
Get this book -> Problems on Array: For Interviews and Competitive Programming
The random forest algorithm is also known as the random forest classifier in machine learning. It is a very prominent algorithm for classification. One of the most prominent fact about this algorithm is that it can be used as both classification and random forest regression algorithm.
Why Should We Use Random Forest
Some of its advantages and important features why we use the Random forest Algorithm in machine learning.
- Random forest algorithm is suitable for both classifications and regression task.
- It gives a higher accuracy through cross validation.
- Random forest classifier can handle the missing values and maintain the accuracy of a large proportion of data.
- If there are more trees, it doesn’t allow over-fitting trees in the model.
- It has the ability to work upon a large data set with higher dimensionality.
When should we use Random Forest ?
There are many domains where Random Forest Analysis can be used.
Some major Applications of Random Forest in different sectors:
-
Banking Industry
- Credit Card Fraud Detection
- Customer Segmentation
- Predicting Loan Defaults on LendingClub.com
-
Healthcare and Medicine
- Cardiovascular Disease Prediction
- Diabetes Prediction
- Breast Cancer Prediction
-
Stock Market
- Stock Market Prediction
- Stock Market Sentiment Analysis
- Bitcoin Price Detection
-
E-Commerce
- Product Recommendation
- Price Optimization
- Search Ranking
We will address some of the sectors where it is possible to apply random forests. When random forest analysis comes into effect, we can also look closer.

Banking Industry:
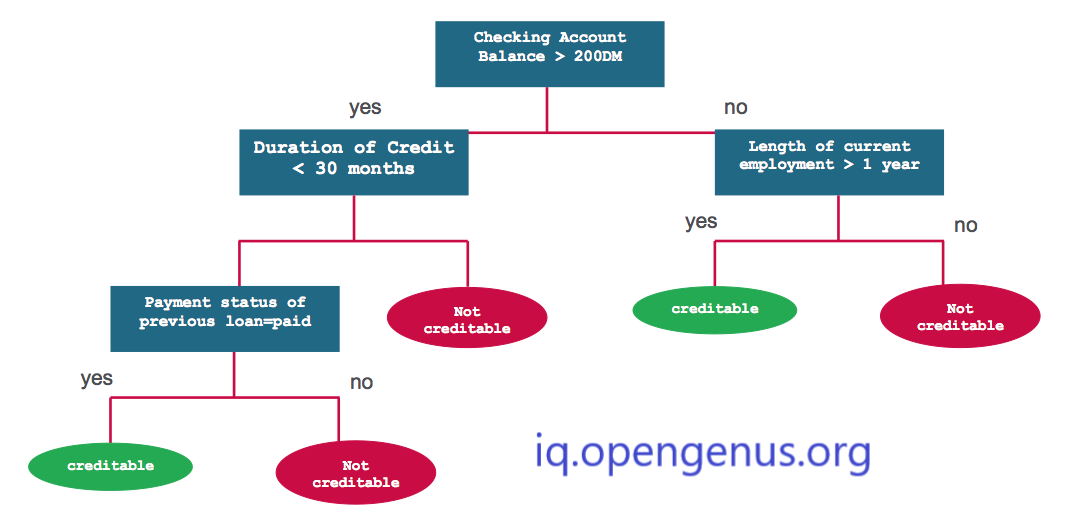
Granting of banking facilities are of great importance economically. Because increasing the quantity of capital cause the growth and development of economy. Most consumers consist of the banking sector. There are many clients that are loyal and even clients of fraud. Random forest analysis comes in to decide whether the client is a loyal or dishonest one. With the aid of a random forest machine learning algorithm, we can easily decide if the client is dishonest or loyal. A framework uses a random collection of algorithms that classify the transactions of fraud by a series of patterns.
Some applications of Random Forest in Healthcare and Medicine:
Credit Card Fraud Detection:
Credit card companies should detect fraudulent credit card purchases so that consumers are not charged for products they have not purchased. However it is an exceedingly difficult task as there could be only 1000 cases of fraud in over a million transactions, representing a mere 0.1 percent of the dataset, resulting in highly imbalanced datasets. When trained with imbalanced datasets, the ML algorithms are very likely to create inaccurate classifiers as they appear to show a preference towards the majority class, treating the minority class as a noise in the dataset. Also because of the "accuracy" class imbalance, there is no meaningful metric for unbalanced classification. Almost all cases belonging to the majority class could be predicted by the algorithm, which would yield a high accuracy score. We can still use the Random Forest Classifier for this.
