
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article at OpenGenus, we have explored the basics of Trie data structure and how to implement Trie in Java Programming Language from scratch using OOP concepts.
Table of contents:
- What is Trie?
- Structure of Trie
- Why Trie?
- Trie in Java with OOPS Concepts
- Insertion
- Deletion
- Search
- How to use Trie object in Java?
- Complete Java Code
- Applications of Trie
Pre-requisites:
- Trie data structure
- Time Complexity Analysis of Trie
- Trie in C++ using OOP concepts
- Find word with maximum frequency using Trie
What is Trie?
The word "Trie" is taken from word “Retrieval” which means to find, possess or grab. Trie is a multi-way data structure which is based on tree data structure in which data is stored at different nodes and insertion & search operations are performed on them.
It is used to store multiple strings over an alphabet and its capable of storing data in large quantity.
It is also known as digital or prefix tree.
Structure of Trie
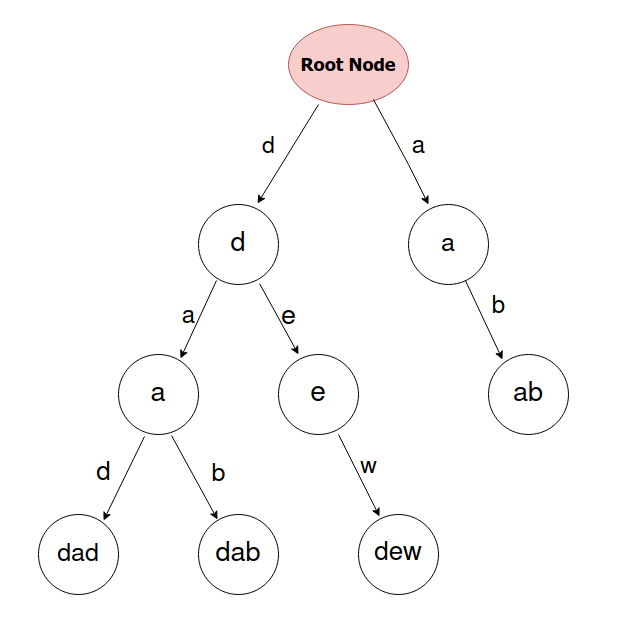
There’s a single root node in every Trie. Every node of the tree represents a string made up of characters along the pathway to the node. Each node contains a hash table or array of pointers with characters represented by different indices. To obtain a complete string, we traverse from the root towards the next possible character in the desired string.
Each node has several properties:
- Value: The character represented by the node.
- Children: A collection of child nodes.
- IsEndOfWord: A boolean value indicating whether the current node represents the end of a word.
The root node has no value but has children representing all possible characters that can start a word. Each child node may have its own children representing the next character in the string.
Why Trie?
While there are various data structures available for storing and retrieving data, not all data structures share the benefits of Trie. For instance, if we consider hash tables, searching a string using a prefix is not a task that can be efficiently performed using hash tables. Only certain tree-based data structures can achieve it.
Moreover, other tree-based data structures require O(n * m) time to search an element with m length of the string and n number of keys in the tree. Yet, a Trie data structure requires O(m) time, which makes it more optimized for searching in large datasets in comparison to other data structures, regardless of whether they are tree-based or not.
Trie in Java with OOPS Concepts
It can be implemented using many languages so in this article at OpenGenus, we have used Java to implement trie with object oriented programming concepts.
Let’s look at the implementation of TRIE.
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
}
class TrieNode {
private final int R = 26;
private final TrieNode[] children;
private boolean isEnd;
public TrieNode() {
links = new TrieNode[R];
}
}
The Trie class has a private instance variable called "root", which is an instance of the TrieNode class. The constructor for the Trie class initializes the root node.
The TrieNode class represents a node in the Trie data structure. It has three instance variables:
- "R" is a constant integer representing the number of possible characters in the alphabet (in this case, 26 for English letters).
- "children" is an array of TrieNode objects, with length R. Each element in this array represents a child node of the current node, corresponding to one of the possible characters in the alphabet.
- "isEnd" is a boolean flag indicating whether or not this node represents the end of a word.
The constructor for the TrieNode class initializes its children array to be an empty array with length R.
There are multiple operations that can be performed in trie data structure, we will perform insertion, deletion and searching in trie.
