
This article at OpenGenus provides an overview of two types of computer memory architectures - UMA (Uniform Memory Access) and NUMA (Non-Uniform Memory Access). It explains how processors access system memory in both architectures and discusses their advantages and disadvantages. The article at OpenGenus also includes a practical code example for developing custom applications for both architectures. Additionally, the article highlights the differences between UMA and NUMA architecture, using a table format to easily compare the two. The article at OpenGenus explores their practical applications in real-life scenarios and provides questions to enhance interactivity and encourages discussion among OpenGenus members. Overall, this article provides a comprehensive understanding of UMA and NUMA architecture and their importance in modern computing systems.
Table of contents
- Introduction
- UMA Architecture
- NUMA Architecture
- Code Snippets
- Differences between UMA and NUMA
- Applications
- Questions and Discussion
- Conclusion
Introduction
Computer memory architecture refers to the way that a computer's memory is organized and accessed. Two common types of computer memory architecture are Uniform Memory Access (UMA) and Non-Uniform Memory Access (NUMA).
UMA architecture is characterized by all processors having equal access to the memory, with no portion of memory being closer to any one processor. NUMA architecture, on the other hand, allows processors to access local memory faster than remote memory. This means that the memory is divided into different regions, with each processor having its own region of local memory.
To better understand the concept of UMA and NUMA architecture, it's helpful to visualize the structure of a CPU. The image below shows a simplified diagram of a CPU, with each processor core represented by a rectangle and the memory represented by a square.
In the next sections, we'll delve deeper into the differences between UMA and NUMA architecture, as well as their advantages and disadvantages.
UMA Architecture
UMA architecture is a memory access model where all processors have equal access to the memory, and no portion of memory is closer to any one processor. In this architecture, the memory is shared equally among all processors, and any processor can access any part of the memory at any time. This makes UMA architecture simple and easy to implement, as well as highly scalable.
Advantages of UMA architecture include:
Ease of implementation: UMA architecture is simple to implement and requires minimal hardware modifications, making it a cost-effective solution.
Scalability: Since all processors have equal access to the memory, UMA architecture can easily scale up to include more processors without affecting memory access times.
Disadvantages of UMA architecture include:
Memory contention: As the number of processors accessing the memory increases, memory contention can occur, leading to slower access times.
Limited memory bandwidth: Since all processors share the same memory bus, the available memory bandwidth can become a bottleneck.
An example of a system that uses UMA architecture is a symmetric multiprocessing (SMP) system. In an SMP system, multiple processors share a common memory and are controlled by a single operating system instance. This architecture is commonly used in servers and high-performance computing systems.
To summarize, UMA architecture offers simplicity and scalability, but can suffer from memory contention and limited memory bandwidth in large-scale systems.
NUMA Architecture
Non-Uniform Memory Access (NUMA) architecture is a memory access model where memory is divided into multiple memory banks, and each processor has access to its own local memory bank. Processors can also access memory banks assigned to other processors, but at a higher latency than their local memory bank. This architecture allows for efficient use of memory resources and can provide better performance than UMA architecture for some workloads.
Advantages of NUMA architecture include:
Reduced memory contention: Since each processor has its own local memory, there is reduced contention for shared memory resources.
Increased memory bandwidth: Each processor has its own local memory bank, which can provide higher memory bandwidth than UMA architecture.
Efficient use of memory resources: NUMA architecture can allow for better utilization of memory resources, as memory can be allocated to processors based on their specific needs.
Disadvantages of NUMA architecture include:
Higher implementation complexity: NUMA architecture requires additional hardware and software complexity to manage the multiple memory banks.
Higher latency for remote memory access: Accessing memory banks assigned to other processors incurs a higher latency than accessing local memory.
An example of a system that uses NUMA architecture is a multi-socket server. In a multi-socket server, each socket has its own processors and memory banks, and the sockets are connected via a high-speed interconnect. This architecture is commonly used in data centers and can provide better performance than UMA architecture for certain workloads.
To help readers understand NUMA architecture and its importance, it's important to explain some key terms and methods:
NUMA architecture involves grouping processors into nodes that share a common pool of memory. NPS1 means that each socket has one NUMA node, while NPS4 means that each socket has four NUMA nodes. This affects how memory is accessed and distributed across nodes in the architecture. The numa_alloc_local() function can be used in code to allocate memory in the local memory bank of the current processor's NUMA node, which can provide faster memory access times.
In a UMA architecture, all processors have equal access to the same pool of memory, which is typically connected to a memory controller that is shared across all processors. This allows for faster memory access but can lead to potential bottlenecks if too many processors are accessing memory simultaneously.
