
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article, we will explain a codebase where the classic Snake Game is developed using Reinforcement Learning. It means the agent/snake learns to move on it's own, avoid the collisions, and eat the food.
Introduction
Reinforcement learning is a machine learning method where an agent learns to act in an environment depending on the rewards and punishments it gets. Using different algorithms, an agent is trained to complete a task without any human interaction.
For this project, we are using Q-learning algorithm. This algorithm is a value based algorithm and it updates the value based on the Bellman equation. This equation calculates the next maximum reward based on a certain action at each state. The goal is to receive the maximum reward.
Our snake will get a +10 as a reward and a -10 as a punishment. The reward is received every time the snake eats the food. The snake gets punished every time it hits any boundaries or itself, which means if any collision occurs. That is how the snake learns to play the game on its own using RL.
Project Description
The project is divided into four scripts. Each script has it's own functionality.
- main.py
- agent.py
- model.py
- plotResult.py
the main file contains the creation of th graphics. It includes the snake, the food, the window, and the boundaries. The agent file trains the snake to perform and connects the functions of other files. The model file contains the Q-learning model we are using for this project. Finally, we present the progress in a chart with the plotResult file.
Run the agent.py file to run the whole project.
Main File
In this file, we are using one class to define all the functions needed for the graphics. We are also adding functions for placing the food, detecting collisions, taking the next step, and moving into that direction. First, we import some necessary libraries and define some constants.
import pygame
import random
from enum import Enum
from collections import namedtuple
import numpy as np
pygame.init()
font = pygame.font.Font('arial.ttf', 25)
class Direction(Enum):
RIGHT = 1
LEFT = 2
UP = 3
DOWN = 4
Point = namedtuple('Point', 'x, y')
# rgb colors
WHITE = (255, 255, 255)
RED = (200, 0, 0)
BLUE1 = (0, 0, 255)
BLUE2 = (0, 100, 255)
BLACK = (0, 0, 0)
BLOCK_SIZE = 20
SPEED = 90
We are using Pygame library for this project. The font file is a separate file, it can be downloaded from the GitHub link in the reference. We initialize the pygame, set the font varibale and the directions.
Using namedtuple, we create the dictionary to define x and y axis of an object. We set the colors, the size of the blocks or the spaces this window will contain, and the speed which can be changed as preferred.
Now we begin to create our game with the SnakeGameAI class.
class SnakeGameAI:
def __init__(self, w=640, h=480):
self.w = w
self.h = h
# init display
self.display = pygame.display.set_mode((self.w, self.h))
pygame.display.set_caption('Snake')
self.clock = pygame.time.Clock()
self.reset()
...
Three dots at the end shows where the next part of code will be.
Here we set the display for the game. The reset function will restart the game after each collision.
def reset(self):
# init game state
self.direction = Direction.RIGHT
self.head = Point(self.w / 2, self.h / 2)
self.snake = [self.head,
Point(self.head.x - BLOCK_SIZE, self.head.y),
Point(self.head.x - (2 * BLOCK_SIZE), self.head.y)]
self.score = 0
self.food = None
self._place_food()
self.frameIteration = 0
...
The reset function starts or restarts the game. The initial direction is set to Right, the axis of the head is calculated, and the snake is created as a list. As we start the game, the score is set to 0, the iteration of the frames is set to 0, and we place a new food.
def _place_food(self):
x = random.randint(0, (self.w - BLOCK_SIZE) / BLOCK_SIZE) * BLOCK_SIZE
y = random.randint(0, (self.h - BLOCK_SIZE) / BLOCK_SIZE) * BLOCK_SIZE
self.food = Point(x, y)
if self.food in self.snake:
self._place_food()
...
With this method, we place a new food at the beginning and after the snake eats the food. We choose the location for the food randomly.
Now, we define the method for the game steps. Based on the snake's action, we move, place a new food, or check if the game is over. We update the display as we go. This action is received from the agent file.
def play_step(self, action):
self.frameIteration += 1
# check for quitting
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
quit()
# move
self._move(action) # update the head
self.snake.insert(0, self.head)
# check if game over
reward = 0
game_over = False
if self.is_collision() or self.frameIteration > 100*len(self.snake):
game_over = True
reward = -10
return reward, game_over, self.score
# place new food or just move
if self.head == self.food:
self.score += 1
reward = 10
self._place_food()
else:
self.snake.pop()
# update ui and clock
self._update_ui()
self.clock.tick(SPEED)
# return game over and score
return reward, game_over, self.score
...
