
In this article, we will discuss Intel's Advanced Vector Extensions 512 (AVX-512), which is an instruction set that was created to accelerate computational performance in areas such as artificial intelligence/deep learning, scientific simulations, cryptographic hashing, data protection and more. We will also take a closer look at some of its inherent advantages and disadvantages, and compare it with other instruction sets such as its predecessors, AVX and AVX-2.
What is AVX-512?
Before the days of parallel computing, instructions could only be performed on a single data element at a time. Only after one instruction was finished could the next one be executed. Thus, it took a very long time for us to be able to process large amounts of data. This type of processor architecture is known as SISD (or single instruction, single data).
Owing to the drawbacks of SISD architecture, Intel started integrating SIMD (or single instruction, multiple data) vector capabilities into their processors in the late 1990s, and most modern processors now work on this architecture. In this day and age, we are often required to perform identical operations across multiple data elements, and this is where SIMD instructions can substantially accelerate performance. This is because we do not have to treat each data element as a unique entity when subjecting it to the common instruction, we can subject all of the data elements to the common instruction simultaneously.
Traditional scalar processors had 32-bit registers, and could only process one 32-bit data element at a time. Intel's SSE Technology (Streaming SIMD Extensions), on the other hand, bumped this number up to 128-bits, which allowed for four 32-bit data elements to be processed simultaneously.

Intel's AVX and AVX-2 further built on this concept by doubling the size of its registers to 256-bits, thus allowing for eight 32-bit data elements to be processed simultaneously. New features were also added, and these changes brought with them a performance gain of up to 200% on supported operations.

This brings us to Intel's AVX-512, which was created in order to take vector performance to new heights. It doubled the size of its registers once more, now to 512-bits. Not only was the size of its registers doubled, though. The number of registers was also doubled, thus minimizing latency and maximizing performance.

