
Get this book -> Problems on Array: For Interviews and Competitive Programming
Contrastive learning is a method for structuring the work of locating similarities and differences for an ML model. This method can be used to train a machine learning model to distinguish between similar and different photos.
A scoring function, which is a metric that assesses the similarity between two features, can be used to represent the inner workings of contrastive learning.
Unlabeled data points are juxtaposed against one another as part of the machine learning paradigm known as contrastive learning in order to teach a model which data points are similar and which are distinct.
In other words, samples are compared to one another as the name implies, and those that belong to the same distribution are pushed toward one another in the embedding space. Those who belong to various distributions, however, are pushed up against one another.
In computer vision tasks utilizing contrastive pre-training, previous research has demonstrated a significant empirical success. For instance, contrastive approaches trained on unlabeled ImageNet data on a linear classifier were examined by Hénaff et al. in 2019 and found to be more accurate than supervised AlexNet. Similar to this, He et al., 2019, discovered that contrastive pre-training on ImageNet outperformed its supervised pre-training equivalents and effectively transferred to other downstream tasks.
Terminology
A siamese network, also known as a twin network, is trained by encoding two or more inputs and comparing the output properties. There are various ways to compare these two things. Triplet loss, pseudo labeling with cross-entropy loss, and contrastive loss are a few examples of the comparisons.
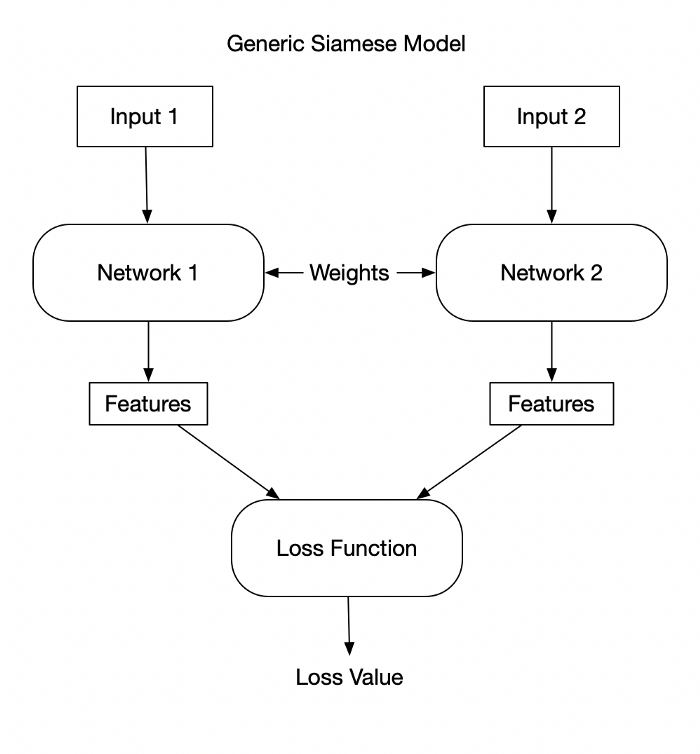
figure: Siamese Network
Contrastive Loss
One of the earliest training goals for contrastive learning was contrastive loss.
It draws similar samples closer together and separates dissimilar samples when given a set of samples that are either similar or dissimilar as input.
To put it more precisely, we assume that we have a pair ((I_i, I_j), I j) and a label Y that is equal to 0 if the samples are comparable and 1 if they are not.
We employ a Convolutional Neural Network f to encode the input pictures I i and I j into an embedding space where x i = f(I i) and x j = f(I j), in order to obtain a low-dimensional representation of each sample.
What constitutes a contrastive loss?
{L = (1-Y) * ||x_i - x_j||^2 + Y * max(0, m - ||x_i - x_j||^2)}
where the lower bound distance between different samples is defined by the hyperparameter m.
There are two scenarios if we examine the aforementioned equation in greater detail:
We minimize the term ||x i - x j||2 that represents the samples' Euclidean distance if they are similar (Y=0). The term max(0, m - ||x i - x j||2), which is analogous to maximizing the samples' euclidean distance up until a certain limit m, is minimized if the samples are different (Y=1).
Triplet Loss
Triplet loss is an enhancement of contrastive loss that outperforms the former by using triplets of samples rather than pairs.
