Reading time: 30 minutes
Graphics Processing Unit had been developed to render graphics faster and since then, it ha found applications in Machine Learning inference. We have explored the key ideas that are used in Graphics Processing Unit to make it so fast.
Key ideas that make GPU fast are:
- Use many “slimmed down cores,” run them in parallel
- Pack cores full of ALUs (by sharing instruction stream overhead across groups of fragments)
- Option 1: Explicit SIMD vector instructions
- Option 2: Implicit sharing managed by hardware
- Avoid latency stalls by interleaving execution of many groups of fragments
- When one group stalls, work on another group
Idea 1: Use many “slimmed down cores,” run them in parallel
1 core running 1 fragment (basic case same as a CPU)
4 cores running 4 fragments in parallel (4 times improvement)
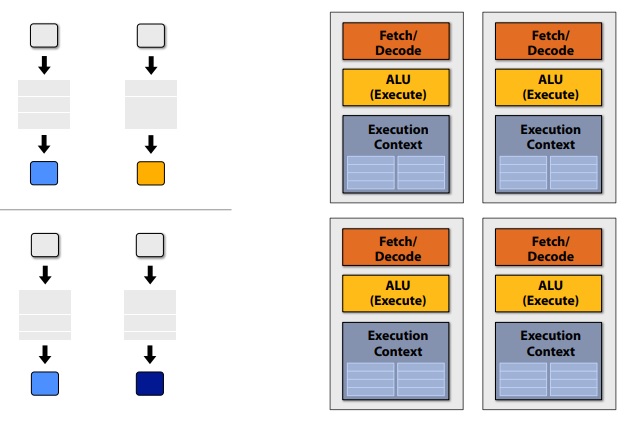
16 cores running 16 fragments in parallel (16 times improvement)
16 cores means 16 simultaneous instruction streams
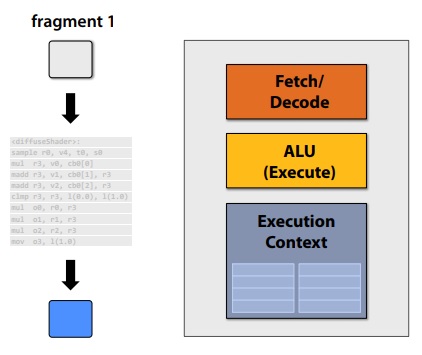
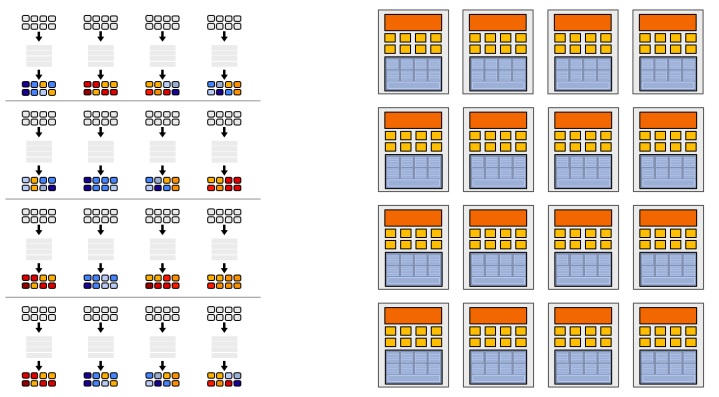
Idea 2: Amortize cost/complexity of managing an instruction stream across many ALUs
Original compiled shader processes one fragment using scalar ops on scalar registers
New compiled shader will process eight fragments using vector ops on vector egisters
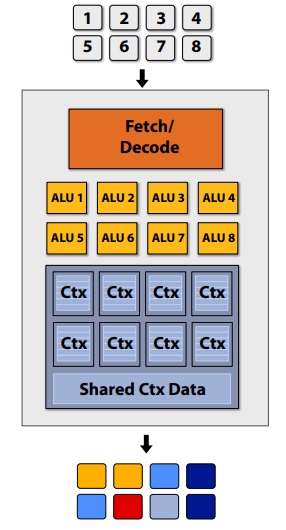
128 fragments in parallel:
16 cores = 128 ALUs , 16 simultaneous instruction streams
GPUs share instruction streams across many fragments
In modern GPUs: 16 to 64 fragments share an instruction stream.
