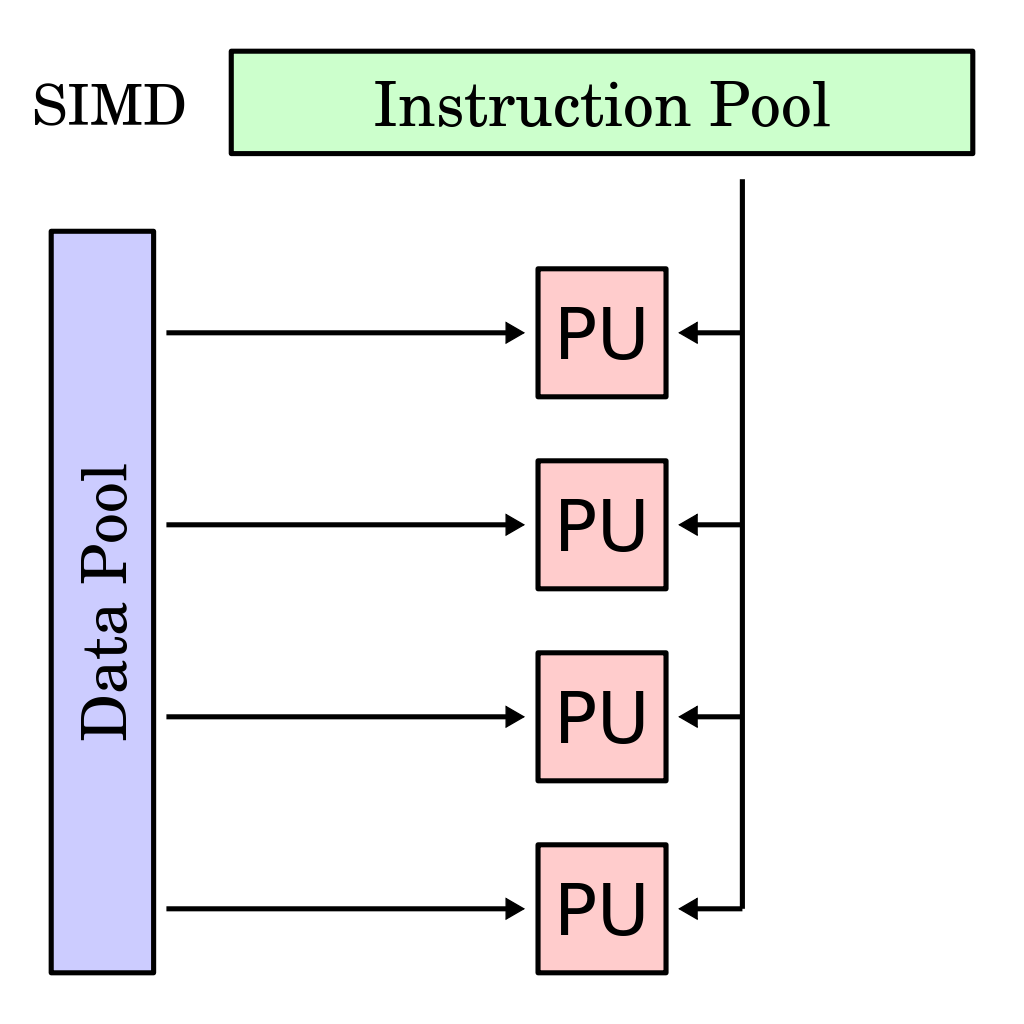
The data pertaining to the operands are stored in special wide registers.
An Example That Illustrates The Difference Between SISD & SIMD Instructions
Let us assume that we have three integer arrays- X, Y and Z. We wish to add the elements of X and Y continuously (in a loop) and store the results in the array Z. In each iteration of the loop, we will find that we have to perform an addition operation, two load operations (for the elements of X and Y), as well as a store operation (in Z). These operations are exactly the same in each and every iteration of the loop. The only thing that is changing is the elements that the operations are being performed on. This means that we can solve this particular problem much more quickly with the help of SIMD instructions, since we can process multiple elements simultaneously.
With SIMD instructions and 128-bit registers, we can process not one, but four integer elements at the same time. A single load instruction can get four elements of the integer array X into a 128-bit SIMD register, and the same goes for the integer array Y. Then, a single add instruction can add the values in both registers. Finally, a single store instruction can store all of these newly obtained values in the integer array Z.
Programming in this way is not as straightforward as programming without accounting for parallelization, but doing so can save us a lot of time if the situation calls for the use of SIMD instructions.