Connections in a NUMA architecture typically involve connecting multiple nodes via a network or bus. This allows processors in different nodes to communicate and share data, but also introduces potential latency and bandwidth limitations. In contrast, in a UMA architecture, all processors are connected directly to the shared memory controller, which eliminates the need for inter-node communication.
In summary, NUMA architecture can provide better performance for certain workloads, but requires additional hardware and software complexity. Key terms and methods, such as nodes per socket (NPS) and the numa_alloc_local() function, can help optimize performance for NUMA architectures.
Code Snippets
Developing a custom application for both UMA and NUMA architecture requires an understanding of the memory architecture and the programming techniques to take advantage of it. Here are some examples of code that can be used to develop custom applications for UMA and NUMA architecture:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <sys/time.h>
#include <numa.h>
// Define the number of iterations and the size of the array
#define ITERATIONS 100000000
#define ARRAY_SIZE 100000000
// Define the function for processing the array
void process_array(int* array, int size) {
int sum = 0;
for (int i = 0; i < size; i++) {
sum += array[i];
}
}
int main(int argc, char **argv) {
int i, j, num_cpus, num_nodes, cpu, node;
int *array;
struct timeval start, end;
double elapsedTime;
// Initialize NUMA library
numa_set_localalloc();
// Determine the number of available CPUs and nodes
num_cpus = numa_num_configured_cpus();
num_nodes = numa_num_configured_nodes();
// Allocate memory for the array
array = (int*)numa_alloc_local(ARRAY_SIZE * sizeof(int));
// Initialize the array with random values
for (i = 0; i < ARRAY_SIZE; i++) {
array[i] = rand() % 100;
}
// Start the timer
gettimeofday(&start, NULL);
// Loop through the iterations and process the array
for (i = 0; i < ITERATIONS; i++) {
// Determine the CPU and node for this iteration
cpu = i % num_cpus;
node = i % num_nodes;
// Set the CPU and node for this thread
numa_run_on_node(node);
numa_set_preferred(cpu);
// Process the array
process_array(array, ARRAY_SIZE);
}
// Stop the timer and calculate the elapsed time
gettimeofday(&end, NULL);
elapsedTime = (end.tv_sec - start.tv_sec) + (end.tv_usec - start.tv_usec) / 1000000.0;
// Print the elapsed time
printf("Elapsed Time: %.4f seconds\n", elapsedTime);
// Free the memory for the array
numa_free(array, ARRAY_SIZE * sizeof(int));
return 0;
}
This code demonstrates how to develop a custom application for both UMA and NUMA architectures using the NUMA library. The numa_alloc_local function is used to allocate memory on the local node, and the numa_run_on_node and numa_set_preferred functions are used to set the CPU and node for each iteration.
The complexity of the code is moderate, and it requires some knowledge of the NUMA architecture and the NUMA library. However, once the basic concepts are understood, it is relatively straightforward to develop custom applications for both UMA and NUMA architectures using this code as a starting point.
Differences between UMA and NUMA
Below is a table highlighting the differences between UMA and NUMA architectures. The table is organized into three columns: point which indicates the specific difference, numa which represents the characteristics of NUMA architecture, and uma which represents the characteristics of UMA architecture. The table is presented using an HTML format to ensure easy readability and avoid horizontal scrolling.
| Point | NUMA | UMA |
|---|---|---|
| Memory access time | Memory access time varies depending on the location of the data in memory. Accessing data in the local memory of a processor is faster than accessing data in the memory of a remote processor. | Memory access time is uniform across all processors since they share the same memory pool. |
| Scalability | NUMA architecture is highly scalable and can support a large number of processors. | UMA architecture is not as scalable as NUMA and may face performance issues when used with a large number of processors. |
| Memory management | Memory management is more complex in NUMA architecture since each processor has its own memory cache and needs to access data in other processors' memory banks. | Memory management is simpler in UMA architecture since all processors share the same memory pool. |
Below are images illustrating the differences between NUMA and UMA architectures.
In Uniform Memory Access (UMA) diagram, all processors have same latency to access memory and a hardware cache is usually present with each processor.
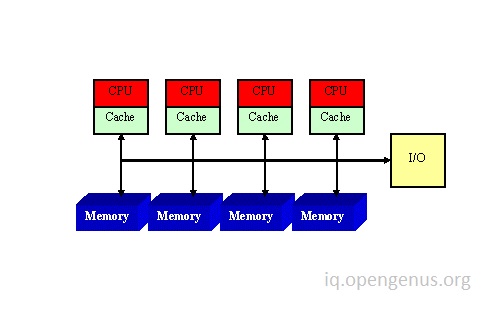
UMA diagram
In Non Uniform Memory Access (NUMA) diagram, each processor has its own local memory. A processor can also have a built-in memory controller as present in Intel’s Quick Path Interconnect (QPI) NUMA Architecture.