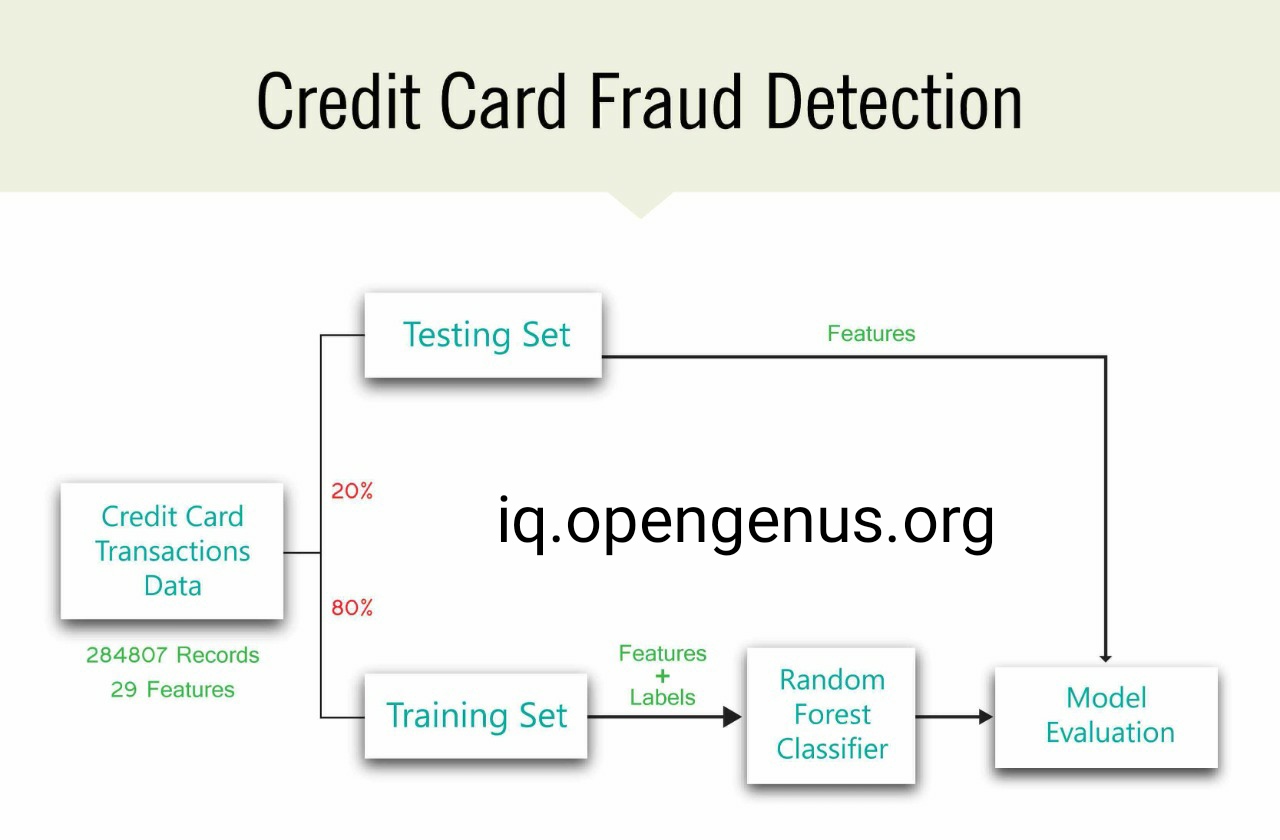
For the complete implementation of Credit Card Fraud Detection check outMy Github Repo
-
Customer Segmentation:
In this, we analyse data on the annual expenditure amounts of different customers (reported in monetary units) of various product categories for internal structure. One purpose of this is to better explain the heterogeneity in the various types of customers with which a wholesale dealer interacts. Doing so will provide the distributor with insight into how their distribution programme can better be configured to suit each client's needs.
Based on their income levels, the Random Forest Algorithm was applied to US Census data for segment clients. The algorithm was applied to 16,000+ data rows with 14 characteristics (a combination of qualitative and quantitative factors). The predictive accuracy of the model on the test set (20% randomly selected data from the dataset) is around 85%.
For the complete implementation of Customer Segmentation check out My Github Repo
-
Predicting Loan Defaults on LendingClub.com:
LendingClub is a peer-to-peer lending company in the USA and the world's largest platform for peer-to-peer lending. To predict the likelihood that a loan on LendingClub will charge off (default), we create machine learning models. Such models could help investors in LendingClub make better-informed investment decisions.