SSE Instruction Set
Intel's Streaming SIMD Extensions (SSE), was a SIMD instruction set extension to the existing 32-bit (x86) CPU architecture. Intel first introduced this technology in 1999, with their Pentium III line of processors, starting with 'Katmai'. It provided SIMD instructions as well as eight 128-bit registers (XMM0 - XMM7), as opposed to the 32-bit registers that were used by traditional scalar processors at the time, which allowed for up to four 32-bit data elements to be processed simultaneously, which was found to greatly accelerate performance (of supported operations). A new 32-bit control/status register was also introduced (MXCSR). It included 65 new instructions (70 total encodings) over MMX, which was Intel's previous implementation of SIMD architecture. Advanced imaging, speech recognition and 3-D video are some technologies that benefited from the introduction of SSE.

Since SSE was effectively an extension to MMX; SSE and MMX instructions could be mixed with no penalties to the system's performance.
Let us now take a look at all of the new instructions that were introduced in Intel's Streaming SIMD Extensions technology, as well as one example of each type of instruction. In order to understand these instructions better, we will simplify them to only operate on one 32-bit single-precision floating-point value, and not four, wherever applicable.
Data Transfer Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| MOVAPS | Move four aligned packed single-precision floating-point values between XMM registers or memory. |
| MOVHLPS | Move two packed single-precision floating-point values from the high quadword of an XMM register to the low quadword of another XMM register. |
| MOVHPS | Move two packed single-precision floating-point values to or from the high quadword of an XMM register or memory. |
| MOVLHPS | Move two packed single-precision floating-point values from the low quadword of an XMM register to the high quadword of another XMM register. |
| MOVLPS | Move two packed single-precision floating-point values to or from the low quadword of an XMM register or memory. |
| MOVMSKPS | Extract sign mask from four packed single-precision floating-point values. |
| MOVSS | Move scalar single-precision floating-point value between XMM registers or memory. |
| MOVUPS | Move four unaligned packed single-precision floating-point values between XMM registers or memory. |
For example:
If we perform the operation- 'MOVAPS xmm1, xmm2/m128', four packed single-precision floating-point values are moved from the source operand (xmm2/m128) to the destination operand (xmm1). The source is left unchanged, so both the source and the destination register will contain the same values.
If our source operand is as follows:
| S | 1111 1111 1111 1111......1111 (128 bits) |
|---|
Then, on performing the above operation, our destination operand will now look like this:
| D | 1111 1111 1111 1111......1111 (128 bits) |
|---|
Packed Arithmetic Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| ADDPS | Add packed single-precision floating-point values. |
| ADDSS | Add scalar single-precision floating-point values. |
| DIVPS | Divide packed single-precision floating-point values. |
| DIVSS | Divide scalar single-precision floating-point values. |
| MAXPS | Return maximum packed single-precision floating-point values. |
| MAXSS | Return maximum scalar single-precision floating-point values. |
| MINPS | Return minimum packed single-precision floating-point values. |
| MINSS | Return minimum scalar single-precision floating-point values. |
| MULPS | Multiply packed single-precision floating-point values. |
| MULSS | Multiply scalar single-precision floating-point values. |
| RCPPS | Compute reciprocals of packed single-precision floating-point values. |
| RCPSS | Compute reciprocal of scalar single-precision floating-point values. |
| RSQRTPS | Compute reciprocals of square roots of packed single-precision floating-point values. |
| RSQRTSS | Compute reciprocal of square root of scalar single-precision floating-point values. |
| SQRTPS | Compute square roots of packed single-precision floating-point values. |
| SQRTSS | Compute square root of scalar single-precision floating-point values. |
| SUBPS | Subtract packed single-precision floating-point values. |
| SUBSS | Subtract scalar single-precision floating-point values. |
For example:
If we perform the operation 'ADDPS xmm1, xmm2/m128', the four packed single-precision floating-point values of the source operand (xmm2/m128) are added with the values of the destination operand (xmm1), and the obtained packed result is stored in the destination operand.