We check if the user wants to quit the program and then move on to the game. We call the functions for changing directions and making the snake move, check if the snake had any collision, place a new food, and update the display.
At the beginning, the score and the reward is set to 0. If the snake faces a collision or it cannot find the food for a very long time, then the game is over. Each game-over sets the reward to -10. The snake needs to avoid getting -10.
Every time the snake eats the food, the score increments by 1 and the reward is set to +10. Then we place a new food. Otherwise, the snake keeps searching for the food.
At the end of this function, we return the reward, score and the game over state to the agent for training.
def is_collision(self, pt=None):
if pt is None:
pt = self.head
# hits boundary
if pt.x > self.w - BLOCK_SIZE or pt.x < 0:
return True
if pt.y > self.h - BLOCK_SIZE or pt.y < 0:
return True
# hits itself
if pt in self.snake[1:]:
return True
return False
...
A collision occurs if the snake hits the walls of the display or its own body. Collisions mean the game is over and it needs to restart.
def _update_ui(self):
self.display.fill(BLACK)
for pt in self.snake:
pygame.draw.rect(self.display, BLUE1, pygame.Rect(pt.x, pt.y, BLOCK_SIZE, BLOCK_SIZE))
pygame.draw.rect(self.display, BLUE2, pygame.Rect(pt.x + 4, pt.y + 4, 12, 12))
pygame.draw.rect(self.display, RED, pygame.Rect(self.food.x, self.food.y, BLOCK_SIZE, BLOCK_SIZE))
text = font.render("Score: " + str(self.score), True, WHITE)
self.display.blit(text, [0, 0])
pygame.display.flip()
...
This method creates the snake, the food, and sets the score text on the window. We are using the display.flip() method because it updates only a portion of the display.
def _move(self, action):
# [straight, rightTurn, leftTurn]
clock_wise = [Direction.RIGHT, Direction.DOWN, Direction.LEFT, Direction.UP]
idx = clock_wise.index(self.direction)
if np.array_equal(action, [1,0,0]):
new_dir = clock_wise[idx] # no_change
elif np.array_equal(action, [0,1,0]):
next_idx = (idx + 1) % 4
new_dir = clock_wise[next_idx] # right turn r -> d -> l -> u
elif np.array_equal(action, [0,0,1]):
next_idx = (idx - 1) % 4
new_dir = clock_wise[next_idx] # left turn l -> u -> r -> d
self.direction = new_dir
x = self.head.x
y = self.head.y
if self.direction == Direction.RIGHT:
x += BLOCK_SIZE
elif self.direction == Direction.LEFT:
x -= BLOCK_SIZE
elif self.direction == Direction.UP:
y += BLOCK_SIZE
elif self.direction == Direction.DOWN:
y -= BLOCK_SIZE
self.head = Point(x, y)
...
We set the direction as a clock-wise motion in a list. The snake will either go straight, or take a right-turn or a left-turn. The action we get from the agent comes in an array; straight = [1,0,0], right-turn = [0,1,0], left-turn = [0,0,1].
We compare these values and find the next move. The modulus 4 makes sure the directions are looping back to the 1st index. Then we calculate the direction the snake moves to. For up and right move, we add the block-size to the axis of the snake-head. For down and left move, we minus the block-size from the axis of the snake-head.
After the display, we build the model for the agent to train on.
Model File
For the model, we will use Pytorch to build the neural network. We will import the libraries needed for this file.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import os
It is a feed-forward neural network with an input layer, a hidden layer, and an output layer. We are creating a class to build the model and save it in the directory.
class Linear_QNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.linear2(x)
return x
def save(self, file_name='model.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.makedirs(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
Pytorch helps us to easily build and save the neural network model using its built-in functions.