Insertion
A node is added to the trie which contains a specific character and every node points to the node in the next level and the parent character acts an an index for the child nodes. The string length depicts the depth of the trie.
static void insert(String word)
{
int level;
int length = word.length();
int index;
TrieNode pCrawl = root;
for (level = 0; level < length; level++)
{
index = word.charAt(level) - 'a';
if (pCrawl.children[index] == null)
pCrawl.children[index] = new TrieNode();
pCrawl = pCrawl.children[index];
}
pCrawl.isEndOfWord = true;
}
This code defines a method called "insert" that takes a String parameter called "word". The method is used to insert the given key into a Trie data structure.
The method first initializes two variables: "level" and "length". The "level" variable will be used to keep track of the current level in the Trie while traversing it, and the "length" variable is set to the length of the input key.
Next, the method initializes an integer variable called "index", which will be used to calculate the index of each character in the input key.
The method then initializes a TrieNode object called "pCrawl", which is set to the root node of the Trie.
The method then enters a for loop that iterates through each character in the input key. For each character, it calculates its index using its ASCII value minus 'a'. If there is no child node at that index in pCrawl's children array, it creates a new TrieNode object at that index. It then sets pCrawl to point to this new child node.
After iterating through all characters in the input key, pCrawl's isEndOfWord flag is set to true, indicating that this node represents the end of a word.
Deletion
There are two cases for deletion in trie :
- Word is not present
- Word is present
If its not present, we will stop the search and exit, otherwise we will delete the node.
public void delete(String word) {
deleteHelper(root, word, 0);
}
private boolean deleteHelper(TrieNode current, String word, int index) {
if (index == word.length()) {
if (!current.isEndOfWord) {
return false;
}
current.isEndOfWord = false;
return isEmpty(current);
}
char ch = word.charAt(index);
TrieNode node = current.children[ch - 'a'];
if (node == null) {
return false;
}
boolean shouldDeleteCurrentNode = deleteHelper(node, word, index + 1);
if (shouldDeleteCurrentNode) {
current.children[ch - 'a'] = null;
return isEmpty(current);
}
return false;
}
private boolean isEmpty(TrieNode node) {
for (int i = 0; i < ALPHABET_SIZE; i++) {
if (node.children[i] != null) {
return false;
}
}
return true;
}
The public method takes in a String word as input and calls the private deleteHelper method with the root of the Trie, the word to be deleted, and an index of 0.
The private deleteHelper method takes in a TrieNode current, the word to be deleted, and an index indicating which character of the word is currently being processed.
If the index equals the length of the word, it means that all characters have been processed and we have reached the end of the word. If current.isEndOfWord is false, it means that this node does not represent an actual end-of-word node (i.e., it is just part of another longer word) and we cannot delete it. Otherwise, we set current.isEndOfWord to false to indicate that this node no longer represents an end-of-word node. We then call isEmpty(current) to check if this node has any children nodes left; if not, we can safely delete this node.
If we have not reached the end of the word yet, we get the character at index from the input word and use it to find its corresponding child node in current's children array. If there is no such child node (i.e., node == null), it means that this word does not exist in our Trie and we cannot delete it.
Otherwise, we recursively call deleteHelper on this child node with index incremented by 1. If shouldDeleteCurrentNode is true (i.e., all characters of this word have been processed and there are no more children nodes left), we set current's corresponding child to null (to remove this branch from our Trie) and return isEmpty(current). Otherwise, we return false.
Finally, isEmpty(node) checks if a given TrieNode has any non-null children nodes left; if so, it returns false (meaning that this node still represents part of another word and cannot be deleted), otherwise it returns true (meaning that this node can be safely deleted).
Search
During search, it moves down to the nodes in levels and compares the key with required key of the word, if it exists the isEndofWord field of the last node is true otherwise the search is terminated since the key doesn't exist.
static boolean search(String word)
{
int level;
int length = word.length();
int index;
TrieNode pCrawl = root;
for (level = 0; level < length; level++)
{
index = word.charAt(level) - 'a';
if (pCrawl.children[index] == null)
return false;
pCrawl = pCrawl.children[index];
}
return (pCrawl.isEndOfWord);
}
The method starts by initializing two variables: "level" and "length". The "level" variable is used to keep track of the current level in the Trie, while the "length" variable stores the length of the key.
Next, an integer variable called "index" is declared. This variable will be used to store the index of each character in the key as it is traversed through the Trie.