If our source operand is as follows:
| S | 0010 1011 0111 0011 1000 0000 1100 0011 |
|---|
And if our destination operand is as follows:
| D | 0010 1001 1100 1110 0101 1111 0001 1111 |
|---|
Then, on performing the above operation, our destination operand will now look like this:
| D | 0101 0101 0100 0001 1101 1111 1110 0010 |
|---|
Compare Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| CMPPS | Compare packed single-precision floating-point values. |
| CMPSS | Compare scalar single-precision floating-point values. |
| COMISS | Perform ordered comparison of scalar single-precision floating-point values and set flags in EFLAGS register. |
| UCOMISS | Perform unordered comparison of scalar single-precision floating-point values and set flags in EFLAGS register. |
For example:
If we perform the operation- 'CMPPS xmm1, xmm2/m128, imm8', the packed single-precision floating-point values in the destination operand (xmm1) and the source operand (xmm2/m128) are compared using imm8 as the comparison predicate. This comparison predicate specifies what kind of comparison will take place between the two operands. If the comparison is true, then the result is a double word mask of all 1s, and if the comparison is false then the result is a double word mask of all 0s. This result is returned to the destination operand.
If our comparison predicate is 0, and our source register is as follows:
| S | 0110 1011 1111 0011 1010 0000 1100 0011 |
|---|
And if our destination operand is as follows:
| D | 0110 1011 1111 0011 1010 0000 1100 0011 |
|---|
Then, on performing the above operation, our destination operand will now look like this, since the comparison between the two values will produce the result 'TRUE':
| D | 1111 1111 1111 1111 1111 1111 1111 1111 |
|---|
Logical Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| ANDNPS | Perform bitwise logical AND NOT of packed single-precision floating-point values. |
| ANDPS | Perform bitwise logical AND of packed single-precision floating-point values. |
| ORPS | Perform bitwise logical OR of packed single-precision floating-point values. |
| XORPS | Perform bitwise logical XOR of packed single-precision floating-point values. |
For example:
If we perform the operation 'ANDPS xmm1, xmm2/m128', the four packed single-precision floating-point values of the source operand (xmm2/m128) are AND-ed with the values of the destination operand (xmm1), and the obtained result is stored in the destination operand.
If our source operand is as follows:
| S | 0010 1011 0111 0011 1000 0000 1100 0011 |
|---|
And if our destination operand is as follows:
| D | 0010 1001 1100 1110 0101 1111 0001 1111 |
|---|
Then, on performing the above operation, our destination operand will now look like:
| D | 0010 1001 0100 0010 0000 0000 0000 0011 |
|---|
Shuffle & Unpack Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| SHUFPS | Shuffles values in packed single-precision floating-point operands. |
| UNPCKHPS | Unpacks and interleaves the two high-order values from two single-precision floating-point operands. |
| UNPCKLPS | Unpacks and interleaves the two low-order values from two single-precision floating-point operands. |
For example:
If we perform the operation- 'SHUFPS xmm1, xmm2/m128, imm8', two packed single-precision floating-point values are moved from the destination operand (xmm1) into the low quadword of the destination operand, and two packed single-precision floating-point values are moved from the source operand (xmm2/m128) into the high quadword of the destination operand. The select operand (imm8) is what decides which values are moved to the destination operand.
Thus, if our select operand is '0000 0000', and our source register is as follows:
| S | 0000 0000 0000.............0000 (128 bits) |
|---|
And if our destination operand is as follows:
| D | 1111 1111 1111.............1111 (128 bits) |
|---|
Then, on performing the above operation, our destination operand will now look like:
| D | 0000 0000......0000 (64 bits) 1111 1111......1111 (64 bits) |
|---|
Conversion Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| CVTPI2PS | Convert packed doubleword integers to packed single-precision floating-point values. |
| CVTPS2PI | Convert packed single-precision floating-point values to packed doubleword integers. |
| CVTSI2SS | Convert doubleword integer to scalar single-precision floating-point value. |
| CVTSS2SI | Convert scalar single-precision floating-point value to a doubleword integer. |
| CVTTPS2PI | Convert with truncation packed single-precision floating-point values to packed doubleword integers. |
| CVTTSS2SI | Convert with truncation scalar single-precision floating-point value to scalar doubleword integer. |
For example:
If we perform the operation- 'CVTPI2PS xmm, mm/m64', two packed signed doubleword integers in the source operand (mm/m64) are converted to two packed single-precision floating-point values in the destination operand (xmm). The obtained results are stored in the low quadword of the destination operand while the high quadword remains unchanged.
If our source operand is as follows:
| S | 1111 1111 1111.............1111 (64 bits) |
|---|
And if our destination operand is as follows:
| D | 0000 0000 0000.............0000 (128 bits) |
|---|
Then, on performing the above operation, our destination operand will now look like this:
| D | 0000 0000......0000 (64 bits) 1111 1111......1111 (64 bits, high quadword remains unchanged) |
|---|
MXCSR Status/Control Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| LDMXCSR | Load %mxcsr register. |
| STMXCSR | Save %mxcsr register state. |
These instructions are simply used to load the MXCSR register from m32, and to store the contents of the MXCSR register to m32.