We build another class for training the agent with this model.
class QTrainer:
def __init__(self, model, lr, gamma):
self.lr = lr
self.gamma = gamma
self.model = model
self.optimizer = optim.Adam(model.parameters(), lr=self.lr)
self.criterion = nn.MSELoss()
...
We set the learning rate, gamma value for the equation, the model we get from the agent file. We use the Adam optimizer and set the loss function to criterion for error calculation.
Now, we define the training steps.
def train_step(self, state, action, reward, next_state, gameOver):
state = np.array(state, dtype=float)
state = torch.tensor(state, dtype=torch.float)
next_state = np.array(next_state, dtype=float)
next_state = torch.tensor(next_state, dtype=torch.float)
action = torch.tensor(action, dtype=torch.long)
reward = torch.tensor(reward, dtype=torch.float)
if len(state.shape) == 1:
state = torch.unsqueeze(state, 0)
next_state = torch.unsqueeze(next_state, 0)
action = torch.unsqueeze(action, 0)
reward = torch.unsqueeze(reward, 0)
gameOver = (gameOver, )
...
This method is used by the agent for training. It stores the values in float datatype in a multidimension tensor array.
The unsqueez method returns an one dimension array at a specific position. If the state shape is 1 then we insert a dimension to change the shape. The value should be stored in this format, (dim, value).
# predict Q values with current state
pred = self.model(state)
# Bellman equation
# QNew = reward + gamma * max(next_predicted Q value) -> only do this if not gameover
# pred.clone()
# preds[argmax(action)] = QNew
target = pred.clone()
for i in range(len(gameOver)):
newQ = reward[i]
if not gameOver[i]:
newQ = reward[i] + self.gamma * torch.max(self.model(next_state[i]))
target[i][torch.argmax(action[i]).item()] = newQ
self.optimizer.zero_grad()
loss = self.criterion(target, pred)
loss.backward()
self.optimizer.step()
We take the current state and calculate the new Q value for the agent's next move. The prediction of the state has three values. We clone the prediction to have the same amount of values and set this to target.
Now, if our game is not over we calculate the new Q value using the equation. Then we set the target of the maximum value of the action to the new Q value. The target is now the Q-new and pred is Q-old. Then we calculate the loss of these two values.
All the methods are combined in the agent.py file.
Agent File
We need to import libraries and set constants for this file as well.
import torch
import random
import numpy as np
from collections import deque
from main import SnakeGameAI, Direction, Point
from model import Linear_QNet, QTrainer
from plotResult import plot
MAX_MEMORY = 100_000
BATCH_SIZE = 1000
LR = 0.001
We use Pytorch and other classes and methods from other files in this file. We assign maximum meory size, batch size, and learning rate.
Now, we create the Agent class.
class Agent:
def __init__(self):
self.numOfGames = 0
self.epsilon = 0 # randomness
self.gamma = 0.9 # discount rate
self.memory = deque(maxlen=MAX_MEMORY) # pop left most item
self.model = Linear_QNet(11, 256, 3)
self.trainer = QTrainer(self.model, lr=LR, gamma=self.gamma)
...
Here we set the number of games, the randomness, and the gamma value. If the maximum memory is reached, then we delete the last item from the memory stack. In the model, the 11 and 3 values are for the states and actions. We have 11 states for the snake to be and 3 actions(straight, right-turn, left-turn) for the snake to take.
To get the state of the agent, we define a method and return the values as a numpy array.
def get_state(self, game):
head = game.snake[0]
point_l = Point(head.x - 20, head.y)
point_r = Point(head.x + 20, head.y)
point_d = Point(head.x, head.y - 20)
point_u = Point(head.x, head.y + 20)
dir_l = game.direction == Direction.LEFT
dir_r = game.direction == Direction.RIGHT
dir_u = game.direction == Direction.UP
dir_d = game.direction == Direction.DOWN
state = [
# Danger straigt
(dir_r and game.is_collision(point_r)) or
(dir_l and game.is_collision(point_l)) or
(dir_u and game.is_collision(point_u)) or
(dir_d and game.is_collision(point_d)),
# Danger right
(dir_u and game.is_collision(point_r)) or
(dir_d and game.is_collision(point_l)) or
(dir_r and game.is_collision(point_u)) or
(dir_l and game.is_collision(point_d)),
# Danger left
(dir_d and game.is_collision(point_r)) or
(dir_r and game.is_collision(point_l)) or
(dir_l and game.is_collision(point_u)) or
(dir_u and game.is_collision(point_d)),
# Move direction
dir_r,
dir_d,
dir_l,
dir_u,
# Food location
game.food.x < game.head.x, # food left
game.food.x > game.head.x, # food right
game.food.y < game.head.y, # food down
game.food.y > game.head.y # food up
]
return np.array(state, dtype=int)
...