We only use characteristics that are known to investors in training the models before they choose to invest in the loan. Among other items, these features include the income of the borrower, FICO score, and debt-to-income ratio, and the number, intent, rating, and interest rate of the loan.
The modelling process takes several steps, including: eliminating loan features that are or are not known to investors with substantial missing data; exploring, transforming, and visualising the data; creating categorical function dummy variables; and fitting models. To combine imputation, standardisation, dimensional reduction, and model fitting into one pipeline entity, we use machine learning pipelines. Through a cross-validated grid scan, we can optimise hyperparameters.
We may observe that the Random Forest model performs substantially well on the training data according to cross-validated AUROC scores.
For the complete implementation of Predicting Loan Defaults on LendingClub.com check out My Github Repo
Healthcare and Medicine:
Medicines needs a complex mixture of particular chemicals. Therefore, Random forest can be used to recognize the great mix in the medicines. It has become easier to detect and predict the drug sensitivity of a medication with the aid of a machine learning algorithm. It also aids in recognizing the condition of the patient by reviewing the medical record of the patient.
The increasing number of machine learning applications in medicine enables us to glimpse into a future where hand-in-hand data, analysis, and innovation work to help countless patients without ever realizing it. Soon, in multiple countries, it will be quite common to find ML-based applications embedded with real-time patient data available from various healthcare systems, thereby increasing the efficacy of new treatment options that were previously unavailable.
Some applications of Random Forest in Healthcare and Medicine:
-
Cardiovascular Disease Prediction:
Cardio Catch Diseases is a company that specializes in detecting heart disease in the early stages. Its business model is service type, that is, the company offers an early diagnosis of cardiovascular disease for a certain price.
Currently, the diagnosis of cardiovascular disease is made manually by a team of specialists. The current accuracy of the diagnosis varies between 55% and 65%, due to the complexity of the diagnosis and also the fatigue of the team who take turns to minimize the risks.
Thus preventing Heart diseases has become a nessesity . Good data-driven heart disease prediction systems can enhance the whole process of research and prevention, ensuring that more people can live healthy lives.. This is where Machine Learning comes into play. Machine Learning helps in predicting the Heart diseases, and the predictions made are quite accurate.We can train our prediction model by analyzing existing data because we already know whether each patient has heart disease. This process is also known as supervision and learning. To predict if users suffer from heart disease, the trained model is used.
The classification model best suited for this is Random Forest Classfier
For the complete implementation of Cardiovascular Disease Prediction check out My Github Repo
-
Diabetes Prediction :
Diabetes is a type of metabolic disease caused by a lack of insulin due to the pancreas malfunctioning. Diabetes can push a person into pathological destruction of pancreatic beta cells, coma, cardiovascular dysfunction, renal and retinal failure, joint failure, sexual dysfunction, pathogenic effects on immunity, weight loss, and peripheral vascular diseases. A robust framework was therefore proposed for the early detection of diabetes, where outlier rejection, missing values, data standardisation, K-fold validation, and various Machine Learning (ML) classifiers were filled out. Random Forest performs best in this, among all classifiers.
After having Pima Dataset, we preprocess the data such as outlier rejection, missing values filling, standardisation of data, and reduction of attribute dimensionality. For model selection and error estimation of classifiers, the 5-fold Cross-Validation method is used after preprocessing. To train and fine-tune the hyper-parameters in the inner loop, the 4 folds and grid search algorithms were used, while the remaining fold was used to test the model. Random Forest is implemented after such processing.
For the complete implementation of Diabetes Prediction check outMy Github Repo
-
Breast Cancer Prediction :
According to the Centers for Disease Control and Prevention (CDC), breast cancer is the most common form of cancer for women, regardless of race and ethnicity (CDC, 2016). Around 220,000 people are diagnosed with breast cancer in the United States every year (CDC, 2016). Although we may not be aware of all the variables that contribute to breast cancer growth, some characteristics such as family background, age, obesity, alcohol and tobacco use have been established in scientific studies on this topic.
In order to explore the possibility of predicting the type of breast cancer (malignant or benign) from the breast mass characteristics calculated from digital images, we use Machine Learning. These cases are cases diagnosed with a certain type of tumour, but only a few of them (approximately 37%) are malignant. Through this, we analyse the available data and try to predict the probability of a breast cancer diagnosis being malignant or benign based on the attributes obtained from the breast mass.
The following steps are defined in order to accomplish this objective:
- Download the data from the UCI repository for breast cancer images. Familiarize with the data by looking at its shape, the relationships between variables, their potential similarities, and other dataset attributes.