This architecture was proposed in July 2013, and was then implemented in Intel's Xeon Phi x200 (Knights Landing) and Skylake-X CPUs.
Now that we know about the building blocks of AVX-512, we will discuss some of its advantages and disadvantages.
Advantages
As we previously discussed, AVX-512 can greatly accelerate performance for computationally intensive workloads, since it allows for the processing of twice as many data elements (at once) when compared to its predecessors, AVX and AVX-2. It also accelerates storage functions, and allows for heightened data security due to its ability to process cryptographic algorithms quickly and efficiently.
Benefits in Machine Learning
AVX-512 VNNI (Vector Neural Network Instructions), an x86 extension of AVX-512, introduced four new instructions that were found to significantly accelerate algorithms based on convolutional neural networks.
In convolutional neural network based systems, we often have to repeatedly multiply two 8-bit or 16-bit values and accumulate the result in a 32-bit accumulator. For now, let us assume that we are working with 8-bit values. In order to perform the above operations using AVX-512 Foundation, we have to use the following instructions:
- VPMADDUBSW - This instruction multiplies the two 8-bit values and then adds them.
- VPMADDWD - This instruction (along with the value 1) converts the 16-bit values to 32-bit values.
- VPADDD - This instruction then adds the resultant value to an accumulator.
AVX-512 VNNI introduced two new instructions, as well as two saturated versions of these instructions, that essentially merged the above AVX-512 Foundation instructions to simplify the multiplication-accumulation operations. These new instructions are as follows:
- VPDPBUSD - This instruction merges VPMADDUBSW, VPMADDWD, and VPADDD.
- VPDPWSSD - This instruction merges VPMADDWD and VPADDD.
These instructions greatly improve the performance of convolutional neural network based systems, since we need to perform the multiplication-accumulation operations very often in the convolutional layer, and these convolutional layers happen to be the most computationally expensive segments of neural network based systems. So, merging the AVX-512 Foundation instructions into new, singular instructions can save us a significant amount of time.
Disadvantages
One of the biggest disadvantages associated with AVX-512 is that its instructions are extremely power hungry. If we use these instructions on more than one core, we'll more than likely see an immediate drop in performance. Its current implementations (such as in the Skylake-X CPUs) leave much to be desired, since it causes the clock-rate to drop in ways that are not easy to predict.
If we're working with only vector code (512-bits at a time), then we will absolutely benefit from using AVX-512. However, if we interleave scalar and vector code, then we will either see no change in performance, or marginally worse performance since the scalar, non-SIMD code will be running at a slower clock-rate.
Another disadvantage is that since it's still a fairly recent computer architecture, there are not many programs that can actually utilize these new instructions. It takes a significant amount of time for coders to understand them, and existing code needs to be re-written in order to implement them.
It also costs more than its predecessors.
New Instructions
There are many entirely new instructions, majorly reworked instructions, and also old instructions that have been replaced with new AVX-512 versions of them. There are far too many of them to cover in this article, although we will take a look at a few new AVX-512 Foundation instructions!
- Bitwise Ternary Logic - Two new instructions were added, and these instructions make it possible for us to perform all the possible permutations of bitwise operations between three input bits.
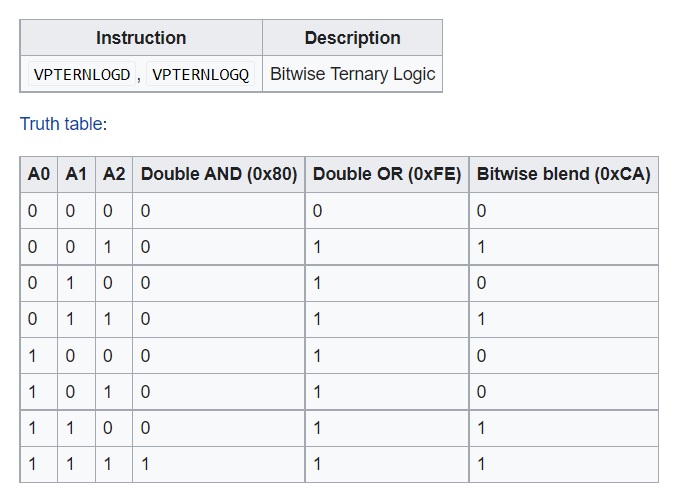
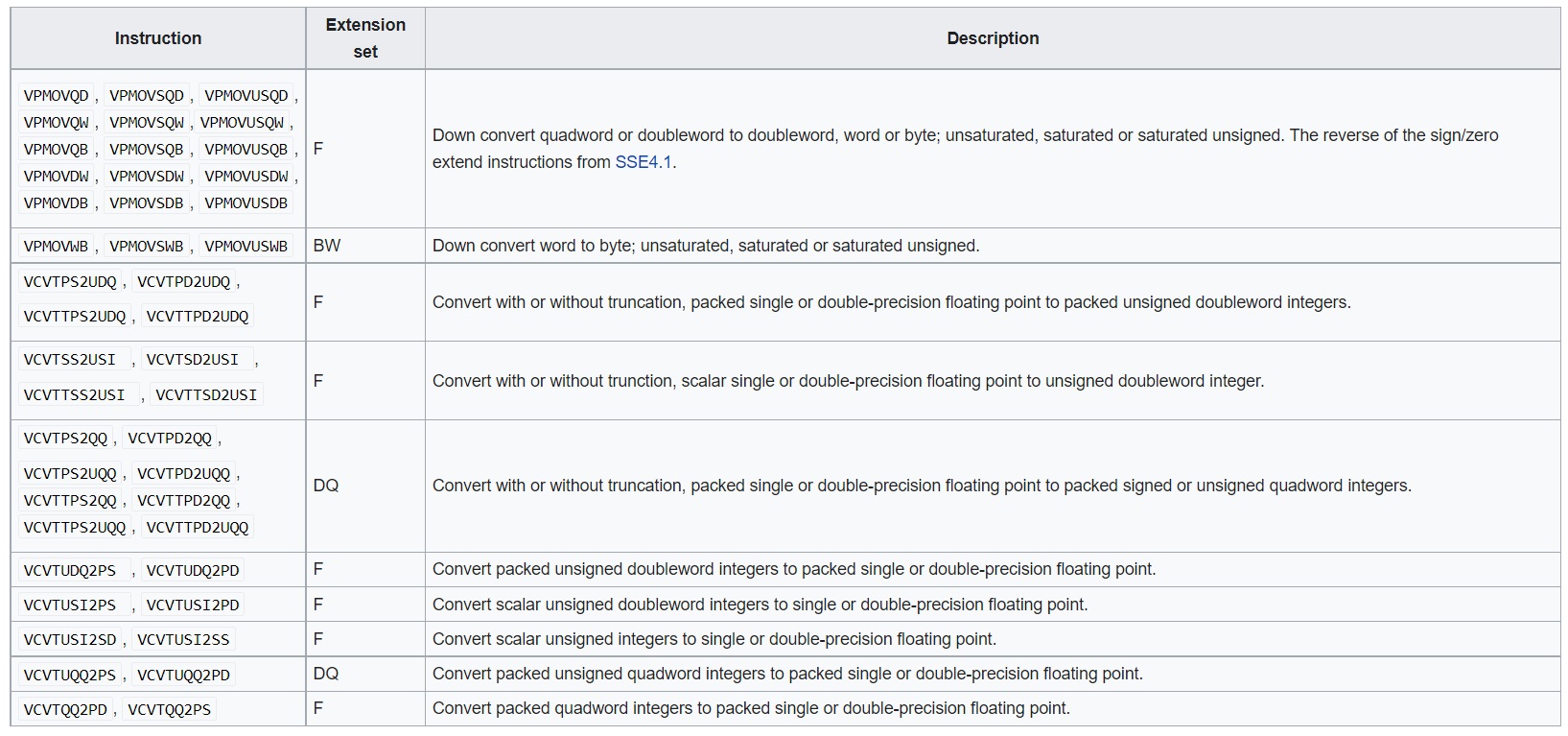
- Conversion Instructions - Numerous type conversion (word->byte, int->floating point, and so on) and move instructions were added.
- Floating Point Decomposition - These instructions can be used to decompose floating point values and to handle special floating point values.

There are many more instructions that can perform tasks such as blending, comparing, compressing/expanding, permuting, broadcasting, and more!
Conclusion
In this article at OpenGenus, we discussed Intel's AVX-512, its uses in the real world (such as its applications in Machine Learning), its advantages and disadvantages, and we also looked at some newly introduced AVX-512 Foundation instructions.
While AVX-512 has plenty of potential, its present-day implementations are not quite where we want them to be. However, with time, we can expect to see much better implementations with fewer trade-offs!
Thanks for reading!