
In this article, we will be walking through the concept behind Bellman's Optimality equation, and how it is used in the case of Reinforcement Learning.
Bellman's equation for deterministic environmentBellman’s optimality equation:
Bellman’s equation is one amongst other very important equations in reinforcement learning.
As we already know, reinforcement learning RL is a reward algorithm that tries to enable an intelligent agent to take some actions in an environment, in other to get the best rewards possible – it seeks to maximize our long-term rewards.
The bellman’s equation seeks to estimate whether actions taken was able to really return the maximum rewards as expected, in other words, it tries to hint us the kind of rewards we could expect if we take certain best actions now based on our present state, and if we continue with such actions in the future steps.
For the deterministic environment, bellman’s equation can be viewed thus:
- The max_a function tries to choose actions that will get the maximum rewards.
- The discount rate γ,is basically a hyper-parameter which helps in adjusting and suiting our decisions process, it shows how valuable the rewards will be for the long-term or for the short-term; hence it guides the agent on whether to focus on long or short-term rewards.
- The rest part of the quation centers on calculating the rewards.
The bellman’s equation is a recursive type - calls itself during execution of the commands; that is, it repeats actions so many times before giving out the desired output.
Summary for the deterministic equation:
A Step is taking, resulting to an action, the action leads to a new state, new state gives a new reward and an episode ends….at this point, we backtrack – we apply the discount factor γ , then we utilize the max_a function to choose actions that gave us the maximum rewards, then we calculate the rewards using the R(s,a) function ”
Important terminologies used herein:
Policy π = this tells the agent what best action to taking in a given state or situation.
Value function:
– this seeks to estimate how suitable is it for an agent to be in a particular state, and how appropriate the action of an agent best suits a given state or situation. From here, we can see that the way an agent tends to act, in directly influenced by the policy it is following, consequently, the value function is defined with respect to the policies. **Discounted return**: This is intended to take rewards that comes first in the short term, and not having to wait for cumulative future reward to be returned. It concerns itself with returns that falls within the discount rate γ– values from 0 – 1. It helps to converge our returned rewards within a chosen range of the discount rate/factor. let's review the relationships on how the returns at successive time steps are related to each other:Hence , we can see that -
Let’s now look into how to derive the Bellman’s Optimality Equation:
Proof of Bellman’s Equation
; where E is the expectation, Rt = the return in time state, s t = the state in time,
G t = return of reward =
and
Now considering Gt,
Hence,
meaning – the expectation of the returns, given the time state St = state SIllustrative Diagram
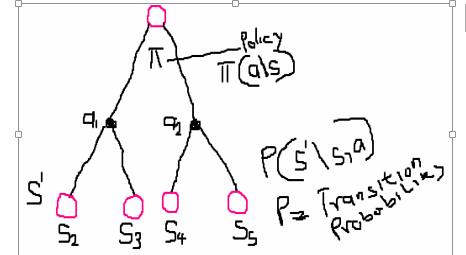
Note: a\s = action, given the very state.
What happens here is this:
The agent starts at a state s, follows a policy π, takes an action a, and goes into a new state s'.
The probability of the agent taken an action using a policy =
The probability of taken the next action in the new state
Where P is a transitional probability – and it is environment dynamic.
Likewise, the probability of moving from S to S5 taken action a2:
furthermore, the probability of moving from S to any of the action S' is:
Our value function is :
Now substituting for P into the value function;
Now considering the expectation and taking E inside the equation, we get
Going further, we know that –
Consequently, Bellman’s equation for policy π, can then be written as:
Furthermore, we know that:
Finally, this leads to Bellman’s optimal equation -
We could also look at this from the Q – function perspective –
Therefore, Bellman’s Equation using Q-function –
From the insight rendered thus far, there is no doubt you have gotten an idea behind the Bellman's Optimality equation, and how it is used in the case of Reinforcement Learning. Thank you for enjoying this article at OpenGenus.