- Use Random Forest Classifier to predict the data with different sets of training samples.
- Break the data into testing and training samples. The training set in size will decrease until the best predicting model is defined to see what is the limit for this classifier to best predict these results. Compare the classifier associated with the assessment metric defined at the start of the project.
For the complete implementation of Breast Cancer Prediction check outMy Github Repo
Stock Market:
In assessing the stock market, machine learning also plays a role. The behavior of the stock market can be analyzed with the help of the Random Forest algorithm. The expected loss or profit that can be generated while purchasing a particular stock can also be illustrated.
Some applications of Random Forest in Stock Market:
-
Stock Market Prediction :
Stock market forecasting is a way to estimate future inventory costs. Day by day, stock prices are dynamic, so it is difficult to determine the best time to buy and sell stocks. It has long been an enticing topic for researchers and investors since its inception. A broad variety of algorithms are generated by Machine Learning, among which Random Forest has been reported to be very successful in predicting future stock prices. Random Forest algorithms have been used for data mining to forecast stock market prices for the NSE stock market.
Stock Market Analysis and Prediction is a project using data provided by Google Finance for technical analysis, visualisation, and prediction. By looking at stock market details, particularly some giant technology stocks and others. Pandas are used to obtain stock details, imagine various aspects of it and finally look at a few ways to assess a stock's risk based on its previous performance history. Future stock values expected by a Monte Carlo technique!
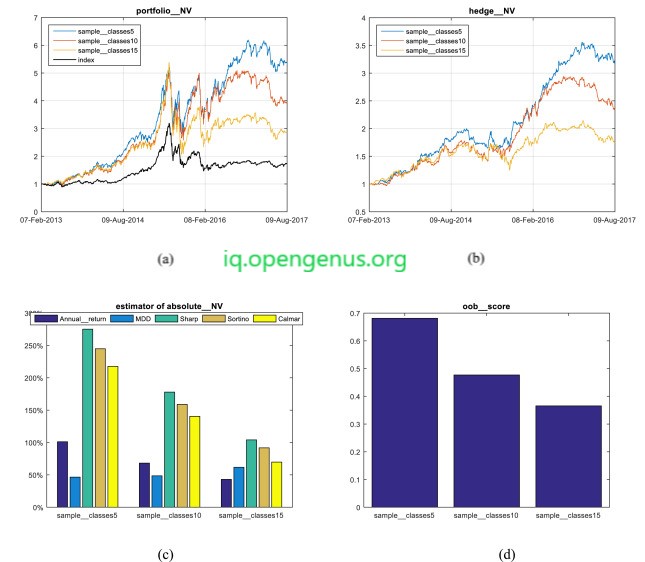
For the complete implementation of Stock Market Prediction check out My Github Repo
-
Stock Market Sentiment Analysis :
Due to the underlying nature of the financial domain and partly due to the combination of established parameters (Previous Days Closing Price, P/E Ratio, etc and unknown variables (such as election results, rumours, etc.), stock prices are considered to be very competitive and prone to rapid changes. An intelligent investor will forecast the stock price and buy a stock before the price rises or sell it before the price rises. Although the knowledge acquired by an experienced trader is very difficult to substitute, an effective prediction algorithm will lead directly to high profits for investment firms, implying a direct correlation between the accuracy of the prediction algorithm and the profit generated from the algorithm's use.
Identification of patterns in a company's stock prices by doing fundamental company research. News articles are given to the model as training data sets that categorised the articles as positive or neutral. The sentiment score in the news article is determined by measuring the difference between positive and negative terms. There were similarities between the real stock prices and the sentiment ratings. The results of the model using Weka are observed using Random Forest algorithms.
For the complete implementation of Stock Market Sentiment Analysis check out My Github Repo
-
Bitcoin Price Detection :
There is no doubt that there is some link between Bitcoin (BTC) and the overall crypto market with the stock market, with market analysts noticing that Bitcoin has been surging for a while in comparison with conventional markets. In order to study the seeming similarity of both economies, thorough analysis has already been undertaken by industry experts.
Cryptocurrencies are digital currencies that in the financial markets have attracted considerable investor interest. The purpose of this project is to predict the daily price, in particular the cryptocurrency Bitcoin's daily closing price. In making trading decisions, this plays a crucial role. There are various variables that influence the price of Bitcoin, making price forecasting a dynamic and technically challenging activity. The random forest model was trained on the historical time sequence, which is Bitcoin's past prices for many years, to perform prediction. In order to predict the closing price, features such as the opening price, highest price, lowest price, closing price, Bitcoin value, currency volume and weighted price of the next day were taken into account.