We set the left, right, up, down positions for the snake-head and we also set the directions. To check the state, we check for dangers straight, right-turn, or left-turn, then we check the direction the snake is moving, and the food location. Each of these will return True or False value.
If the snake is moving straight, then we check if the danger will be on the direction to which the snake is moving. If the snake makes a right-turn, then we check based on the direction and turn if it will face a collision. We do the same for the left-turn as well. Only of the values will return True for each danger.
Then we check for the direction and food location. The numpy array converts the True-False values to 0 and 1 and we return the array.
def remember(self, state, action, reward, next_state, gameOver):
self.memory.append((state, action, reward, next_state, gameOver))
def train_long_memory(self):
if len(self.memory) > BATCH_SIZE:
mini_sample = random.sample(self.memory, BATCH_SIZE) #list of tuples
else:
mini_sample = self.memory
states, actions, rewards, next_states, gameOvers = zip(*mini_sample)
self.trainer.train_step(states, actions, rewards, next_states, gameOvers)
def train_short_memory(self, state, action, reward, next_state, gameOver):
self.trainer.train_step(state, action, reward, next_state, gameOver)
...
Now, we store the values in the memory using the remember method. The double parentheses are used for getting the values as one tuple. The leftmost value will be deleted if the memory exceeds its maximum capacity.
The long-memory stores values from multiple game steps or a batch. First, we check if there are samples more than the batch-size. If we do, then we pick random samples of batch-size which is a list of tuples. Otherwise, we take the whole memory.
We use the built-in zip method in python to combine all the states, actions, rewards, next-states, and gameovers. The * is used for separating the values from one single tuple.
The short-memory stores values of only one game step and we only need to call a method from the QTrainer class of the model file. We use this method for storing long-memory values as well.
def get_action(self, state):
# random moves: tradeoff exploration / exploitation
self.epsilon = 90 - self.numOfGames
final_move = [0,0,0]
if random.randint(0, 200) < self.epsilon:
move = random.randint(0,2)
final_move[move] = 1
else:
state0 = torch.tensor(state, dtype=torch.float)
prediction = self.model(state0)
move = torch.argmax(prediction).item()
final_move[move] = 1
return final_move
...
This method returns the action the snake needs to take, which is going straight or turning right or turning left. As we advance with the game, we want our snake to choose moves less randomly. The epsilon value will do that. It will let the game pick random value as long as it is greater than any value between 0 to 200 and the snake will pick a random move.
Otherwise, we predict the state values and pick the maximum from the raw values. We set the index of the maximum value to one for the action.
def train():
plot_scores = []
plot_mean_scores = []
total_score = 0
record = 0
agent = Agent()
game = SnakeGameAI()
while True:
# get old state
old_state = agent.get_state(game)
# get move
action = agent.get_action(old_state)
# perform move and get new state
reward, gameOver, score = game.play_step(action)
state_new = agent.get_state(game)
# train short memory
agent.train_short_memory(old_state, action, reward, state_new, gameOver)
# remember
agent.remember(old_state, action, reward, state_new, gameOver)
if gameOver:
# train long memory and plot result
game.reset()
agent.numOfGames += 1
agent.train_long_memory()
if score > record:
record = score
agent.model.save()
print('Game', agent.numOfGames, 'Score', score, 'Current Record', record)
plot_scores.append(score)
total_score += score
mean_score = total_score / agent.numOfGames
plot_mean_scores.append(mean_score)
plot(plot_scores, plot_mean_scores)
if __name__ == '__main__':
train()
With this training method, we use the other methods to get the state, the action, and store the values in the memory to train the agent. We print the Number of games, Scores and Current Record/ High Score in the console after each session.