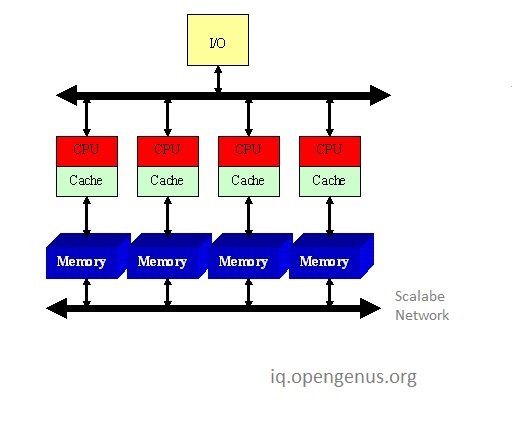
NUMA diagram
Applications
Uniform Memory Access (UMA) and Non-Uniform Memory Access (NUMA) architectures have practical applications in a variety of real-life scenarios, including in industries such as finance, scientific research, and video game development.
UMA architecture is commonly used in systems that require fast and equal access to memory by all processors. This architecture is well-suited for applications that require shared memory, such as scientific simulations and data processing.
One practical application of UMA architecture is in high-performance computing systems used in scientific research. These systems typically consist of a large number of processors that require access to a shared memory pool. UMA architecture ensures that all processors have equal access to the memory pool, which helps to speed up processing times and improve overall performance.
NUMA architecture, on the other hand, is commonly used in systems that require different processors to access different parts of memory. This architecture is well-suited for applications that require large amounts of memory and have a high degree of locality, such as databases and virtualization environments.
One practical application of NUMA architecture is in large-scale databases used in finance and banking. These databases can be distributed across multiple processors, with each processor responsible for managing a subset of the data. NUMA architecture ensures that each processor can access its subset of data quickly and efficiently, which helps to improve overall performance and reduce latency.
Another practical application of NUMA architecture is in virtualization environments, where multiple virtual machines are hosted on a single physical server. NUMA architecture helps to ensure that each virtual machine can access its assigned memory quickly and efficiently, without interfering with the memory access of other virtual machines on the same physical server.
In conclusion, both UMA and NUMA architectures have practical applications in a variety of industries and real-life scenarios. Choosing the right architecture for a particular application depends on factors such as the size of the memory pool, the degree of locality in the application, and the number of processors involved.
Questions and Discussion
Here are some questions to enhance interactivity and scope to test knowledge related to UMA and NUMA architecture:
- What is the main difference between UMA and NUMA architecture?
- In what types of applications is UMA architecture best suited? And in what types of applications is NUMA architecture best suited?
- Can you give an example of a real-world scenario where UMA architecture is used?
- Can you give an example of a real-world scenario where NUMA architecture is used?
- How does the choice of architecture affect the overall performance of an application?
It's important to discuss and share knowledge with other OpenGenus members. Here are some discussion points related to UMA and NUMA architecture:
- Do you think UMA or NUMA architecture is better suited for modern data centers and why?
- How do you think the increasing demand for virtualization and cloud computing is affecting the adoption of UMA and NUMA architecture?
- What are some challenges that arise when designing applications for NUMA architectures?
- Can you think of any other industries or applications that could benefit from UMA or NUMA architecture?
- How do you think future advancements in processor and memory technology will impact the design of UMA and NUMA architectures?
Feel free to share your thoughts and engage in discussion with other OpenGenus members to learn more about UMA and NUMA architecture.
Conclusion
This article at OpenGenus discussed the Uniform Memory Access (UMA) and Non-Uniform Memory Access (NUMA) architectures, their differences, and their practical applications in modern computing systems.
UMA architecture is best suited for applications that require fast and equal access to memory by all processors, while NUMA architecture is best suited for applications that require different processors to access different parts of memory.
Examples of industries that benefit from each architecture were also provided, including scientific research, finance, banking, virtualization environments, and video game development.
Understanding the differences between UMA and NUMA architecture is crucial in designing efficient and high-performance computing systems. The choice of architecture can have a significant impact on the overall performance of an application and should be carefully considered based on the application's requirements.
As technology continues to advance, it's important to stay up-to-date with the latest advancements in processor and memory technology and how they impact the design of UMA and NUMA architectures. By understanding these architectures, we can design more efficient and scalable computing systems that can meet the demands of modern applications.