It specifically needs an anchor sample I, a positive sample (I+), and a negative sample (I-) as input.
{L = max(0, ||x - x^{+}||^2 - ||x - x^{-}||^2 + m)}
When training, the loss pushes the anchor sample's distance from the positive sample to be smaller than its distance from the negative sample: When we train a model with the triplet loss, we require fewer samples for convergence since we simultaneously update the network using both similar and dissimilar samples. That’s why triplet loss is more effective than contrastive loss.
Contrastive learning under supervision (SSCL) versus self-supervised contrastive learning (SCL)
When training a model, supervised learning refers to the learning paradigm in which the data and their corresponding labels are both available.
On the other hand, in self-supervised learning, the model creates labels using the unaltered input data.
Due to the lack of class labels in self-supervised contrastive learning (SSCL), positive and negative samples are produced from the anchor image itself using a variety of data augmentation approaches.
All other photos that have been enhanced are regarded as "negative" samples.
These difficulties impede the training of the model. If a dog image serves as the anchor sample, for instance, then only enhanced copies of this image can serve as the positive samples. Dog-related images are consequently included in the group of negative examples.
The reason for this is that, in accordance with the Self-Supervised Learning framework, the contrastive loss function will make the two distinct dog images lie as far apart as feasible in the embedding space.
As a result, Supervised Contrastive Learning (SCL) efficiently utilizes the label information and enables samples of the same distribution to be attracted to one another in the latent space (for example, many photos of various dogs).
As a result, unlike SSCL frameworks, SCL frameworks use different loss functions.
In the part that described the NT-Xent loss function, one such illustration was looked at.
We do not employ any negative samples at all in the field of non-contrastive learning for self-supervised learning, which was inspired by the issues with SSCL that were previously described.
In order to push sample representations that belong to the same distribution closer together in the embedding space, we exclusively use positive examples when training models.
Frameworks for Contrastive Learning
SimCLR
SimCLR, a framework created by Google, advances unsupervised and semi-supervised models for image analysis. This technique for self-supervised representation learning on images not only makes things easier, but also does it more effectively. For instance, it makes great progress toward the SOTA on self- and semi-supervised learning. Additionally, it sets a new benchmark for picture classification by achieving top-five accuracy of 85.8% utilizing just 1% of the tagged photos in the ImageNet dataset.
This approach is straightforward in that it can be quickly integrated into supervised learning pipelines that are already in place. The most recent version, SimCLRv2, which was first described in the study "Big self-supervised models are strong semi-supervised learners," has been made available by Google. Three phases can be used to summarize the semi-supervised learning technique suggested in this study:
Unsupervised SimCLRv2 pre-training of a large ResNet model on a few named examples under supervision. The task-specific information is refined and transferred through distillation using unlabelled instances.
TensorFlow Similarity
A TensorFlow library for similarity learning is called TensorFlow Similarity.
It is also known as contrastive learning and metric learning. The platform provides a SOTA algorithm for metric learning together with all the tools required to study, develop, test, and use similarity-based models.
TensorFlow Similarity offers supervised training and is presently in beta testing.
It intends to support both self-supervised and semi-supervised learning in the upcoming months.
solo-learn
Solo-Learn, powered by PyTorch Lightning, is a library of self-supervised techniques for learning unsupervised visual representations. The library's goal is to offer SOTA self-supervised procedures in a comparable setting while also incorporating training techniques. The models can also be used outside of solo-learn because the library is self-contained.
Implications and Conclusion
ImageNet pre-training has been widely used in computer vision during the past few years. It is advantageous to employ supervised pre-trained networks to provide meaningful representations when data is limited. Contrastive learning shows that even in the absence of labeled data, we can still do reasonably well. Instead, by maximizing the contrastive loss, the enormous amount of unlabeled data can be used to train a strong encoder. Data creation by people is accelerating. It is a significant advancement to be able to use such data without the need for time-consuming and expensive human labeling.
Unsupervised representation learning has already revolutionized disciplines outside of computer vision, such as Natural Language Processing, where models like BERT and GPT that were trained on unlabeled texts dominated practically all benchmarks. It will be interesting to explore if contrastive learning can be used in areas other than computer vision, such as processing high-dimensional medical data or voice recognition.