If the game is not over, we increase the number of games, store the values, and plot the training graph. For plotting the result, we will need the score and the mean score. We append these values to the list defined before. We get the mean by dividing the total score with the number of games.
Finally we create the file to plot the result.
Plot Result File
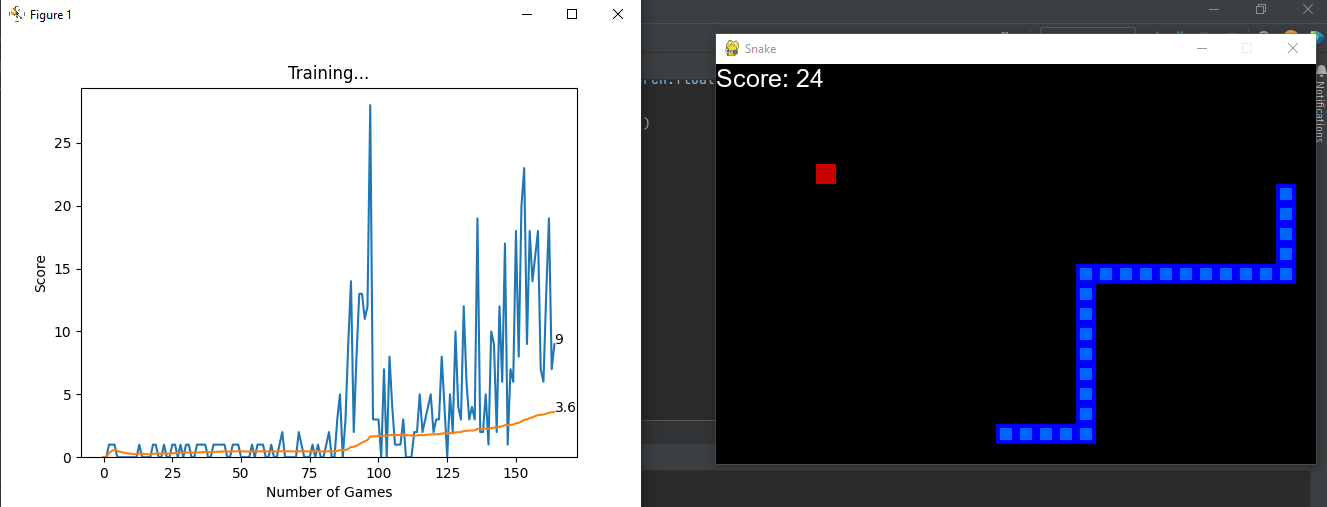
We use matplotlib for plotting the graph for training. ion() method turns on the interactive mode. We receive the scores and mean-scores from the agent and display the graph which shows the change of score as the game continues. This shows the improvement of the snake's performance.
import matplotlib.pyplot as plt
from IPython import display
plt.ion()
def plot(scores, mean_scores):
display.clear_output(wait=True)
display.display(plt.gcf())
plt.clf()
plt.title('Training...')
plt.xlabel('Number of Games')
plt.ylabel('Score')
plt.plot(scores)
plt.plot(mean_scores)
plt.ylim(ymin=0)
plt.text(len(scores)-1, scores[-1], str(scores[-1]))
plt.text(len(mean_scores)-1, mean_scores[-1], str(mean_scores[-1]))
plt.show(block=False)
plt.pause(0.1)
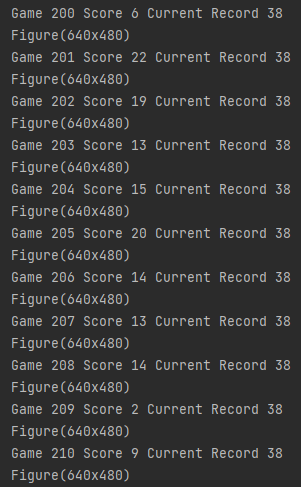
The final result after 200 games,
References
- https://www.youtube.com/watch?v=L8ypSXwyBds&t=1190s
- https://github.com/patrickloeber/snake-ai-pytorch
- Installation link of Pytorch - https://pytorch.org/get-started/locally/
or run - pip3 install torch torchvision