64-bit SIMD Integer Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| PAVGB | Compute average of packed unsigned byte integers. |
| PAVGW | Compute average of packed unsigned byte integers. |
| PEXTRW | Extract word. |
| PINSRW | Insert word. |
| PMAXSW | Maximum of packed signed word integers. |
| PMAXUB | Maximum of packed unsigned byte integers. |
| PMINSW | Minimum of packed signed word integers. |
| PMINUB | Minimum of packed unsigned byte integers. |
| PMOVMSKB | Move byte mask. |
| PMULHUW | Multiply packed unsigned integers and store high result. |
| PSADBW | Compute sum of absolute differences. |
| PSHUFW | Shuffle packed integer word in MMX register. |
For example:
If we perform the operation- 'PMINSW xmm1, xmm2/m128', the packed signed word integers in the destination operand (xmm1) are compared with those in the source operand (xmm2/m128), and the minimum value for each pair of word integers is returned to the destination operand.
If our source operand is as follows:
| S | 1010 1010 1111 1111 1010 1010 1111 1111 |
|---|
And if our destination operand is as follows:
| D | 1010 0101 0101 1010 1010 0101 0101 1010 |
|---|
Then, on performing the above instruction, our destination operand will now look like this:
| D | 1010 0000 0101 1010 1010 0000 0101 1010 |
|---|
Miscellaneous Instructions
| Intel/AMD Mnemonic | Description |
|---|---|
| MASKMOVQ | Non-temporal store of selected bytes from an MMX register into memory. |
| MOVNTPS | Non-temporal store of four packed single-precision floating-point values from an XMM register into memory. |
| MOVNTQ | Non-temporal store of quadword from an MMX register into memory. |
| PREFETCHNTA | Prefetch data into non-temporal cache structure and into a location close to the processor. |
| PREFETCHT0 | Prefetch data into all levels of the cache hierarchy. |
| PREFETCHT1 | Prefetch data into level 2 cache and higher. |
| PREFETCHT2 | Prefetch data into level 2 cache and higher. |
| SFENCE | Serialize store operations. |
For example:
If we perform the operation- 'MASKMOVQ mm1, mm2', selected bytes from the source operand (mm1) are stored into a 64-bit memory location. The mask operand (mm2) selects which bytes from the source operand are written into the memory.
If our source operand is as follows:
| S | 1111 1111 1111.............1111 (64 bits) |
|---|
And if our mask operand is as follows (where the bit with index 7 is 1):
| M | 0000 0000 0000.............0000 (56 bits) 1000 0000 |
|---|
Then, the bits from indices 0-7 from the source operand are written into the memory. Let us assume that prior to us performing the above operation, the memory location in question contains all 0s. After we perform said operation, the memory location changes to this:
| Mem | 0000 0000...... 0000 (120 bits) 1111 1111 |
|---|
The rest of the bits in the memory remain unchanged, as only the bit with index 7 of the mask operand is 1, and the rest of them are 0.
Future Iterations
SSE was incrementally improved over the years.
- SSE2 added the double-precision floating-point format (64-bit) for all SSE operations, and also allowed for MMX integer operations to take place in 128-bit XMM registers, as opposed to the 64-bit MMX registers that were used in the first iteration of SSE.
- SSE3 brought about less noticeable changes. It introduced a few new thread management instructions and allowed for 'horizontal' computing. This meant that two numbers that were stored in the same register could be added or multiplied.
- SSSE3 was an upgrade to SSE3, and introduced 16 new permutation, addition and accumulation instructions.
- SSE4 was a major upgrade to SSSE3, and introduced a dot product instruction, new integer instructions, a population count instruction, and more.
- AVX, AVX-2 and AVX-512 hugely expanded on the number of as well as the size of registers. This allowed for significantly accelerated performance when dealing with computationally intensive workloads. Many Machine Learning based tasks benefited from the introduction of these processor architectures. Read more about AVX, AVX-2 and AVX-512 here.
Conclusion
In this article at OpenGenus, we learnt about scalar processing (SISD), vector processing (SIMD) and Intel's Streaming SIMD Extensions (SSE) instruction set, which is an implementation of SIMD architecture in modern CPUs. We also took a look at all of the new instructions that were introduced with SSE, and discussed the improvements that were made to SSE technology in future iterations.
Thanks for reading!