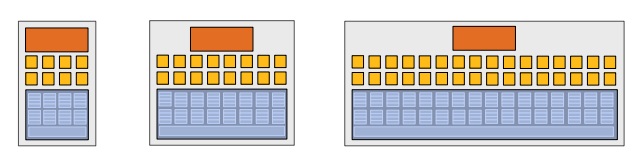
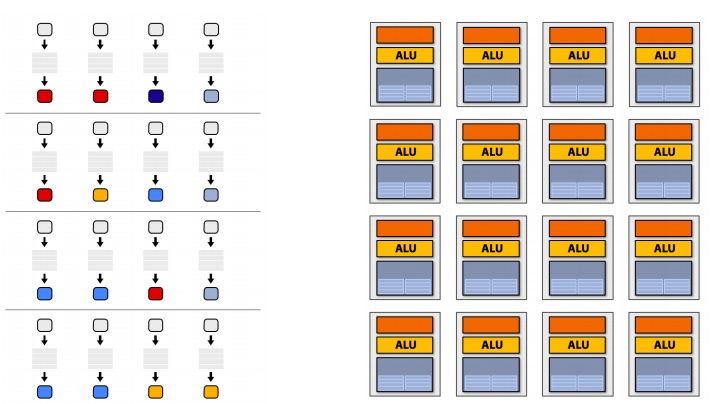
Idea 3: Interleave processing of many fragments on a single core to avoid stalls caused by high latency operations
Stalls occur when a core cannot run the next instruction because of a dependency on a previous operation
This image demonstrates stalls:
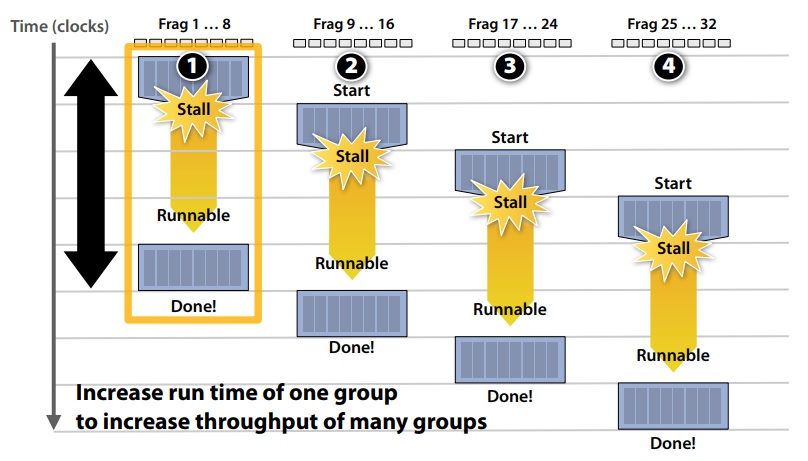
To maximize latency hiding, the context storage space is split into multiple components as demonstrated:
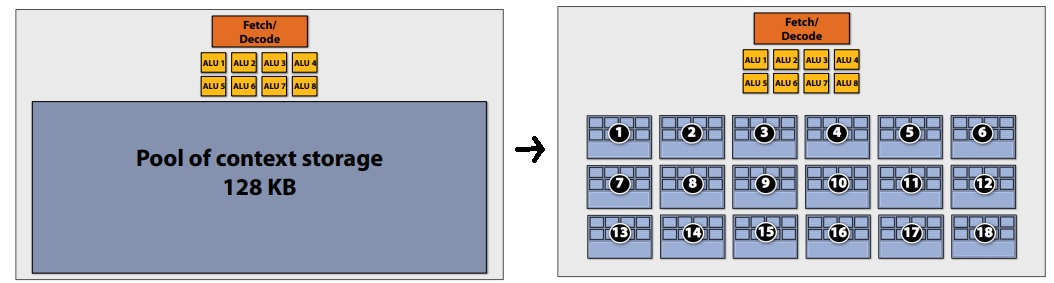
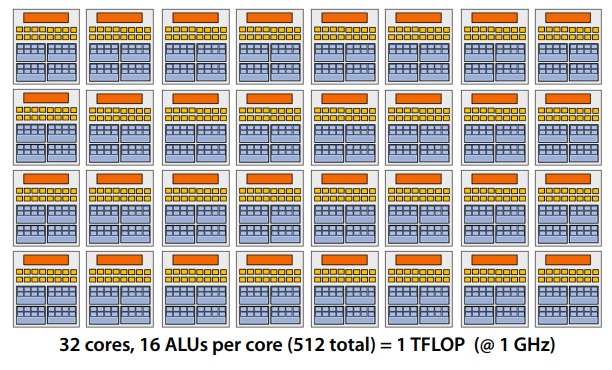
Overall design
Our overall design has the following specifications:
- 32 cores
- 16 mul-add ALUs per core (512 total)
- 32 simultaneous instruction streams
- 64 concurrent (but interleaved) instruction streams
- 512 concurrent fragments = 1 TFLOPs (@ 1GHz)