A TrieNode object called "pCrawl" is initialized with the root node of the Trie. This object will be used to traverse through the Trie as each character in the key is processed.
The method then enters a for loop that iterates through each character in the key. For each character, its index is calculated by subtracting 'a' from its ASCII value. This index is then used to check if there exists a child node at that index under pCrawl. If there isn't, it means that this character does not exist in the Trie and hence, false is returned.
If there exists a child node at that index, pCrawl is updated to point to that child node and processing continues with the next character in the key.
Once all characters have been processed, if pCrawl's "isEndOfWord" flag is set to true, it means that this key exists in the Trie and hence, true is returned. Otherwise, false is returned indicating that this key does not exist in the Trie.
How to use Trie object in Java?
To use the Trie data structure on the client side, a user can create an instance of the Trie class and start inserting words into it. The code provided defines the TrieNode class which represents each node in a trie. Each node has an array of 26 children nodes (one for each letter of the alphabet), a boolean flag to indicate if it is the end of a word, and a constructor to initialize its children array.
The user can perform operations by calling the functions defined in the class.
Trie trie = new Trie(); //initialiazing
//insertion
trie.insert("apple");
trie.insert("orange");
trie.insert("mango");
//search
boolean foundApple = trie.search("apple"); //returns true
boolean foundOrange = trie.search("orange); //returns true
boolean foundGrape = trie.search("grape"); //returns false
//deletion
trie.delete("apple");
trie.delete("orange");
trie.delete("mango");
Rest of the member functions can also be used similarly depending upon their definition and their parameters.
Complete Java Code
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
TrieNode current = root;
for (char c : word.toCharArray()) {
if (!current.containsKey(c)) {
current.put(c, new TrieNode());
}
current = current.get(c);
}
current.setEnd();
}
public boolean search(String word) {
TrieNode node = searchPrefix(word);
return node != null && node.isEnd();
}
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
private TrieNode searchPrefix(String prefix) {
TrieNode current = root;
for (char c : prefix.toCharArray()) {
if (!current.containsKey(c)) {
return null;
}
current = current.get(c);
}
return current;
}
private boolean delete(TrieNode current, String word, int index) {
if (index == word.length()) {
if (!current.isEnd()) {
// Word not found in Trie
return false;
}
current.setEnd(false);
// Delete node if it has no children
return allChildrenNull(current);
}
char c = word.charAt(index);
TrieNode next = current.get(c);
if (next == null) {
// Word not found in Trie
return false;
}
boolean shouldDelete = delete(next, word, index + 1);
if (shouldDelete) {
current.put(c, null);
// Delete node if it has no children
return allChildrenNull(current);
}
return false;
}
private boolean allChildrenNull(TrieNode node) {
for (TrieNode child : node.links) {
if (child != null) {
return false;
}
}
return true;
}
}
class TrieNode {
private final int R = 26;
private final TrieNode[] links;
private boolean isEnd;
public TrieNode() {
links = new TrieNode[R];
}
public boolean containsKey(char c) {
return links[c - 'a'] != null;
}
public void put(char c, TrieNode node) {
links[c - 'a'] = node;
}
public TrieNode get(char c) {
return links[c - 'a'];
}
public void setEnd() {
isEnd = true;
}
public void delete(String word) {
delete(root, word, 0);
}
public boolean isEnd() {
return isEnd;
}
}
Applications of Trie
Autocomplete: Tries can be used to implement autocomplete functionality in search engines, text editors, and other applications. As the user types, the trie can quickly suggest possible completions based on the current prefix.
Spell checking: Tries can be used to implement spell checking algorithms by storing a dictionary of valid words in the trie and checking if a given word is present or not.
IP routing: Tries can be used to store routing tables in network routers for efficient IP address lookup and forwarding.
Text compression: Tries can be used to compress text by storing repeated substrings as pointers to previously stored substrings.
DNA sequencing: Tries can be used to store and search for DNA sequences in bioinformatics applications.
Symbol table: Tries can be used as a symbol table in compilers and interpreters for programming languages.
Predictive text input: Tries can be used to predict the next word or phrase based on previous input in messaging apps or virtual assistants.
Huffman coding: Tries can be used to implement Huffman coding, a lossless data compression algorithm that assigns shorter codes to more frequently occurring characters or symbols.
Game AI: Tries can be used to represent game trees and search for optimal moves in games like chess or Go.
Network security: Tries can be used to detect patterns of malicious traffic or attacks in network security applications.