On both pyspark and scikit, random forest model built and implemented learning frameworks to construct predictive analysis and evaluated them by computing different measures on test data such as RMSE and Pearson's correlation coefficient. In training the random forest to handle big data, the Pyspark system was used to parallelize the development of trees.
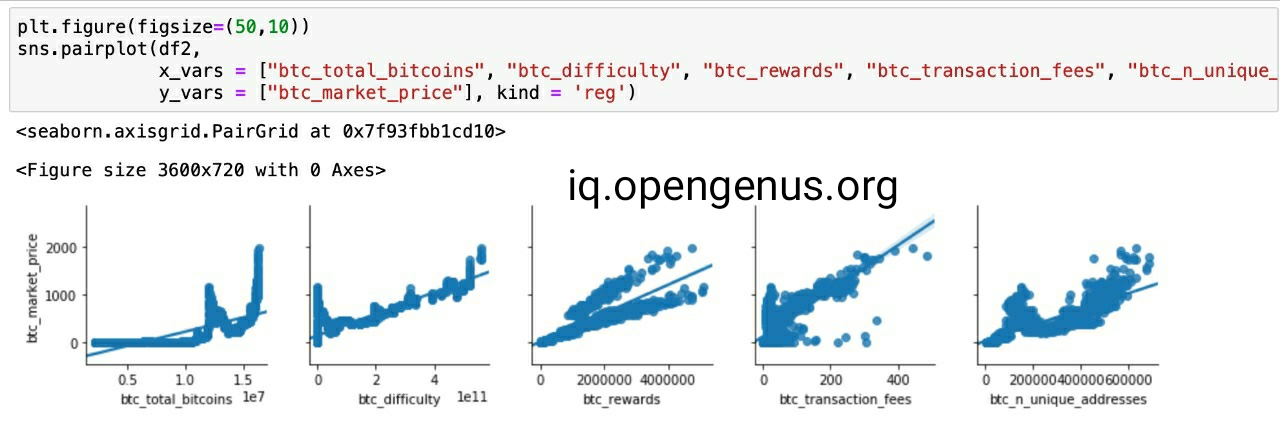
For the complete implementation of Bitcoin Price Prediction with Scikit-Learn using Random Forest check out My Github Repo
E-Commerce:
It's difficult to recommend or suggest what kind of things the consumer should see. This is where a random algorithm in the forest can be used. To recommend products that a customer is more likely to have, you can use a machine learning system. Using a certain template and following the interest of a client in the product, you can sell similar products to your clients.
-
Product Recommendation :
Amazon has shown that reviews for goods work. 35% of its sales are accounted for their Recommendation Engine. But identifying the correct trends in product sales and shopping behaviour requires a lot of computational power.
It can be achieved by machine learning. "If this, then that" rules can be written by a smart employee, but this restricts guidelines to only show the expertise of the employee. Machine learning can quantify purchasing behaviour over and over again seamlessly, each time digging deeper into patterns. Recommending what your clients didn't know they wanted is powerful.
Random Forest has been implemented to construct a recommendation framework. The key assumption is that the higher the review score for a certain consumer is the more likely it is to be recommended for the post. To build a more logical and efficient scheme using MSE for the score and Confusion Matrix for recommendation or not, model performance is assessed. The time factor is considered as a threshold function, say, if the time model dependent score is below three, we will reject our recommendation. This will prohibit us from recommending to our clients nice yet obsolete goods. For users who do not have any records in the database, this model is also helpful: we can only suggest trendy items to them.
For the complete implementation of Product Recommendation check out My Github Repo
-
Price Optimization :
Pricing is essential. Pricing online is absolutely critical. In order to win the deal, you can't just rely on a fixed markup rate or even the local market price. It is easier than ever to compare rates with only a few clicks from one rival to another. And shoppers don't fear having a great price.
In order to account for several variables at once, machine learning technology can adjust prices. The rates, demand, time of day and type of customer of your competitors could all affect your price. The technology of machine learning makes it possible to change prices accordingly.
Getting dynamic pricing that wins sales every time is important.
-
Search Ranking :
If you can't find what your shoppers are looking for, they won't be able to buy it. We could be too spoiled by the search engine of Google to realise that not all searches are smart. But product searches frequently fall short of producing outcomes that really answer the question.
In providing the optimal search results, variables such as material, interests, and similar items all play their part. Machine learning, rather than just keywords, will pull data from deep within the search and purchase trends.
Showing your customers exactly what they want is powerful.